







http://blog.csdn.net/xiaofei_hah0000/article/details/8993617
为什么需要缓存呢?
很简单的道理,拿QQ做个比方,每天有几亿用户登录、查询个人信息,且这些信息基本不会变化,如果你是架构师,你会选择全部从数据库中查询么,估计会被笑的。
一些业务要求大量且高速查询的,数据库必然会成为瓶颈,虽然可以通过横向扩容的方式优化,但这不是最优方案,其实服务器优化没有一个放之四海而皆准的最优方案,业务不同,最优方案也不同。
举个例子,腾讯有十几亿用户,就光登录就是个头疼的事,做架构的往往要朝最坏的地方想,比如所有用户同时登录怎么办,难道要像12306那样直接不理你呢?
这样的业务其实并不复杂,却只有一个追求:高速响应,因为用户是用脚投票的。
这些信息都是存放在数据库中的,最终都要和数据库交互,我们用图来显示一次登录的周期:
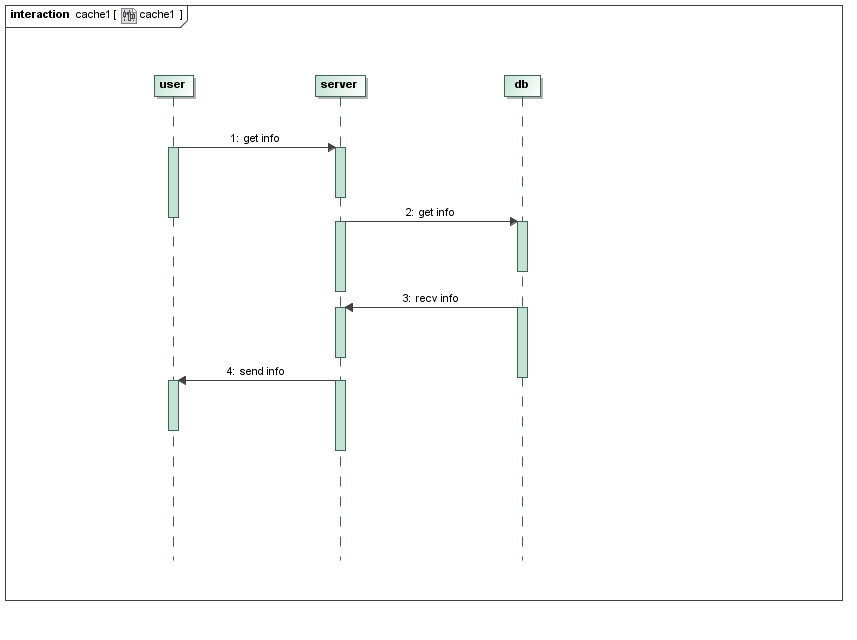
如果一个用户频繁的登录,注销,服务器是不是总要重复这个周期呢,当然不用,第二,三步取了的数据完全可以放在内存中,周期变成这样:
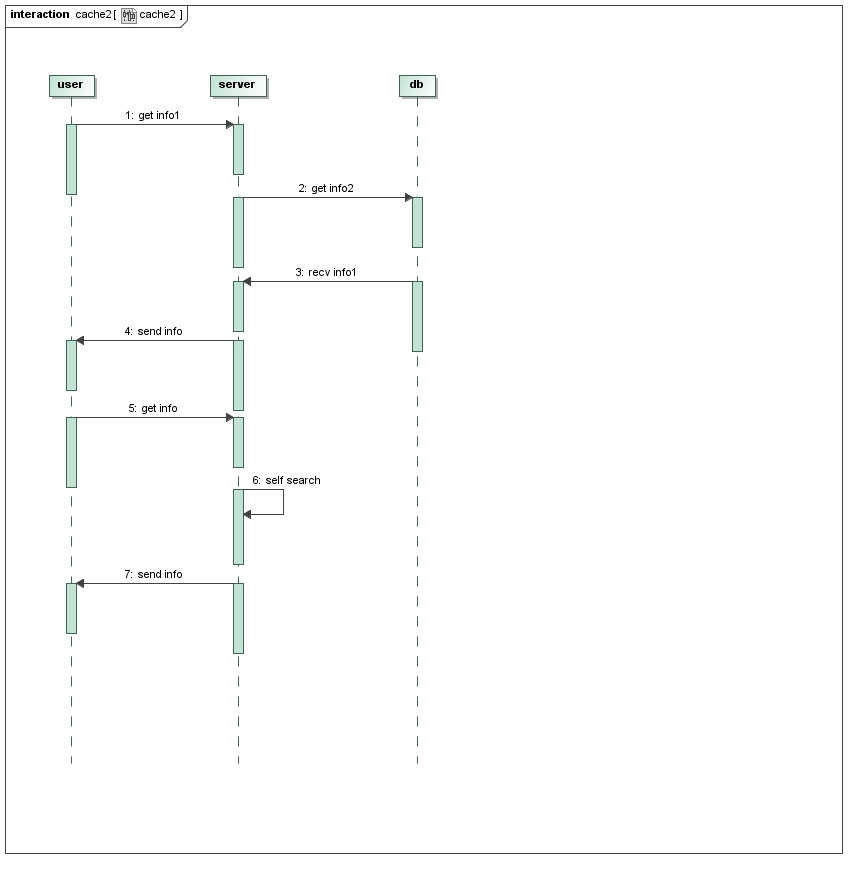
可以看到当第5步再次请求后,系统已经没有了查询数据库的过程。
这时候缓存就粉末登场了,就是适当的时候要用些内存来代替硬盘,很简单,内存和硬盘的速度不在一个层次上,只要花些money就可以了。
如何设计缓存呢?
缓存是占内存的,但不是以花尽内存为追求,尼玛,要是哪个架构这么想的,那就是太坑老板了。
相反缓存追求的就是尽量少占内存,这和开头说要占内存不矛盾,因为终极追求是高效,把红管子换成土黄色(请看 “内存池的设计” )。
每一个缓存的方案其实都是一个平衡:快速索引与内存空间,既使你毫不在乎内存的占用,这个平衡还是存在。
缓存方案又分为索引方案、存储方案、排序方案,三者往往是分不开的,在一类业务数据里找出唯一的KEY其实很容易,难的是如何建立索引,如果用标准库自带的map,红黑树方案,这只是解决了存储方案,如果KEY是20个字节,咱顺便也打算用std::string自带的比较函数,好吧,我承认咱找到了一个通用的方案,且这么认为吧。
还是拿QQ为例,QQ号是9位数的数字,如果把这个数字定义成一个int型的,做为数组的基标,把数据全放进这样的数组中,理论上完全可以,那么要多大的内存去存储呢,假设每个用户128字节的信息量,那么就要2^7*2^32=512G,好吧,咱实实在在的坑了回老板。
现实中,不是所有的数据都要放在缓存中,比如有些QQ一年都不登录一下,还有放进缓存的必要么。
对于大量的数据,在需要考虑内存的时候,缓存中应该只存放频繁用到的数据,像女人一样,要保持常鲜才是最美的。
频繁度就是一个阈值,实际就是我们的经验值。
再举一个实际碰到的例子,key是32个字节的,如果用字符串的比较函数,性能上比较憋屈。可以将32字节换成8个int型或者4个long long型,因为CPU可以直接对两个整型进行比较。
实际开发中,我将32字节的key分成了8个int,将所有的缓存数据按模分类分级,先定义中间容器的结构:
- typedef struct yumei_cache_container_s yumei_cache_container_t;
- struct yumei_cache_container_s
- {
- int container_num;
- int data_num;
- yumei_cache_container_t *container;
- void *data;
- int mm[0];
- };
typedef struct yumei_cache_container_s yumei_cache_container_t;
struct yumei_cache_container_s
{
int container_num;
int data_num;
yumei_cache_container_t *container;
void *data;
int mm[0];
};
容器中套有容器,是为了分级散列,对数据的分级散列是很个很不错的方法,可以提高精度,节省时间。
再定义索引数据的结构:
- typedef struct yumei_cache_map_data_s yumei_cache_map_data_t;
- struct yumei_cache_map_data_s
- {
- int key[8];
- int times;
- int start_time;
- void* data;
- yumei_cache_map_data_t* next;
- };
typedef struct yumei_cache_map_data_s yumei_cache_map_data_t;
struct yumei_cache_map_data_s
{
int key[8];
int times;
int start_time;
void* data;
yumei_cache_map_data_t* next;
};
times是指这个数据被查询过多少次,start_time 则是开始查询时间,这两个参数是为了新陈代谢用的,比如一个数据在昨天天被查了30次,times=30,在昨天会被当
成频繁数据加到缓存里,但是今天一次都没有查过,这样的数据就要被淘汰出去。
定义完了数据结构,就剩下算法了,主要推荐两种:
1.红黑树
2.hash map
C里用的红黑树比较多,另一些语言比如JAVA,Phthon用的 hash map较多,两者各有优点。
红黑树的查询速度不见得会比 hash的快,但是会很稳定,后面文章我再讲一下吧。
架构设计讲求透明性,上面定义的这些结构是对外不可见的,对外的文件接口应该是这样:
- int yumei_cache_module_init();
- int yumei_cache_module_release();
- int yumei_cache_insert( int *key, void* data );
- int yumei_cache_get( int* key, void** data );
- int yumei_cache_del( int* key );
int yumei_cache_module_init();
int yumei_cache_module_release();
int yumei_cache_insert( int *key, void* data );
int yumei_cache_get( int* key, void** data );
int yumei_cache_del( int* key );
在模块内部定义一个全局变量就可以了。
如果追求通用性,则需要重新定义接口:
- typedef struct yumei_cache_s yumei_cache_t;
- struct yumei_cache_s
- {
- void* container;
- };
- #define YUMEI_CACHE_ERROR -1
- #define YUMEI_CACHE_OK 0
- #define YUMEI_CACHE_KEY_EXIST 1
- #define YUMEI_CACHE_KEY_NOT_EXIST 2
- yumei_cache_t* yumei_cache_create();
- int yumei_cache_close( yumei_cache_t* cache);
- int yumei_cache_insert( yumei_cache_t* cache, int* key, void* data );
- int yumei_cache_get( yumei_cache_t* cache, int* key, void** data );
- int yumei_cache_del( yumei_cache_t* cache, int* key );
typedef struct yumei_cache_s yumei_cache_t;
struct yumei_cache_s
{
void* container;
};
#define YUMEI_CACHE_ERROR -1
#define YUMEI_CACHE_OK 0
#define YUMEI_CACHE_KEY_EXIST 1
#define YUMEI_CACHE_KEY_NOT_EXIST 2
yumei_cache_t* yumei_cache_create();
int yumei_cache_close( yumei_cache_t* cache);
int yumei_cache_insert( yumei_cache_t* cache, int* key, void* data );
int yumei_cache_get( yumei_cache_t* cache, int* key, void** data );
int yumei_cache_del( yumei_cache_t* cache, int* key );
有了这些只是提供了正常缓存的功能,别忘了我们还要追求内存少浪费,就要保持数据的常鲜,还得定时去代谢那些老数据,这样就得要做到四点:
1.数据库存放的数据都是有状态的。
2.从数据库中查询的数据需要有最近的访问时间和访问次数。
3.缓存中的数据要和数据库中打通。
4.提供定时代谢的规则。
相应的缓存过程是这样的:
当用户查询数据,首先在缓存中寻找,缓存中不存在,则去数据库中查找,并更新数据库的访问时间和访问次数,当访问次数达到缓存要求则将其放进缓存中。
系统定时对缓存清除一些满足代谢规则的数据,这个规则是访问时间、访问次数、系统容量的一个权衡。
上面的接口就要改成这个形式:
- int yumei_cache_insert( int *key, void* data, int times, int start_time );
- int yumei_cache_check();
int yumei_cache_insert( int *key, void* data, int times, int start_time );
int yumei_cache_check();- int yumei_cache_insert( yumei_cache_t* cache, int* key, void* data, int times, int start_time );
- int yumei_cache_check( yumei_cache_t* cache );















 43
43

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









