







地址:
7 posts in total
2022
06-14Deobfuscating Javascript via AST: A Peculiar JSFuck-esque Case
06-04Deobfuscating Javascript via AST: Removing Dead or Unreachable Code
05-31Deobfuscating Javascript via AST: Replacing References to Constant Variables with Their Actual Value
05-28Deobfuscating Javascript via AST: Constant Folding/Binary Expression Simplification
05-28Deobfuscating Javascript via AST: Converting Bracket Notation => Dot Notation for Property Accessors
05-22Deobfuscating Javascript via AST: Reversing Various String Concealing Techniques
05-21
Introduction
Welcome to the first article in my series about Javascript deobfuscation. I won’t be going in-depth regarding practical deobfuscation techniques; that’ll be reserved for later articles. Rather, this post serves as a brief overview of the state of Javascript obfuscation, different methods of analysis, and provides resources to learn more about reverse engineering Javascript.
What is Obfuscation?
Definition
Obfuscation is a series of code transformations that turn human-readable code into something that is deliberately difficult for a human to understand, while (for the most part) still maintaining its original functionality. Code authors may choose to obfuscate their code for many reasons, including but not limited to:
- To make it harder to modify, debug, or reproduce (e.g. some javascript-based games or programs)
- To hide malicious intent (e.g. malware)
- To enhance security, i.e obscuring the logic behind javascript-based challenges or fingerprinting (e.g. ReCAPTCHA, Shape Security, PerimeterX, Akamai, DataDome)
Example
For example, the obfuscation process can convert this human-readable script:
1 | JS |
Into something incomprehensible to humans:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 | JS |
Yet, believe it or not, both of these scripts have the exact same functionality! You can test it yourself: both scripts output
1 | EBNF |
to the console.
The State of Javascript Obfuscation
There are many available javascript obfuscators, both closed and open-source. Here’s a small list:
Open-Source
Closed-Source
For further reading on the why and how’s of Javascript Obfuscation, I recommend checking out the Jscrambler blog posts. For now, though, I’ll shift the topic towards reverse engineering.
How is Obfuscated Code Analyzed?
In general, most reverse engineering/deobfuscation techniques fall under two categories: static analysis and dynamic analysis
Static Analysis
Static analysis refers to the inspection of source code without actually executing the program. An example of static analysis is simplifying source code with Regex.
Dynamic Analysis
Dynamic analysis refers to the testing and analysis of an application during run time/evaluation. An example of dynamic analysis is using a debugger.
Static vs. Dynamic Analysis Use-Cases
Since static analysis does not execute code, it makes it ideal for analyzing untrusted scripts. For example, when analyzing malware, you may want to use static analysis to avoid infection of your computer.
Dynamic analysis is used when a script is known to be safe to run. Debuggers can be powerful tools for reverse engineering, as they allow you to view the state of the program at different points in the runtime. Additionally, dynamic analysis can be (and often is) used for malware analysis too, but only after taking proper security precautions (i.e sandboxing).
Static and dynamic analysis are powerful when used together. For example, debugging a script containing a lot of junk code can be difficult. Or, the code may contain anti-debugging protection (e.g. infinite debugger loops). In this case, someone may first use static inspection of source code to simplify the source code, then proceed with dynamic analysis using the modified source.
Introducing Babel
Babel is a Javascript to Javascript compiler. The functionalities included with the Babel framework make it exceptionally useful for any javascript deobfuscation use case, since you can use it for static analysis and dynamic analysis!
Let me give a short explanation of how it works:
Javascript is an interpreted programming language. For Javascript to be interpreted by an engine (e.g. Chrome’s V8 engine or Firefox’s Spidermonkey) into machine code, it is first parsed into an Abstract Syntax Tree (AST). After that, the AST is used to generate machine-readable byte-code, which is then executed.
Babel works in a similar fashion. It takes in Javascript code, parses it into an AST, then outputs javascript based on that AST.
Okay, sounds interesting. But what even is an AST?
Definition: Abstract Syntax Tree
An Abstract Syntax Tree (AST) is a tree-like structure that hierarchically represents the syntax of a piece of source code. Each node of the tree represents the occurrence of a predefined structure in the source code. Any piece of source code, from any programming language, can be represented as an AST.
Note: Even though the concepts behind an AST are universal, different programming languages may have a different AST specifications based on their capabilities.
Some practical uses of ASTs include:
- Validating Code
- Formatting Code
- Syntax Highlighting
And, of course, due to the more verbose nature of ASTs relative to plaintext source code, it makes them a great tool for reverse engineering 😁
Unfortunately, I won’t be giving a more in-depth definition of ASTs. This is for the sake of time, and since that’d be more akin to the subject of compiler theory than deobfuscation. I’d prefer to get right into explaining the usage of Babel as quickly as possible. However, I’ll leave you with some resources to read up more about ASTs (which probably offer a better explanation than I could muster anyway):
Wikipedia - Abstract Syntax Trees
How JavaScript works: Parsing, Abstract Syntax Trees (ASTs) + 5 tips on how to minimize parse time
How Babel Works
Babel can be installed the same way as any other NodeJS package. For our purposes, the following packages are relevant:
@babel/core This encapsulates the entire Babel compiler API.@babel/parser The module Babel uses to parse Javascript source code and generate an AST@babel/traverse The module that allows for traversing and modifying the generated AST@babel/generator The module Babel uses to generate Javascript code from the AST.@babel/types A module for verifying and generating node types as defined by the Babel AST implementation.
When compiling code, Babel goes through three main phases:
- Parsing => Uses
@babel/parserAPI - Transforming => Uses
@babel/traverseAPI - Code Generation => Uses
@babel/generatorAPI
I’ll give you a (very) short summary of each of these phases:
Stages of Babel
Phase #1: Parsing
During this phase, Babel takes source code as an input and outputs an AST. Two stages of parsing are Lexical Analysis and Syntactic Analysis.
To parse code into an AST, we make use of @babel/parser. The following is an example of parsing code from a file, sourcecode.js:
1 2 3 | JAVASCRIPT |
You can read more about the parsing phase here:
Babel Plugin Handbook - Parsing
Babel Docs - @babel/parser
Phase 2: Transforming
The transformation phase is the most important phase. During this phase, Babel takes the generated AST and traverses it to add, update, or remove nodes. All the deobfuscation transformations we write are executed in this stage. This stage will be the main focus of future tutorials.
Phase 3: Code Generation
The code generation phase takes in the final AST and converts it back to executable Javascript.
The Babel Workflow
This section will not discuss any practical deobfuscation techniques. It will only detail the general process of analyzing source code. I’ll be using an unobfuscated piece of code as an example.
When deobfuscating Javascript, I typically follow this workflow:
- Visualization
- Analysis
- Writing the Deobfuscator
Phase 1: Visualization with AST Explorer
Before we can write any plugins for a deobfuscator, we should always first visualize the code’s AST. To help us with that, we will leverage an online tool: AstExplorer.net.
AST Explorer serves as an interactive AST playground. It allows you to choose a programming language and parser. In this case, we would select Javascript as the programming language and @babel/parser as the parser. After that, we can paste some source code into the window and inspect the generated AST on the right-hand side.
As an example, I’ll use this snippet:
1 2 3 4 5 | JAVASCRIPT |
Result from pasting the code snippet in AST Explorer
The generated AST looks like this:
Click to Expand
We can observe that even for this small little program, the AST representation is incredibly verbose. It’s composed of different types of nodes (FunctionDeclarations, ExpressionStatements, Identifiers, CallExpressions, etc.), and many nodes also have a sub node. To transform the AST, we’ll be making use of the Babel traverse package to recursively traverse the tree and modify nodes.
Phase 2: Coming Up With The Transformation Logic/Pseudo-code
This isn’t an obfuscated file, but we’ll still write a plugin to demonstrate the traverse package’s functionality.
Let’s assign ourselves an arbitrary goal of transforming the script to replace all occurrences of arithmetic addition operators (+) with arithmetic multiplication operators (*). That is, the final script should look like this:
1 2 3 4 5 | JAVASCRIPT |
Determining the Target Node Type(s)
First, we need to determine what our node type(s) of interest are. If we highlight a section of the code, AST explorer will automatically expand that node on the right-hand side. In our case, we want to focus on the arg1 + arg2 operation. After highlighting that piece of code, we’ll see this:
A closer look at the nodes of interest
We can see that arg1 + arg2 has been parsed into a BinaryExpression node. This node has the following properties:
typestores the node’s type, in this case:BinaryExpressionleftstores the information for the left side of the expression, in this case: thearg1identifier.rightstores the information for the right side of the expression, in this case: thearg2identifier.operatorstores the operator, in this case:+.
Our goal is to replace all + operators in the script with a * operator, so it makes sense that our node type of interest is a BinaryExpression.
Now that we have our target node type, we need to figure out how we’ll transform them
Transformation Logic
To reiterate: we know that we’re looking for BinaryExpressions. Each BinaryExpression has a property, operator. We want to edit this property to * if it is a +.
The logical process would therefore look like this:
- Parse the code to generate an AST.
- Traverse the AST in search of
BinaryExpressions. - If one is encountered, check that its operator is currently equal to
+. If it isn’t, skip that node. - If the operator is equal to
+, set the operator to*.
Now that we understand the logic, we can write it as code
Phase 3: Writing the Transformation Code
To parse the tree, we will use the @babel/parser package as previously demonstrated. To traverse the generated AST and modify the nodes, we’ll make use of @babel/traverse.
To target a specific node type during traversal, we’ll use a visitor[https://github.com/jamiebuilds/babel-handbook/blob/master/translations/en/plugin-handbook.md#visitors].
From the Babel Plugin Handbook:
Visitors are a pattern used in AST traversal across languages. Simply put they are an object with methods defined for accepting particular node types in a tree.
To target nodes of type BinaryExpression, our visitor would like like this:
1 2 3 4 5 | JAVASCRIPT |
Now, every time a BinaryExpression is encountered, the BinaryExpression(path) method will be called.
Inside the BinaryExpression(path) method of our visitor, we can add code for any checks and transformations.
Each visitor method takes in a parameter, path, which holds the path to the node being visited. To access the actual properties of the node, we must use path.node.
Our first step in our transformation would be to check that the operator property of the node is a +. We can do that like this:
1 2 3 4 5 6 7 8 9 | JAVASCRIPT |
If it is a +, we can set it to *.
1 2 3 4 5 6 7 8 9 10 11 | JAVASCRIPT |
And our visitor is complete! Now we just need to call it on the generated AST. But first, let’s generate the AST:
1 2 3 4 5 6 7 8 9 10 11 12 13 | JAVASCRIPT |
After that, we can paste our visitor into the source code. To traverse the AST using the visitor, we’ll use the traverse method from the @babel/traverse package. That would look like this:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 | JAVASCRIPT |
Finally, we’ll use the generate method from the @babel/generator package to generate the final code from the modified AST. We can also output the resulting code to a file, but I’ll just log it to the console for simplicity.
So, our final transformation script looks like this:
Babel Transformation Script
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 | JAVASCRIPT |
This will output the following to the console:
1 2 3 4 5 | JAVASCRIPT |
And we can see that the code has been successfully transformed to replace + operators with * operators!
Why use Babel for Deobfuscation?
So, why should we use Babel as a deobfuscation tool as opposed to other static analysis tools like Regex?
Here are a few reasons:
-
Ast is less error-prone.
- For large chunks of code, writing transformations can become incredibly tedious due to the edge cases. For example, it’s difficult to account for the scope and state of variables when using regex. For example, two different variables can share the same name if they’re in different scopes:
1 2 3 4 5 6 7 8 9 | JAVASCRIPT |
Eventually, regular expressions will become very convoluted when you have to account for edge cases; whether it be scope or tiny variations in syntax. Babel doesn’t have this problem, as you can use built-in functionality to make transformations with respect to scope and state.
-
The Babel API has a lot of useful features.
Here are a few useful things you can do with the built-in Babel API:
- Easily target certain nodes
- Handle scope when renaming/replacing variables
- Easily get initial values and references of variables
- Node validation, generation, cloning, replacement, removal
- Find paths to ancestor and descendant nodes based on test conditions
- Containers/Lists: Check if a node is in a container/list, and get all of its siblings
-
Good for static and dynamic analysis
- Inherently, parsing the code into an AST and applying transformations will not execute the code. But Babel also has the functionality to evaluate nodes (ex. BinaryExpressions) and return their actual value. Babel can also generate code from nodes, which can be evaluated with
evalor the NodeJS VM.
- Inherently, parsing the code into an AST and applying transformations will not execute the code. But Babel also has the functionality to evaluate nodes (ex. BinaryExpressions) and return their actual value. Babel can also generate code from nodes, which can be evaluated with
Conclusion + Additional Resources
That was a short demonstration of transforming a piece of code with Babel! The next articles will be more in-depth and include practical cases of reversing obfuscation techniques you might encounter in the wild.
For the sake of time, I didn’t go too deep into the behind-the-scenes of Babel or all of its API methods. In the future, I may decide to update this article or write a new one with more detailed explanations, examples, and documentation. But, I really recommend getting a solid fundamental understanding of Babel’s features before continuing on in this series. Most notably, I didn’t cover the usage of the @babel/types package in this article, but it will be utilized in future ones. I’d recommend giving these resources a look:
Official Babel Docs
Babel Plugin Handbook
Video: @babel/how-to
Here are links to the other articles in this series:
-
Deobfuscating Javascript via AST: Reversing Various String Concealing Techniques
-
Deobfuscating Javascript via AST: Converting Bracket Notation => Dot Notation for Property Accessors
-
Deobfuscating Javascript via AST: Constant Folding/Binary Expression Simplification
-
Deobfuscating Javascript via AST: Constant Folding/Binary Expression Simplification
-
Deobfuscating Javascript via AST: Replacing References to Constant Variables with Their Actual Value
-
Deobfuscating Javascript via AST: Removing Dead or Unreachable Code
You can also view the source code for all my deobfuscation tutorial posts in this repository
Okay, that’s all I have for you today. I hope that this article helped you learn something new. Thanks for reading, and happy reversing!
-----------------------------------------------------------------------------------------------------------------------
Preface
This article assumes a preliminary understanding of Abstract Syntax Tree structure and BabelJS. Click Here to read my introductory article on the usage of Babel.
What is String Concealing?
In JavaScript, string concealing is an obfuscation technique that transforms code in a way that disguises references to string literals. After doing so, the code becomes much less readable to a human at first glance. This can be done in multiple different ways, including but not limited to:
- Encoding the string as a hexadecimal/Unicode representation,
- Splitting a single string into multiple substrings, then concatenating them,
- Storing all string literals in a single array and referencing an element in the array when a string value is required
- Using an algorithm to encrypt strings, then calling a corresponding decryption algorithm on the encrypted value whenever its value needs to be read
In the following sections, I will provide some examples of these techniques in action and discuss how to reverse them.
Examples
Example #1: Hexadecimal/Unicode Escape Sequence Representations
Rather than storing a string as a literal, an author may choose to store it as an escape sequence. The javascript engine will parse the actual string literal value of an escaped string before it is used or printed to the console. However, it’s virtually unreadable to an ordinary human. Below is an example of a sample obfuscated using this technique.
Original Source Code
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 | JAVASCRIPT |
Post-Obfuscation Code
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 | JAVASCRIPT |
Analysis Methodology
Despite appearing daunting at first glance, this obfuscation technique is relatively trivial to reverse. To begin, let’s copy and paste the obfuscated sample into AST Explorer
View of the obfuscated code in AST Explorer
Our targets of interest here are the obfuscated strings, which are of type StringLiteral. Let’s take a closer look at one of these nodes:
A closer look at one of the obfuscated StringLiteral nodes
We can deduce two things from analyzing the structure of these nodes:
- The actual, unobfuscated value has been parsed by Babel and is stored in the value property.
- All nodes containing escaped text sequences have a property, extra which store the actual value and encoded text in extra.rawValue and extra.raw properties respectively
Since the parsed value is already stored in the value property, we can safely delete the extra property, causing Babel to default to the value property when generating the code and thereby restoring the original strings. To do this, we create a visitor that iterates through all StringLiteral_to nodes to delete the **_extra** property if it exists. After that, we can generate code from the resulting AST to get the deobfuscated result. The babel implementation is shown below:
Babel Deobfuscation Script
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 | JAVASCRIPT |
After processing the obfuscated script with the babel plugin above, we get the following result:
Post-Deobfuscation Result
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | JAVASCRIPT |
The strings are now deobfuscated, and the code becomes much easier to read.
Example #2: String-Array Map Obfuscation
This type of obfuscation removes references to string literals and places them in a special array. Whenever a value must be accessed, the obfuscated script will reference the original string’s position in the string array. This technique is often combined with the previously discussed technique of storing strings as hexadecimal/unicode escape sequences. To isolate the point in this example, I’ve chosen not to include additional encoding. Below is an example of this obfuscation technique in practice:
Original Source Code
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 | JAVASCRIPT |
Post-Obfuscation Code
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 | JAVASCRIPT |
Analysis Methodology
Similar to the first example, this obfuscation technique is mostly for show and very trivial to undo. To begin, let’s copy and paste the obfuscated sample into AST Explorer
View of the obfuscated code in AST Explorer
Our targets of interest here are the master array, _0xcd45 and its references. These references to it are of type MemberExpression. Let’s take a closer look at one of the MemberExpression nodes of interest.
A closer look at one of the obfuscated MemberExpression nodes
We can notice that, unlike the first example, babel does not compute the actual value of these member expressions for us. However, it does store the name of the array they are referencing and the position of the array to be accessed.
Let’s now expand the VariableDeclaration node that holds the string array.
A closer look at the Variable Declaration node for the _0xcd45 array
We can observe that the name of the string array,_0xcd45 is held in path.node.declarations[0].id.name. We can also see that path.node.declarations[0].init.elements is an array of nodes, which holds each node of the string literals declared in the string array. Finally, the string array is the first VariableDeclaration with an init value of type ArrayExpression encountered at the top of the file.
[Note: Traditionally, javascript obfuscators put the string arrays at the top of the file/code block. However, sometimes this may not always be the case (e.g. other string-containing arrays are declared first or reassignment of the string array). You may need to make a slight modification to this step in that case.]
Using those observations, we can come up with the following logic to restore the code:
-
Traverse the ast to search for the variable declaration of the string array. To check if it is the string array’s declaration, it must meet the following criteria:
- The VariableDeclaration node must declare only ONE variable.
- Its corresponding VariableDeclarator node must have an init property of type ArrayExpression
- ALL of the elements of the ArrayExpression must be of type StringLiteral
-
After finding the declaration, we can:
- Store the string array’s name in a variable,
stringArrayName - Store a copy of all its elements in a variable,
stringArrayElements
- Store the string array’s name in a variable,
-
Find all references to the string array. One of the most powerful features of Babel is it’s support for scopes.
From the Babel Plugin Handbook:
References all belong to a particular scope; this relationship is known as a binding.
We’ll take advantage of this feature by doing the following:
- To ensure that we are getting the references to the correct identifier, we will get the path of the
idproperty and store it in a variable,idPath. - We will then get the binding of the string array, using
idPath.scope.getBinding(stringArrayName)and store it in a variable,binding. - If the binding does not exist, we will skip this variable declarator by returning early.
- The
constantproperty ofbindingis a boolean determining if the variable is constant. If the value ofconstantis false (i.e, it is reassigned/modified), replacing the references will be unsafe. In that case, we will return early. - The
referencePathsproperty ofbindingis an array containing every NodePaths that reference the string array. We’ll extract this to its own variable.
- To ensure that we are getting the references to the correct identifier, we will get the path of the
-
We will create a variable,
shouldRemove, which will be a flag dictating whether or not we can remove the original VariableDeclaration. By default, we’ll initialize it totrue. More on this in the next step. -
We will loop through each individual
referencePathof thereferencePathsarray, and check if they meet all the following criteria:- The parent NodePath of the current
referencePathmust be a MemberExpression. The reason we are checking the parent node is because thereferencePathrefers to the actual referenced identifier (in our example,_0xcd45), which would be contained in a MemberExpression parent node (such as_0xcd45[0]) - The parent NodePath’s
objectfield must be the the current referencePath’s node (that is, it must be the string array’s identifier) - The parent NodePath’s
computedfield must betrue. This means that bracket notation is being used for member access (ex._0xcd45[0]). - The parent NodePath’s
propertyfield must be of typeNumericLiteral, so we can use it’s value to access the corresponding node by index.
- The parent NodePath of the current
-
If all of these criteria are met, we can lookup the corresponding node in our
stringArrayElementsarray using the value stored in the parent NodePath’spropertyfield, and safely replace thereferencePath‘s parent path with it (that is, replace the entire MemberExpression with the actual string). -
If at least one of these conditions are not met for the current
referencePath, we will be unable to replace the referencePath. In this case, removing the original VariableDeclarator of the string array would be unsafe, since these references to it would be in the final code. Therefore, we should set ourshouldDeleteflag to false. We’ll then skip to the next iteration of the for loop. -
After we have finished iterating over all the referencePaths, we will use the value of our
shouldRemoveflag to determine if it is safe to remove the original VariableDeclaration.
- If
shouldRemovestill has the default value oftrue, that means all referencePaths have been successfully replaced, and the original declaration of the string array is no longer needed, so we can remove it. - If
shouldRemoveis equal tofalse, we encountered a referencePath that we could not replace. It is then unsafe to remove the original declaration of the string array, so we don’t remove it.
The Babel implementation is shown below:
Babel Deobfuscation Script
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 | JAVASCRIPT |
After processing the obfuscated script with the babel plugin above, we get the following result:
Post-Deobfuscation Result
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | JAVASCRIPT |
The strings are now deobfuscated, and the code becomes much easier to read.
Example #3: String Concatenation
This type of obfuscation, in its most basic form, takes a string such as the following:
1 | JAVASCRIPT |
And splits it into multiple parts:
1 | JAVASCRIPT |
You might be thinking, “Hey, the obfuscated version doesn’t look that bad”, and you’d be right. However, keep in mind that a file will typically have a lot more obfuscation layered on top. An example using the techniques already covered above could look something like this (or likely more advanced):
1 2 3 4 5 6 7 8 9 | JAVASCRIPT |
The following analysis will only cover the most basic case from the first example I showed you. Traditionally, a file’s obfuscation layers are peeled back one at a time. Your goal as a reverse engineer would be to make transformations to the code such that it looks like the basic case and only then apply this analysis.
Original Source Code
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 | JAVASCRIPT |
Post-Obfuscation Code
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 | JAVASCRIPT |
Analysis Methodology
Let’s paste our obfuscated code into AST Explorer.
View of the obfuscated code in AST Explorer
Our targets of interest here are all of the strings being concatenated. Let’s click on one of them to take a closer look at one of the nodes of interest.
A closer look at one of the nodes of interest
We can make the following observations from the AST structure:
- We can see that each individual substring is of type StringLiteral.
- More importantly, the string literals seem to be contained in multiple nested BinaryExpressions.
So how could we go about solving this?
There are a few ways to do this. One would be to work up recursively from the right-most StringLiteral node in the binary expression and manually concatenate the string at each step. However, there’s a much simpler way to accomplish the same thing using Babel’s inbuilt path.evaluate() function. The steps for coding the deobfuscator are included below:
- Traverse through the AST to search for BinaryExpressions
- If a BinaryExpression is encountered, try to evaluate it using path.evaluate().
- If path.evaluate returns confident:true, check if the evaluated value is a StringLiteral. If either condition is false, return.
- Replace the BinaryExpression node with the computed value as a StringLiteral, stored in value.
The babel implementation is shown below:
Babel Deobfuscation Script
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 | JAVASCRIPT |
After processing the obfuscated script with the babel plugin above, we get the following result:
Post-Deobfuscation Result
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | JAVASCRIPT |
But hold on, that looks only partly deobfuscated!
A Minor Complication
Okay, I may have lied to you a bit. The example I gave you actually contains two cases. The simplest case with ONLY string literals:
1 2 3 4 5 | JAVASCRIPT |
And the bit more advanced case, where string literals are mixed with non-string literals (in this case, variables):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | JAVASCRIPT |
The above algorithm will not work for the second case as is. However, there’s a simple remedy. Simply edit the obfuscated file to wrap consecutive strings in brackets like so:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | JAVASCRIPT |
And our deobfuscator will output our desired result:
1 2 3 4 5 6 7 | JAVASCRIPT |
I’m sure some of you might be wondering why the algorithm doesn’t work without manually adding the brackets. This is outside of the scope of this article. However, if you’re interested in the reason for this intricacy and an algorithm that simplifies it without needing to manually add the brackets, check out my article about Constant Folding. But for now, I’ll move on to another example.
Example #4: String Encryption
First and foremost, string encryption IS NOT the same as encoding strings as hexadecimal or unicode. Whereas the javascript interpreter will automatically interpret"\x48\x65\x6c\x6c\x6f" as "Hello", encrypted strings must be passed through to a decryption function and evaluated before they become useful to the javascript engine (or representable as a StringLiteral by Babel).
For example, even though Base64 is a type of encoding, in the context of string concealing it falls under string encryption since console.log("SGVsbG8=") prints SGVsbG8=, but console.log(atob{SGVsbG8=}) prints Hello. In this example, atob() is the decoding function.
Most obfuscators will define custom functions for encrypting and decrypting strings. Sometimes, the string may need to go through multiple decryption functions Therefore, there is no universal solution for deobfuscating string encryption. Most of the time, you’ll need to manually analyze the code to find the string decryption function, hard-code it into your deobfuscator, then evaluate it for each CallExpression that references it. The example below will cover a single example that uses an XOR cipher from this repository for obfuscating the strings.
Original Source Code
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 | JAVASCRIPT |
Post-Obfuscation Code
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 | JAVASCRIPT |
Analysis Methodology
Let’s paste our obfuscated code into AST Explorer.
View of the obfuscated code in AST Explorer
Our targets of interest here are the cryptic calls to the _0x2720d7 function. Let’s take a closer a closer look at one of them.
A closer look at one of the nodes of interest
We can observe that the nodes of interest are of type CallExpression. Each call expression takes in two parameters. The first is a StringLiteral which holds the encrypted string. The second is a NumericLiteral, which is used as a decryption key.
There are two ways we can deobfuscate this script, the second of which I personally prefer since it looks cleaner.
Method #1: The Copy-Paste Technique
The first method involves the following steps:
- Find the decryption function in the obfuscated script
- Paste the decryption function,
_0x2720d7, in our deobfuscator - Traverse the ast in search for the FunctionDeclaration of the decryption function (in this case,
_0x2720d7). Once found, remove the path as it is no longer necessary - Traverse the ast in search of CallExpressions where the callee is the decryption function (in this case,
_0x2720d7). Once found:- Assign each arugument of
path.node.argumentsto a variable, e.g.stringToDecryptanddecryptionKeyrespectively. - Create a variable,
result - Evaluate
_0x2720d7(stringToDecrypt,decryptionKey)and assign the resulting value toresult - Replace the CallExpression path with the actual value:
path.replaceWith(t.valueToNode(result))
- Assign each arugument of
One of the reasons I don’t like to use this method is that the code for the deobfuscator can become quite long and messy if:
- The decryption function contains many lines of code, or
- There are many parameters to parse from the CallExpression
A cleaner approach in my opinion is the next method, which evaluates the decryption function and its calls in a virtual machine.
Method #2: Using the NodeJS VM module
Whenever possible, I prefer to use this method because of its cleanliness. Why? Well,
- It doesn’t require me to copy-paste the entire encryption function into my deobfuscator
- I don’t need to manually parse any of the arguments of CallExpressions before execution.
The only downside is that it requires two separate visitors and therefore two traversals, whereas you can probably implement the first method in a single traversal.
Here are the steps to implement it:
- Create a variable,
decryptFuncCtxand assign it an empty context usingvm.createContext() - Traverse the ast in search for the FunctionDeclaration of the decryption function (in this case,
_0x2720d7). Once found:- Use
@babel/generatorto generate the function’s source code from the node and assign it to a variable,decryptFuncCode - Add the decryption function to the VM’s context using
vm.runInContext(decryptFuncCode, decryptFuncCtx) - Delete the FunctionDeclaration node with
path.remove()as it’s now useless, and stop traversing withpath.stop()
- Use
- Traverse the ast in search of CallExpressions where the callee is the decryption function (in this case,
_0x2720d7). Once found:- Use
@babel/generatorto generate the CallExpression’s source code from the node and assign it to a variable,expressionCode - Evaluate the function call in the context of
decryptFuncCtxusingvm.runInContext(expressionCode,decryptFuncCtx). - Optionally assign the result to a variable,
value - Replace the CallExpression node with the computed value to restore the unobfuscated string literal.
- Use
Note: for both of these methods you should probably come up with a dynamic way to detect the decryption function (by analyzing the structure of the function node or # of calls) in case the script is morphing. You should also pay mind to the scope of function and also check if it’s ever redefined later in the script. But for this example, I will neglect that and just hardcode the name for simplicity.
The babel implementation for the second method is shown below:
Babel Deobfuscation Script
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 | JAVASCRIPT |
After processing the obfuscated script with the babel plugin above, we get the following result:
Post-Deobfuscation Result
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | JAVASCRIPT |
The strings are now deobfuscated, and the code becomes much easier to read.
Conclusion
Phew, that was quite the long segment! That about sums up the majority of string concealing techniques you’ll find in the wild and how to reverse them.
Before I go, I want to address one thing (as a bonus of sorts):
After deobfuscating the strings, we can see that they’re restored to:
1 2 3 | JAVASCRIPT |
But someone familiar with Javascript knows that the convention is to write it like this:
1 2 3 | JAVASCRIPT |
The good news is, you can also use Babel to restore the traditional dot operator formatting in MemberExpressions. Read my article about it here!
If you’re interested, you can find the source code for all the examples in this repository.
I hope that this article helped you learn something new. Thanks for reading, and happy reversing!
---------------------------------------------------------------------------------------------------------------------------------
Preface
This article assumes a preliminary understanding of Abstract Syntax Tree structure and BabelJS. Click Here to read my introductory article on the usage of Babel.
I’ll be honest, this transformation is less “deobfuscation” than it is “making our script look slightly prettier”. Even so, I think that it’s worth mentioning since it’s still an interesting example of how to manipulate an abstract syntax tree with babel. So, without further ado, let’s get into it!
Bracket Notation vs. Dot Notation
Let’s say we have the following piece of Javascript:
1 2 3 4 | JAVASCRIPT |
The above code is an example of using bracket notation to access the properties of an object.
If you’re familiar with Javascript, you probably know that the code above can also be written like this:
1 2 3 4 | JAVASCRIPT |
The second snippet looks much cleaner because it isn’t littered with brackets and quotation marks. That’s why most programmers prefer the second snippet’s formatting over that of the first (unless, of course, you’re a psychopath).
So, how can we go about automatically transforming the first snippet to look like the second snippet? Let’s walk through the process step by step together.
Analysis Methodology
Let’s start by pasting both snippets into AST Explorer to see the differences. First, we’ll investigate the first snippet. Our targets of interest are the first and second lines of the script:
A closer look at one of the nodes of interest; first code snippet
So, we can see that our nodes of interest are of type MemberExpression. Each node has 3 important properties:
path.node.object, which stores the object being accessed (in this case, theDateobject)path.node.property, which stores the property to access (in this case, it’s theNowproperty and of type StringLiteral)path.node.computed, which tells us whether the MemberExpression is computed, (i.e, a value of true means uses bracket notation) or not (i.e, a value of false means use dot notation). In this case, thecomputedproperty is set totruesince bracket notation is being used.
Now, let’s analyze the same node on AST explorer, but for the second code snippet:
A closer look at one of the nodes of interest; second code snippet
After looking at it, we can observe that they’re nearly identical. But there are two important differences in the second case:
path.node.propertyis of type Identifier, NOT StringLiteral.path.node.computedis set tofalse, NOTtrue.
This makes sense, since path.node.computed being false means that dot notation will be used. The property must then be of type Identifier, because you can only access properties via the dot operator with a valid identifier name.
So, using those observations, we can come up with the following logic to write a babel plugin to restore the code:
- Traverse the AST for MemberExpressions
- Once a MemberExpression is found:
- Verify that the
path.node.computedproperty is set to true. If it isn’t skip that node by returning. - Very that
path.node.propertyis of type StringLiteral. If it isn’t, skip that node by returning. - Verify that the value of
path.node.propertymeets all the requirements of a valid identifier. This can be done by testing it against the regex for a valid identifier, taken from this Stack Overflow answer - Use
path.replaceWith()to replace the MemberExpression with a new one, where:- The object is still
path.node.object path.node.propertyis an Identifier node, with the name set to the value stored inpath.node.property.valuepath.node.computedis equal tofalse
- The object is still
- Verify that the
The babel implementation is shown below:
Babel Deobfuscation Script
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 | JAVASCRIPT |
After processing the obfuscated script with the babel plugin above, we get the following result:
Post-Deobfuscation Result
1 2 3 4 | JAVASCRIPT |
And the dot operator is restored!
Conclusion
So, today we discussed a simple but efficient way to restore the dot operator for MemberExpressions. After converting bracket notation to dot notation, it becomes a lot easier for us to differentiate between object member accessors and array element accessors. This is because of our StringLiteral check on `path.node.property’.
I’ll leave you with one useful piece of advice. You should probably run this plugin as a sort of “clean up transformer”, only after replacing all constant variables with their actual value. This is because if you don’t substitute in the actual value of a variable, this plugin won’t have any useful effect. For example, running the plugin on this code:
1 2 | JAVASCRIPT |
Will give us:
1 2 | JAVASCRIPT |
Which is the exact same thing. To restore it to let bar = window.navigator, we first must replace all references to the constant variable foo with its actual value, "navigator". If you want to learn how to do that, you can read my article on replacing constant variables with their actual value.
If you’re interested, you can find the source code for all the examples in this repository.
I hope this article helped you learn something new. Thanks for reading, and happy reversing!
--------------------------------------------------------------------------------------------------------------------------
Preface
This article assumes a preliminary understanding of Abstract Syntax Tree structure and BabelJS. Click Here to read my introductory article on the usage of Babel.
What is Constant Folding?
Constant Folding: “An optimization technique that eliminates expressions that calculate a value that can already be determined before code execution.” (Source)
To better explain constant folding, it’s perhaps more useful to first introduce the obfuscation technique that constant folding fights against. Take the following code for example:
Examples
Example #1: The Basic Case
1 2 3 4 5 6 7 8 | JAVASCRIPT |
An obfuscator may split each constant value into multiple binary expressions, which could look something like this after obfuscation:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 | JAVASCRIPT |
As you can see, the obfuscation has transformed what used to be easy to read constants; 27, 4, "I am a string literal, totally whole!" ; into multiple expressions with arithmetic and bitwise operators. The code is even using mathematical operators on booleans! Someone reading the code would likely need to evaluate each expression in a debugger to figure out the value of each variable. Let’s paste the second snippet in the dev tools console to check:
Checking the evaluated values in the DevTools console
We can observe that each variable in the second snippet has an equivalent ability to that of its first snippet counterpart. The way the javascript engine simplified the expressions down to a constant is the essence of Constant Folding.
Now, hypothetically, you could just evaluate each expression in a javascript interpreter and replace it by hand manually. And sure, you could do that in just a few seconds for the snippet I provided. But that isn’t a feasible solution if there were hundreds or even thousands of lines of code in a program similar to this. Thankfully for us, Babel has an inbuilt feature that can help us automate the simplification.
Analysis Methodology
Let’s start by pasting the obfuscated sample into AST Explorer
View of the obfuscated code in AST Explorer
If we click on one of the expression chunks on the right-hand side of the assignment expressions, we can take a closer look at the AST structure:
A closer look at one of the nodes of interest
We can see that in this case, the small chunk of the string is of type StringLiteral, and it’s contained inside a bunch of nested BinaryExpression nodes. If we look at any other fraction of the other expressions, we can observe two important commonalities
-
A constant value, or Literal (e.g. StringLiteral,NumericLiteral, or BooleanLiteral)
-
The Literal is contained inside a single or nested BinaryExpression(s).
Our final goal is to evaluate all the binary expressions to reduce each right-hand side expression to a constant Literal value. Based on the nested nature of the BinaryExpressions, you might be thinking of manually writing a recursive algorithm. However, there’s a much simpler way to accomplish the same effect using Babel’s inbuilt path.evaluate() function. Here’s how we’re going to use it:
- Traverse through the AST to search for BinaryExpressions
- If a BinaryExpression is encountered, try to evaluate it using
path.evaluate(). - Check if it returns
confident:true. Ifconfidentisfalse, skip the node by returning. - Create a node from the value using
t.valueToNode(value)to infer the type, and assign it to a new variable,valueNode - Check that the resulting
valueNodeis a Literal type. If the check returnsfalseskip the node by returning.- This will cover StringLiteral, NumericLiteral, BooleanLiteral etc. types and skip over others that would result from invalid operations (e.g.
t.valueToNode(Infinity)is of type BinaryExpression,t.valueToNode(undefined)is of type identifier)
- This will cover StringLiteral, NumericLiteral, BooleanLiteral etc. types and skip over others that would result from invalid operations (e.g.
- Replace the BinaryExpression node with our newly created `valueNode’.
The babel implementation is shown below:
Babel Deobfuscation Script
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 | JAVASCRIPT |
After processing the obfuscated script with the babel plugin above, we get the following result:
Post-Deobfuscation Result
1 2 3 | JAVASCRIPT |
And the original code is completely restored!
Example #2: A Confident Complication
If you’ve read my article on String Concealing, specifically the section on String Concatenation, you may know that you can encounter a problem using the babel script above.
Let’s say you have a code snippet like this:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 | JAVASCRIPT |
By manual inspection, you can probably deduce that it can be reduced to this:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | JAVASCRIPT |
However, if we try running the deobfuscator we made above against the obfuscated snippet, it yields this result:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 | JAVASCRIPT |
It hasn’t been simplified at all! But why?
Where The Issue Lies
To figure out what the problem is, let’s use a debugger and set breakpoints to try and understand what our deobfuscator is actually doing.
Placing a debugger statement
We know that our visitor is acting on nodes of type BinaryExpression. A binary expression always has 3 main components: a left side, a right side, and an operator. For our example, the operator is always addition, +. On each iteration, let’s run these commands in the debug console to check what our left and right side are.
generate(path.node).codegenerate(path.node.left).codegenerate(path.node.right).code
Below is a screencap of what the first two iterations would look like:
The first and second pause
When the visitor is first called, path.evaluate() will not return a value and the confident return value will be false. A false value for confident arises when the expression to be evaluated contains a variable whose value is currently unknown, and therefore Babel cannot be “confident” when attempting to compute an expression containing it. In the case of the first expression, the unknown variable (this.favAnimal) on the right side of the expression, and two unknown variables: (this.name & this.school) on the left side of the expression prevent path.evaluate() for returning a literal value. When the debugger statement is reached for a second time, the right-hand side of the expression is a StringLiteral ("a"). However, the left-hand side still contains variables with an unknown value. If we were to continue this for each time the breakpoint is encountered, the structure would look like this:
| Iteration | Left Side | Operator | Right Side |
|---|---|---|---|
| 1 | “Hello, my name is “ + this.name + “. I g” + “o t” + “o “ + this.school + “ an” + “d “ + “m” + “y” + “ fa” + “vo” + “ur” + “ite” + “ ani” + “ma” + “l” + “ is” + “ a “ | + | this.favAnimal |
| 2 | “Hello, my name is “ + this.name + “. I g” + “o t” + “o “ + this.school + “ an” + “d “ + “m” + “y” + “ fa” + “vo” + “ur” + “ite” + “ ani” + “ma” + “l” + “ is” | + | “ a” |
| 3 | “Hello, my name is “ + this.name + “. I g” + “o t” + “o “ + this.school + “ an” + “d “ + “m” + “y” + “ fa” + “vo” + “ur” + “ite” + “ ani” + “ma” + “l” | + | “ is” |
| 4 | “Hello, my name is “ + this.name + “. I g” + “o t” + “o “ + this.school + “ an” + “d “ + “m” + “y” + “ fa” + “vo” + “ur” + “ite” + “ ani” + “ma” | + | “l” |
| 5 | “Hello, my name is “ + this.name + “. I g” + “o t” + “o “ + this.school + “ an” + “d “ + “m” + “y” + “ fa” + “vo” + “ur” + “ite” + “ ani” | + | “ma” |
| 6 | “Hello, my name is “ + this.name + “. I g” + “o t” + “o “ + this.school + “ an” + “d “ + “m” + “y” + “ fa” + “vo” + “ur” + “ite” | + | “ ani” |
| 7 | “Hello, my name is “ + this.name + “. I g” + “o t” + “o “ + this.school + “ an” + “d “ + “m” + “y” + “ fa” + “vo” + “ur” | + | “ite” |
| 8 | “Hello, my name is “ + this.name + “. I g” + “o t” + “o “ + this.school + “ an” + “d “ + “m” + “y” + “ fa” + “vo” | + | “ur” |
| 9 | “Hello, my name is “ + this.name + “. I g” + “o t” + “o “ + this.school + “ an” + “d “ + “m” + “y” + “ fa” | + | “vo” |
| 10 | “Hello, my name is “ + this.name + “. I g” + “o t” + “o “ + this.school + “ an” + “d “ + “m” + “y” | + | “ fa” |
| 11 | “Hello, my name is “ + this.name + “. I g” + “o t” + “o “ + this.school + “ an” + “d “ + “m” | + | “y” |
| 12 | “Hello, my name is “ + this.name + “. I g” + “o t” + “o “ + this.school + “ an” + “d “ | + | “m” |
| 13 | “Hello, my name is “ + this.name + “. I g” + “o t” + “o “ + this.school + “ an” | + | “d “ |
| 14 | “Hello, my name is “ + this.name + “. I g” + “o t” + “o “ + this.school | + | “ an” |
| 14 | “Hello, my name is “ + this.name + “. I g” + “o t” + “o “ | + | this.school |
| 14 | “Hello, my name is “ + this.name + “. I g” + “o t” | + | “o “ |
| 14 | “Hello, my name is “ + this.name + “. I g” | + | “o t” |
| 14 | “Hello, my name is “ + this.name | + | “. I g” |
| 14 | “Hello, my name is “ | + | this.name |
It’s evident that at every encounter, one of the sides will always contain a variable of unknown value. Therefore, path.evaluate() will return confident: false and be useless in simplifying the expression. So, we’ll need to try something else.
Constructing the Solution
Idea #1: Prioritizing Chunks of Consecutive Literals
We know that the issue lies with one of the sides containing a variable. However, we can see that there are chunks of the code that contain consecutive string literals only:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | JAVASCRIPT |
If there were some way to prioritize these smaller chunks, then surely path.evaluate() would be able to simplify them. This is indeed the case, as we can prove this by manually wrapping each of these chunks in parentheses to force them to be evaluated first:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 | JAVASCRIPT |
Running this through the deobfuscator, we get our desired result:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | JAVASCRIPT |
Alright, so that did the job. But for very long binary expressions which you might encounter in wild obfuscated scripts, you certainly do not want to have to spend time manually wrapping chunks of consecutive strings in parentheses. Sure, you could probably automate it with Regex, or write an AST-based algorithm to add brackets to the source string, but there has to be a less complicated way, right?
The answer: Yes, there is. And we are on the right track.
Idea #2: Even Smaller Chunks
Okay, so we know that trying to pinpoint and prioritize chunks of consecutive strings with varying lengths can be troublesome. But what if we just split the binary expression into the smallest possible pieces and prioritized those?
I’ll admit, that probably sounds confusing. So I’ll do my best to explain what I mean with an example.
We know that a binary expression, in its simplest form, consists of a left side, an operator, and a right side. Let’s refer back to the first three rows of the table we made:
| Iteration | Left Side | Operator | Right Side |
|---|---|---|---|
| 1 | “Hello, my name is “ + this.name + “. I g” + “o t” + “o “ + this.school + “ an” + “d “ + “m” + “y” + “ fa” + “vo” + “ur” + “ite” + “ ani” + “ma” + “l” + “ is” + “ a “ | + | this.favAnimal |
| 2 | “Hello, my name is “ + this.name + “. I g” + “o t” + “o “ + this.school + “ an” + “d “ + “m” + “y” + “ fa” + “vo” + “ur” + “ite” + “ ani” + “ma” + “l” + “ is” | + | “ a” |
| 3 | “Hello, my name is “ + this.name + “. I g” + “o t” + “o “ + this.school + “ an” + “d “ + “m” + “y” + “ fa” + “vo” + “ur” + “ite” + “ ani” + “ma” + “l” | + | “ is” |
The right side of our binary expression is always only one element long, and is either a literal value or an identifier. However, the left side isn’t a single element long. Rather, it’s also a binary expression, containing both literal values and identifiers. What I propose is developing an algorithm to ensure that both the left side and right side are only a single element long. Then, if both are string literals, we can concatenate them. If not, we can simply move on.
To do this, let us look at the above table again, but only the first two rows. However, for the left side, let’s only take into consideration the right-most edge of the expression. That would look something like this:
| Iteration | Right Edge of Left Side | Operator | Right Side |
|---|---|---|---|
| 1 | “Hello, my name is “ + this.name + “. I g” + “o t” + “o “ + this.school + “ an” + “d “ + “m” + “y” + “ fa” + “vo” + “ur” + “ite” + “ ani” + “ma” + “l” + “ is” + “ a “ | + | this.favAnimal |
| 2 | “Hello, my name is “ + this.name + “. I g” + “o t” + “o “ + this.school + “ an” + “d “ + “m” + “y” + “ fa” + “vo” + “ur” + “ite” + “ ani” + “ma” + “l” + “ is” | + | “ a” |
If we were to evaluate these now, we would observe the following:
- Row 1 still cannot be evaluated, since it is a
StringLiteral+a variable of unknown value. - Row 2 can be simplified into a single string literal:
" is" + " a"=>" is a"
We can then replace the right-most edge of the left side with the simplified result, so it will become the right side in the next iteration. This way, we can simplify consecutive concatenation of strings step by step. Keep in mind, that each simplification will affect the next iteration’s right side. The reason I included the first few rows and not the third, is because the simplification in the second iteration would change the right side of the third iteration, so it would no longer look like the original table.
Following the new algorithm, each iteration of our visitor would look like this:
| Iteration | Right Edge of Left Side | Operator | Right Side |
|---|---|---|---|
| 1 | “ a “ | + | this.favAnimal |
| 2 | “ is” | + | “ a” |
| 3 | “l” | + | “ is a” |
| 4 | “ma” | + | “l is a” |
| 5 | “ ani” | + | “mal is a” |
| 6 | “ite” | + | “ animal is a” |
| 7 | “ur” | + | “ite animal is a” |
| 8 | “vo” | + | “urite animal is a” |
| 9 | “ fa” | + | “vourite animal is a” |
| 10 | “y” | + | “ favourite animal is a” |
| 11 | “m” | + | “y favourite animal is a” |
| 12 | “d “ | + | “my favourite animal is a” |
| 13 | “ an” | + | “d my favourite animal is a” |
| 14 | this.school | + | “ and my favourite animal is a” |
| 14 | “o “ | + | this.school |
| 14 | “o t” | + | “o “ |
| 14 | “. I g” | + | “o to “ |
| 14 | this.name | + | “. I go to “ |
| 14 | “Hello, my name is “ | + | this.name |
So, by following this algorithm, we should be able to combine all consecutive string literals into one.
WAIT! There’s something wrong here…
The line of code we start with is let helloStatement = "Hello, my name is " + this.name + ". I g" + "o t" + "o " + this.school + " an" + "d " + "m" + "y" + " fa" + "vo" + "ur" + "ite" + " ani" + "ma" + "l" + " is" + " a " + this.favAnimal;
We know that on the second iteration, " is" and " a" will be concatenated into a single string literal, then the right-most edge of the left side will be replaced with the resulting value. That is,
" is" => " is a"
The problem here is that we are adding the right side of the expression to the right edge of the left side of the expression. However, the original right side remains unchanged despite already being accounted for. The code after one iteration would then look like this:
let helloStatement = "Hello, my name is " + this.name + ". I g" + "o t" + "o " + this.school + " an" + "d " + "m" + "y" + " fa" + "vo" + "ur" + "ite" + " ani" + "ma" + "l" + " is a " + " a " + this.favAnimal;
Notice the extra duplicate near the end, " is a " + " a ". To fix this, we need to ensure that we delete the original right side of the expression after doing the concatenation and replacement.
So, based on this logic, the correct steps for creating the deobfuscator are as follows:
Writing The Deobfuscator Logic
-
Traverse the ast in search of BinaryExpressions. When one is encountered:
- If both the right side (
path.node.right) and the left side (path.node.left) are of type StringLiteral, we can use the algorithm for the basic case. - If not:
- Check if the right side, (
path.node.right) is a StringLiteral. If it isn’t, skip this node by returning. - Check if the right-most edge of the left-side (
path.node.left.right) is a StringLiteral. If it isn’t, skip this node by returning. - Check if the operator is addition (
+). If it isn’t, skip this node by returning. - Evaluate the right-most edge of the left-side + the right side;
path.node.left.right.value + path.node.right.valueand assign it’s StringLiteral representation to a variable,concatResult. - Replace the right-most edge of the left-side with
concatResult. - Remove the original right side of the expression as it is now a duplicate.
- Check if the right side, (
- If both the right side (
The Babel implementation is as follows:
Babel Deobfuscation Script
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 | JAVASCRIPT |
After processing the obfuscated script with the babel plugin above, we get the following result:
Post-Deobfuscation Result
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | JAVASCRIPT |
And all consecutive StringLiterals have been concatenated! Huzzah!
Conclusion
Okay, I hope that second example wasn’t too confusing. Sometimes, you’ll be able to avoid the problem with unknown variable values by replacing references to a constant variable with their actual value. If you’re interested in that, you can read my article about it here. In this case, however, it was unavoidable due to being within a class definition where variables have yet to be initialized.
Keep in mind that the second example will only work for String Literals and addition. But, it can easily be adapted to other node types and operators. I’ll leave that as a challenge for you, dear reader, if you wish to pursue it further 😉
If you’re interested, you can find the source code for all the examples in this repository.
Anyways, that’s all I have for you today. I hope that this article helped you learn something new. Thanks for reading, and happy reversing!
---------------------------------------------------------------------------
Preface
This article assumes a preliminary understanding of Abstract Syntax Tree structure and BabelJS. Click Here to read my introductory article on the usage of Babel.
Definition of a Constant Variable
For our purposes, a constant variable is any variable that meets all three of the following conditions:
- The variable is declared AND initialized at the same time.
- The variable is initialized to a literal value, e.g. StringLiteral, NumericLiteral, BooleanLiteral, etc.
- The variable is never reassigned another value in the script
Therefore, a variable’s declaration keyword (let,var,const) has no bearing on whether or not it is a constant.
Here is a quick example:
1 2 3 4 5 6 7 8 9 10 | JAVASCRIPT |
In this example:
ais not a constant, since it’s initialized as an ArrayExpression, not a Literaldis a constant, as it is declared and initialized to a NumericLiteral. Declaration and initialization happen at the same time. It is also never reassigned.eis a constant, as it is declared and initialized to a StringLiteral. Declaration and initialization happen at the same time. It is also never reassigned.fis not a constant, since it is reassigned after initialization:f+=2gis not a constant, since it is not declared and initialized at the same time.
The reasoning for declared but uninitialized variables not counting as a constant is an important concept to understand. Take the following script as an example:
1 2 3 4 5 6 7 | JAVASCRIPT |
Console Output:
1 2 | ACTIONSCRIPT |
If, in this case, we tried to substitute foo‘s initialization value (2) for each reference offoo:
1 2 3 4 5 6 7 | JAVASCRIPT |
Console Output:
1 2 | TEXT |
Which clearly breaks the original functionality of the script due to not accounting for the state of the variable at certain points in the script. Therefore, we must follow the 3 conditions when determining a constant variable.
I’ll now discuss an example where substituting in constant variables can be useful for deobfuscation purposes.
Examples
Let’s say we have a very simple, unobfuscated script that looks like this:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 | JAVASCRIPT |
We can obfuscate it by replacing all references to the string literals with references to constant variables:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 | JAVASCRIPT |
Analysis Methodology
Obviously, the obfuscated script is much more difficult to read. If you were to manually deobfuscate it, you’d have to search up each referenced variable and replace each occurrence of it with the actual variable. That could get tedious for a large number of variables, so we’re going to do it the Babel way. As always, let’s start by pasting the code into AST Explorer.
View of the obfuscated code in AST Explorer
Our targets of interest are the extra variable declarations. Let’s take a closer look at one of them:
A closer look at one of the nodes of interest
So, the target node type appears to be of type VariableDeclaration. However, each of these VariableDeclarations contains an array of VariableDeclarators. It is the VariableDeclarator that actually contains the information of the variables, including its id and init values. So, the actual node type we should focus on is VariableDeclarator.
Recall that we want to identify all constant variables, then replace all their references with their actual value. It’s important to note that variables in different scopes (e.g. local vs. global), may share the same name but have different values. So, the solution isn’t as simple as blindly replacing all matching identifiers with their initial value.
This would be a convoluted process if not for Babel’s ‘Scope’ API. I won’t dive too deep into the available scope APIs, but you can refer to the Babel Plugin Handbook to learn more about them. In our case, the scope.getBinding(${identifierName}) method will be incredibly useful for us, as it directly returns information regarding if a variable is constant and all of its references.
Putting all this knowledge together, the steps for creating the deobfuscator are as follows:
- Traverse the ast in search of VariableDeclarators. If one is found:
- Check if the variable is initialized. If it is, check that the initial value is a Literal type. If not, skip the node by returning.
- Use the
path.scope.getBinding(${identifierName})method with the name of the current variable as the argument. - Store the returned
constantandreferencedPathsproperties in their own respective variables. - Check if the
constantproperty istrue. If it isn’t, skip the node by returning. - Loop through all NodePaths in the
referencedPathsarray, and replace them with the current VariableDeclarator ‘s initial value (path.node.init) - After finishing the loop, remove the original VariableDeclarator node since it has no further use.
The babel implementation is shown below:
Babel Deobfuscation Script
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 | JAVASCRIPT |
After processing the obfuscated script with the babel plugin above, we get the following result:
Post-Deobfuscation Result
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 | JAVASCRIPT |
And the code is restored. Even better than the original actually, since we substituted in the url variable too!
Conclusion
Substitution of constant variables is a must-know deobfuscation technique. It’ll usually be one of your first steps in the deobfuscation, combined with constant folding. If you would like to learn about constant folding, you can read my article about it here.
This article also gave a nice introduction to one of the useful Babel API methods. Unfortunately, there isn’t much good documentation out there aside from the Babel Plugin Handbook. However, you can discover a lot more useful features Babel has to offer by reading its source code, or using the debugger of an IDE to list and test helper methods (the latter of which I personally prefer 😄).
If you’re interested, you can find the source code for all the examples in this repository.
Okay, that’s all I have for you today. I hope that this article helped you learn something new. Thanks for reading, and happy reversing!
-------------------------‘’
Preface
This article assumes a preliminary understanding of Abstract Syntax Tree structure and BabelJS. Click Here to read my introductory article on the usage of Babel.
Definitions
Both dead code and unreachable code are obfuscation techniques relying on the injection of junk code that does not alter the main functionality of a program. Their only purpose is to bloat the appearance of the source code to make it more confusing for a human to analyze. Though being similar, there’s a slight difference between the two.
What is Dead Code?
Dead code is a section of code that is executed, but its results are never used in the rest of the program. In addition to increasing the file size, dead code also increases the program runtime and CPU usage since it is being executed.
What is unreachable code?
Unreachable code is a section of code that is never executed, since there is no existing control flow path that leads to its execution. This results in an increase in file size, but shouldn’t affect the runtime of the program since its contents are never executed.
Examples
Example 1: [Dead Code] Unused Variables and Functions
An unused variable/function is something that is declared (and often, but not always, initialized), but is never used in the program. Therefore, for a variable to be unused, it must:
- Be constant, and
- Have no references
The following obfuscated script contains many of them:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 | JAVASCRIPT |
Analysis Methodology
Let’s begin our analysis by pasting the obfuscated script into AST Explorer
A view of the obfuscated code in AST Explorer
We can observe from the AST structure that each new variable creation results in the creation of one of two types of nodes:
-
A VariableDeclaration, for variables assigned with
let,var, andconst. 2. Each of these VariableDeclarations contains an array of VariableDeclarators. It is the VariableDeclarator that actually contains the information of the variables, including itsidandinitvalues. So, we can make VariableDeclarator nodes our focus of interest to avoid unnecessary extra traversals. -
A FunctionDeclaration, for functions declared with a function statement.
Based on this, we can deem our target node types of interest to be VariableDeclarator and FunctionDeclaration.
Recall that we want to identify all constant variables and non-referenced variables, then remove them. It’s important to note that variables in different scopes (e.g. local vs. global), may share the same name but have different values. So, we cannot simply base our solution on how many times a variable name occurs in a program.
This would be a convoluted process if not for Babel’s ‘Scope’ API. I won’t dive too deep into the available scope APIs, but you can refer to the Babel Plugin Handbook to learn more about them. In our case, the scope.getBinding(${identifierName}) method will be incredibly useful for us, as it directly returns information regarding if a variable is constant and all of its references (or lack thereof).
We can use our observations to construct the following deobfuscation logic:
- Traverse the AST for VariableDeclarators and FunctionDeclarations. Since both node types have both have the
idproperty, we can write a single plugin for both.- Tip: To write a function that works for multiple visitor nodes, we can add an
|seperating them in the method name as a string like this:"VariableDeclarator|FunctionDeclaration"
- Tip: To write a function that works for multiple visitor nodes, we can add an
- Use the
path.scope.getBinding(${identifierName})method with the name of the current variable as the argument. - If the method returns
constantastrueandreferencedasfalse, the declaration is considered to be dead code and can be safely removed withpath.removed()
The babel implementation is shown below:
Babel Implementation
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 | JAVASCRIPT |
After processing the obfuscated script with the babel plugin above, we get the following result:
Post-Deobfuscation Result
1 2 3 4 5 6 7 8 9 10 11 12 | JAVASCRIPT |
And all non-referenced variables are restored.
Extra: By manual analysis, you can probably realize that all the variables declared above the sayHello function can have their values substituted in place of their identifiers inside of the console.log statement. How to accomplish that is outside the scope of this article. But, if you’re interested in learning how to do it, you can read my article about it here.
Example 2: [Dead Code] Empty Statements
An empty statement is simply a semi-colon (;) with no same-line code before it. This script is littered with them:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | JAVASCRIPT |
The presence of empty statements doesn’t really add much to obfuscation, but removing them will still remove unnecessary noise and optimize the appearance.
Analysis Methodology
We begin by pasting the example obfuscated script into AST Explorer
A view of the obfuscated code in AST Explorer
We can observe that the top-level view is polluted by EmptyStatement nodes, causing a slight inconvenience when trying to navigate through the AST structure.
The deobfuscator logic is very simple:
- Traverse the AST for EmptyStatement nodes.
- When one is encountered, delete it with
path.remove()
The babel implementation is shown below:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 | JAVASCRIPT |
After processing the obfuscated script with the babel plugin above, we get the following result:
Post-Deobfuscation Result
1 2 3 | JAVASCRIPT |
And all of the useless EmptyStatements are now removed, enabling easier reading and navigation through the AST.
Example 3: [Unreachable Code] If Statements and Logical Expressions
Let’s take the following ‘obfuscated’ code snippet as an example:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 | JAVASCRIPT |
This is an extremely simple example, especially since the console.log calls tell you exactly what runs and what doesn’t. Keep in mind that code you find in the wild will probably be layered with other obfuscation techniques too. However, this is a good example for understanding the core concept. Rest assured though: the method I’ll discuss should still be universal to all types of unreachable code obfuscation.
Analysis Methodology
As always, we start our analysis by pasting the code into AST Explorer
A view of the obfuscated code in AST Explorer
We can see that at the top level, the file consists of IfStatements and an ExpressionStatement. If we expand the ExpressionStatement, we can see that ternary operator logical expressions are actually of type ConditionalExpression. Expanding an IfStatement and a ConditionalExpression for comparison, we can notice some similarities:
Comparison of IfStatement vs. ConditionalExpression nodes
We can see that aside from their type, both an IfStatement and a ConditionalExpression both have the exact same structure. That is, both contain:
-
A
testproperty, which is the test condition. It will either evaluate to true or false. -
A
consequentproperty, which contains the code to be executed iftestevaluates to a truthy value. -
A
alternateproperty, which contains the code to be executed iftestevaluates to a falsy value.- Note: This property is optional, since an If Statement need not be accompanied by an else.
For our deobfuscator, we’ll make use of one of the babel API methods: NodePath.evaluateTruthy().
This method takes in a path, then evaluates its node. If the node evaluates to a truthy value, the method returns true. If the node evaluates to a falsy value, the method returns false. See: Truthy Values vs. Falsy Values
The steps for creating the deobfuscator are as follows:
- Traverse the AST for IfStatements and ConditionalExpressions. Since both node types have the same structure, we can write a single plugin for both.
- Tip: _To write a function that works for multiple visitor nodes, we can add an _
|seperating them in the method name as a string like this:"IfStatement|ConditionalExpression"
- Tip: _To write a function that works for multiple visitor nodes, we can add an _
- When one is encountered, use the
NodePath.evaluateTruthy()method on thetestproperty’s NodePath. - if the
NodePath.evaluateTruthy()method returns true:- Replace the path with the contents of
consequent. - (Optional) If the consequent is contained within a BlockStatement (curly braces), we can replace it with the
consequent.bodyto get rid of the curly braces.
- Replace the path with the contents of
- if the
NodePath.evaluateTruthy()method returns false:- If the
alternateproperty exists, replace the path with its contents. - (Optional) If the alternate is contained within a BlockStatement (curly braces), we can replace it with the
alternate.bodyto get rid of the curly braces.
- If the
The babel implementation is shown below:
Babel Implementation
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 | JAVASCRIPT |
After processing the obfuscated script with the babel plugin above, we get the following result:
Post-Deobfuscation Result
1 2 3 4 | JAVASCRIPT |
And only the code which is designed to execute persists, a full restoration of the code!
Conclusion
Cleaning up dead/unreachable code is an essential component of the deobfuscation process. I would recommend doing it at least twice per program:
-
Firstly, at the start of the deobfuscation process. This will make the obfuscated script much more manageable to navigate, as you can focus on the important parts of the program instead of junk code
-
At the end of the deobfuscation process, as part of the clean-up stage. Simplifying obfuscated code tends to reveal more dead code that can be removed, and removing it at the end results in a cleaner final product.
This article also gave a nice introduction to one of the useful Babel API methods. Unfortunately, there isn’t much good documentation out there aside from the Babel Plugin Handbook. However, you can discover a lot more useful features Babel has to offer by reading its source code, or using the debugger of an IDE to list and test helper methods (the latter of which I personally prefer 😄).
If you’re interested, you can find the source code for all the examples in this repository.
Okay, that’s all I have for you today. I hope that this article helped you learn something new. Thanks for reading, and happy reversing!
复制粘贴,以免失效。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










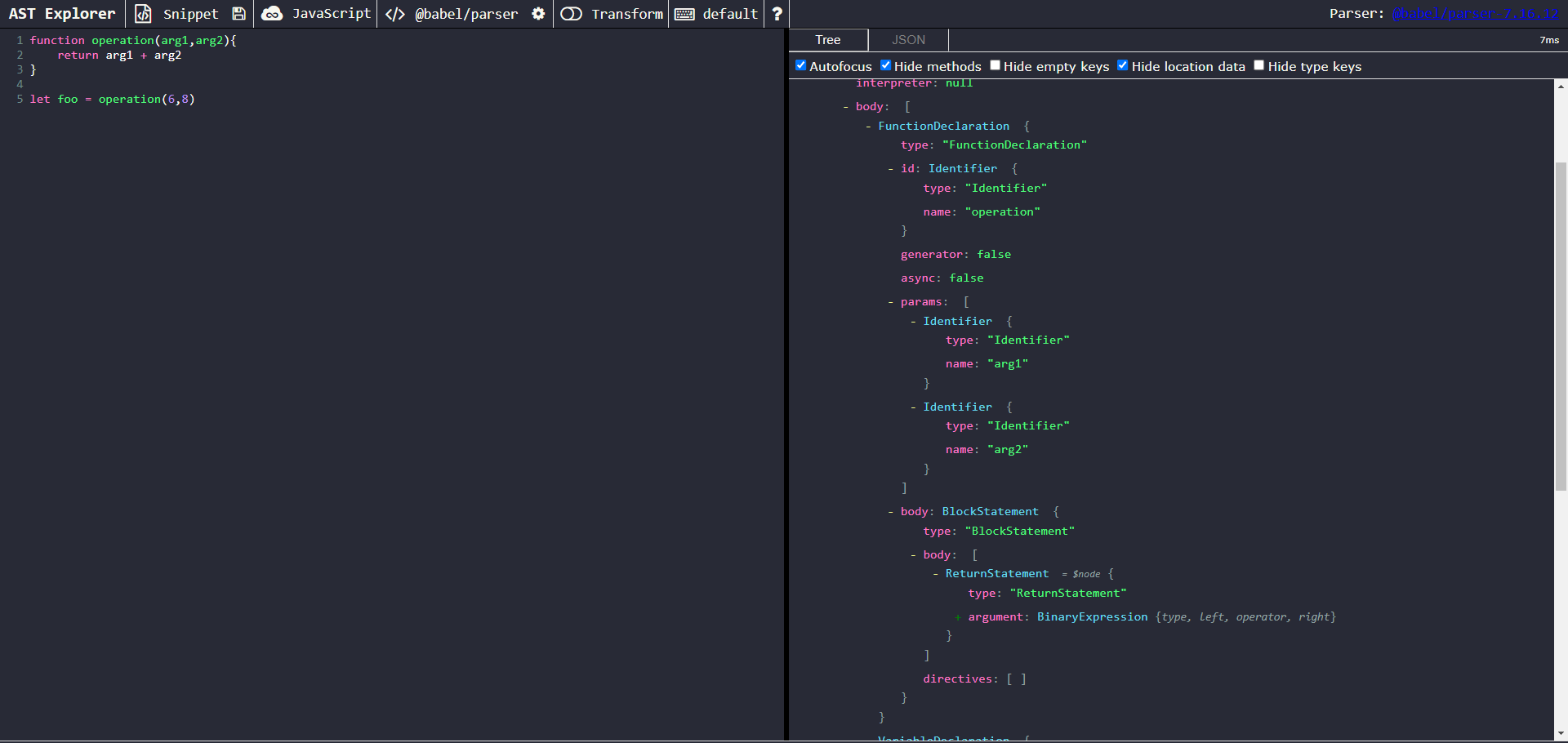{kind=link}
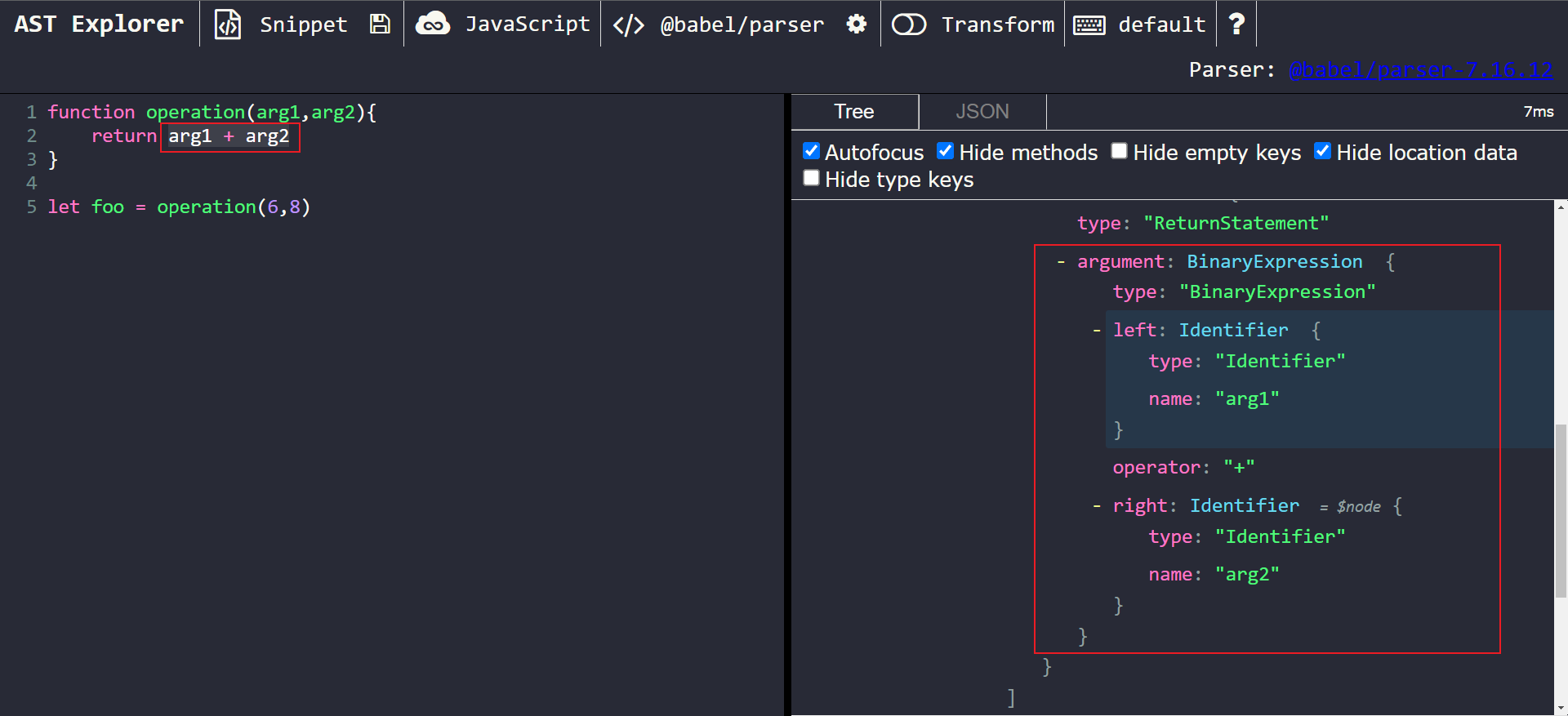{kind=link}
{kind=link}
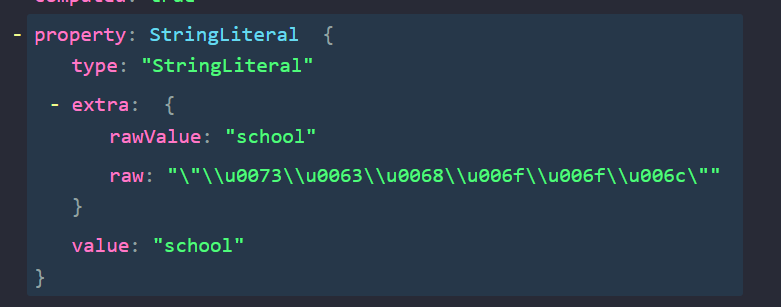{kind=link}
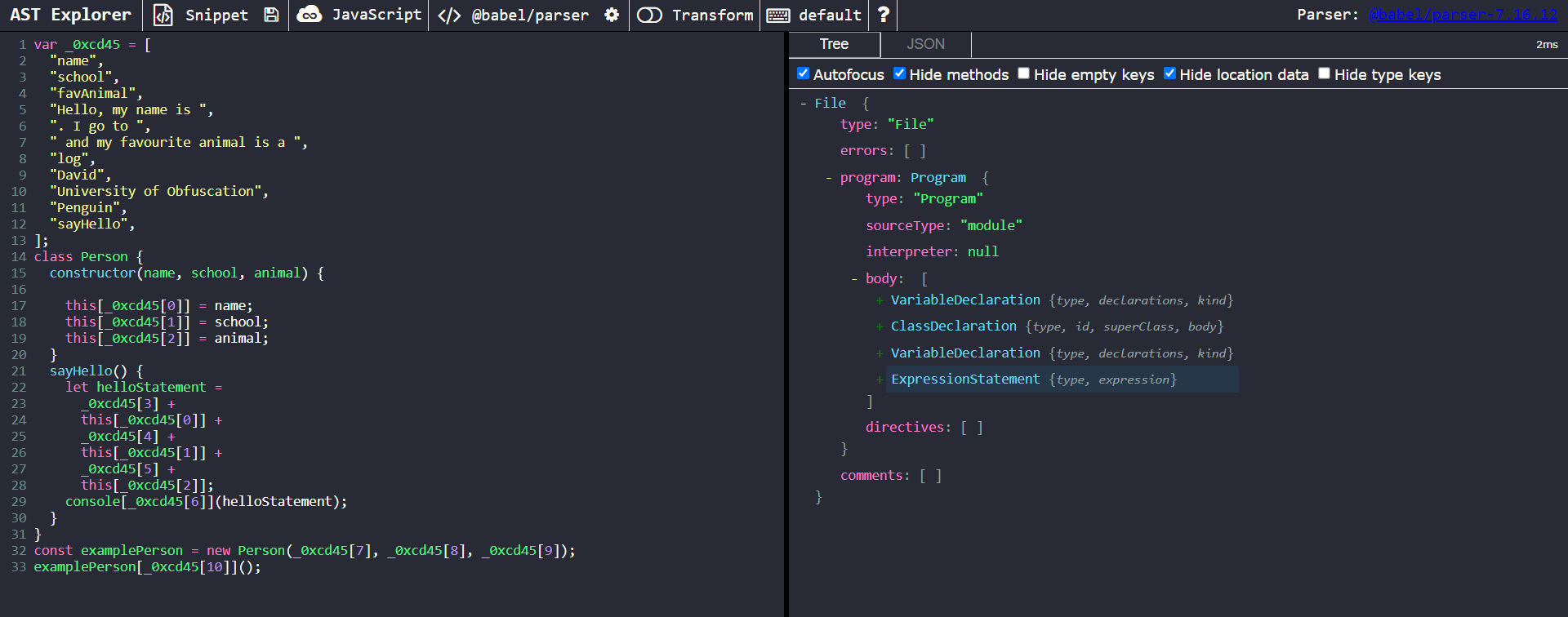{kind=link}
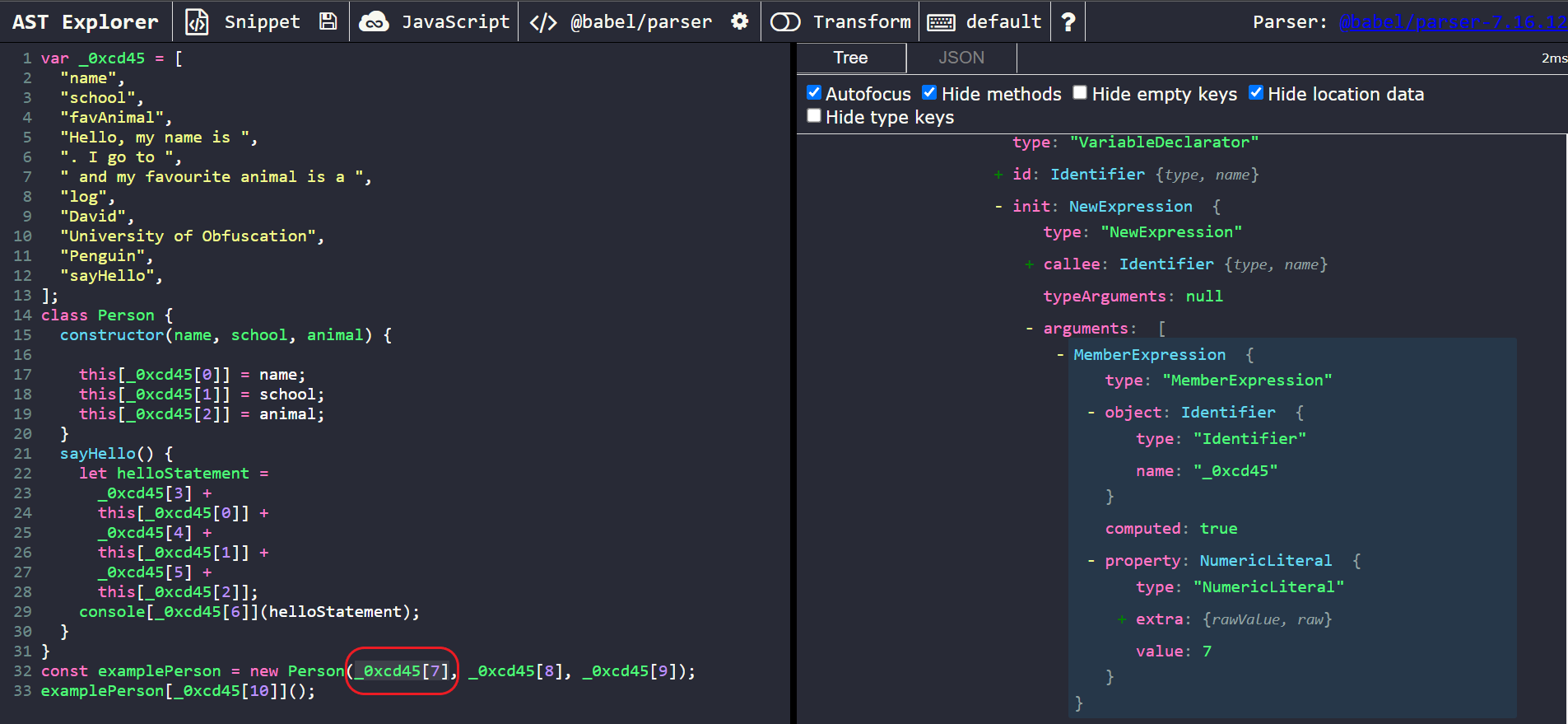{kind=link}
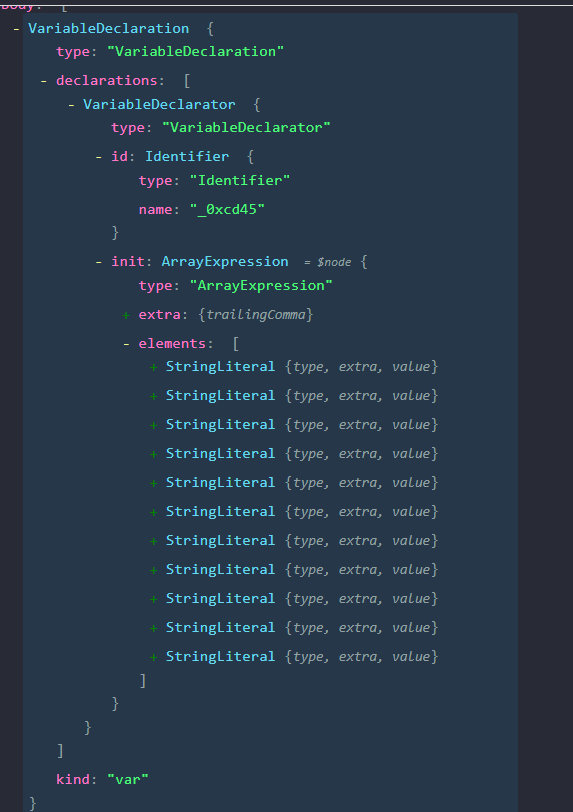{kind=link}
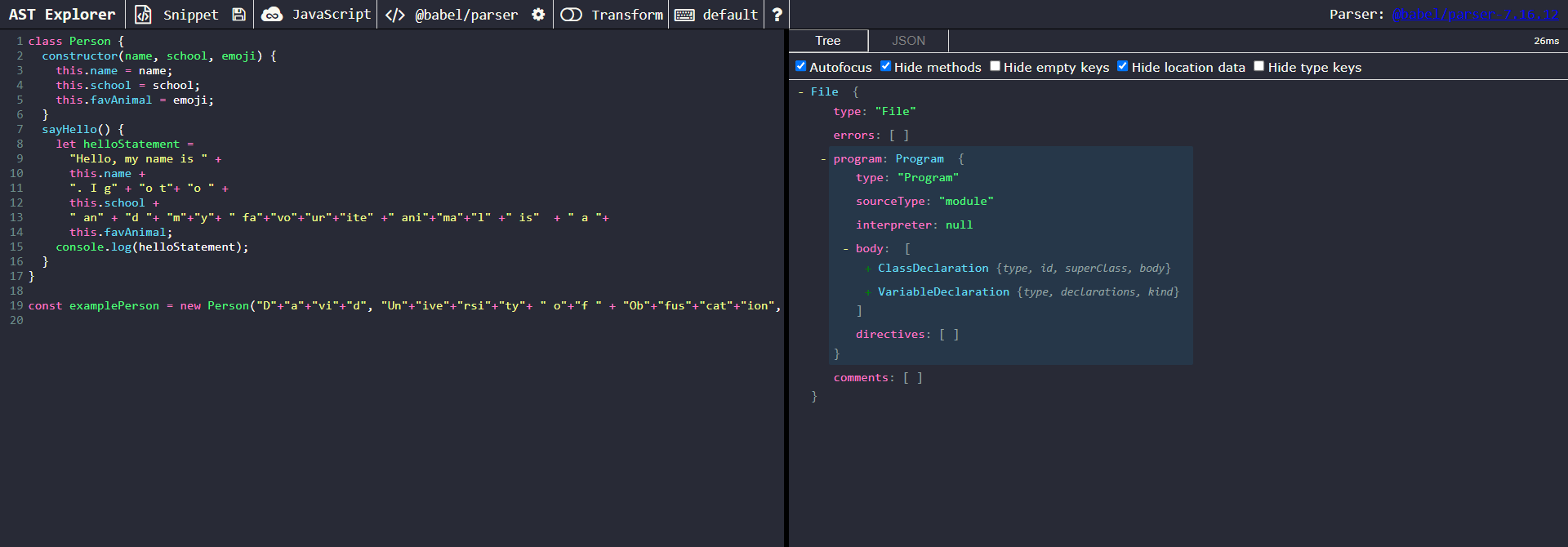{kind=link}
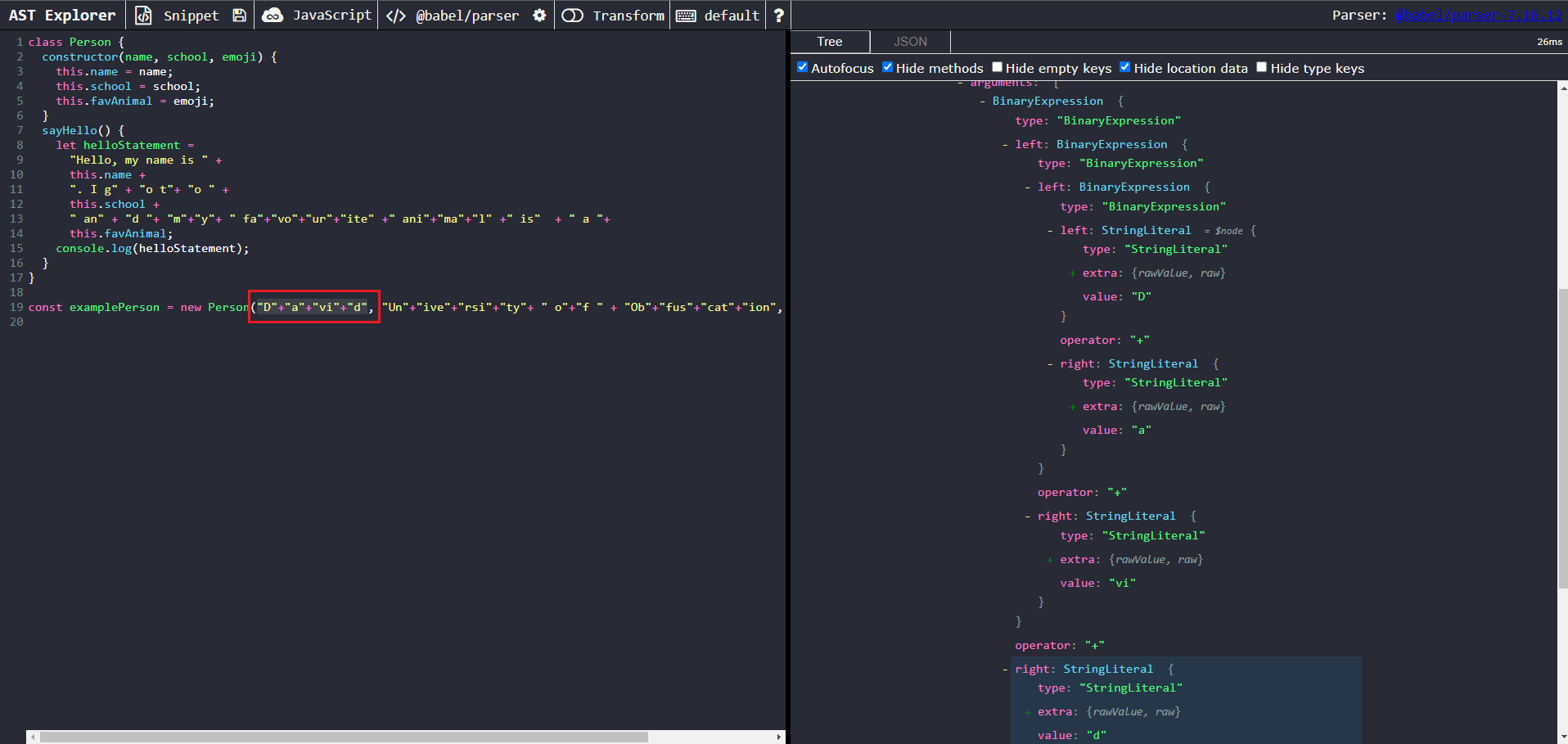{kind=link}
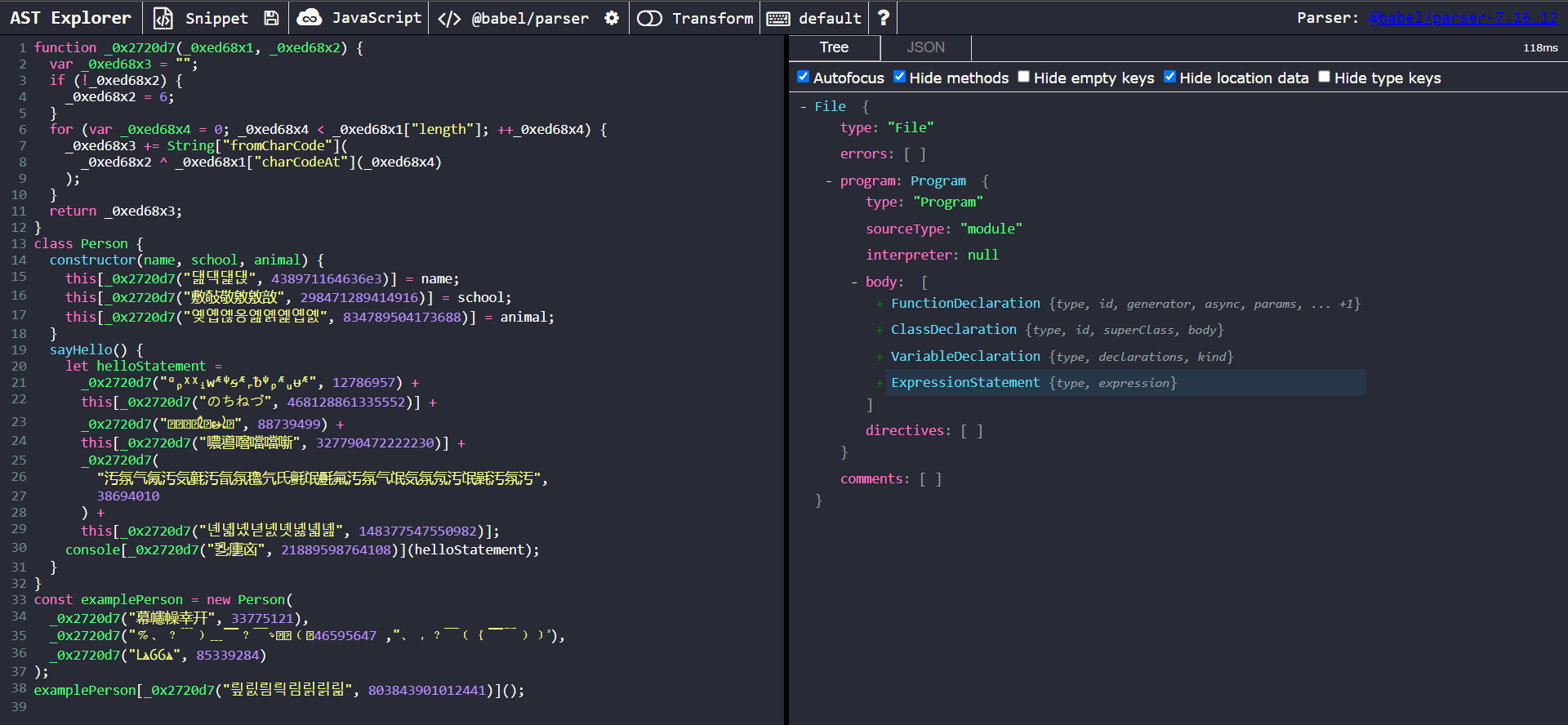{kind=link}
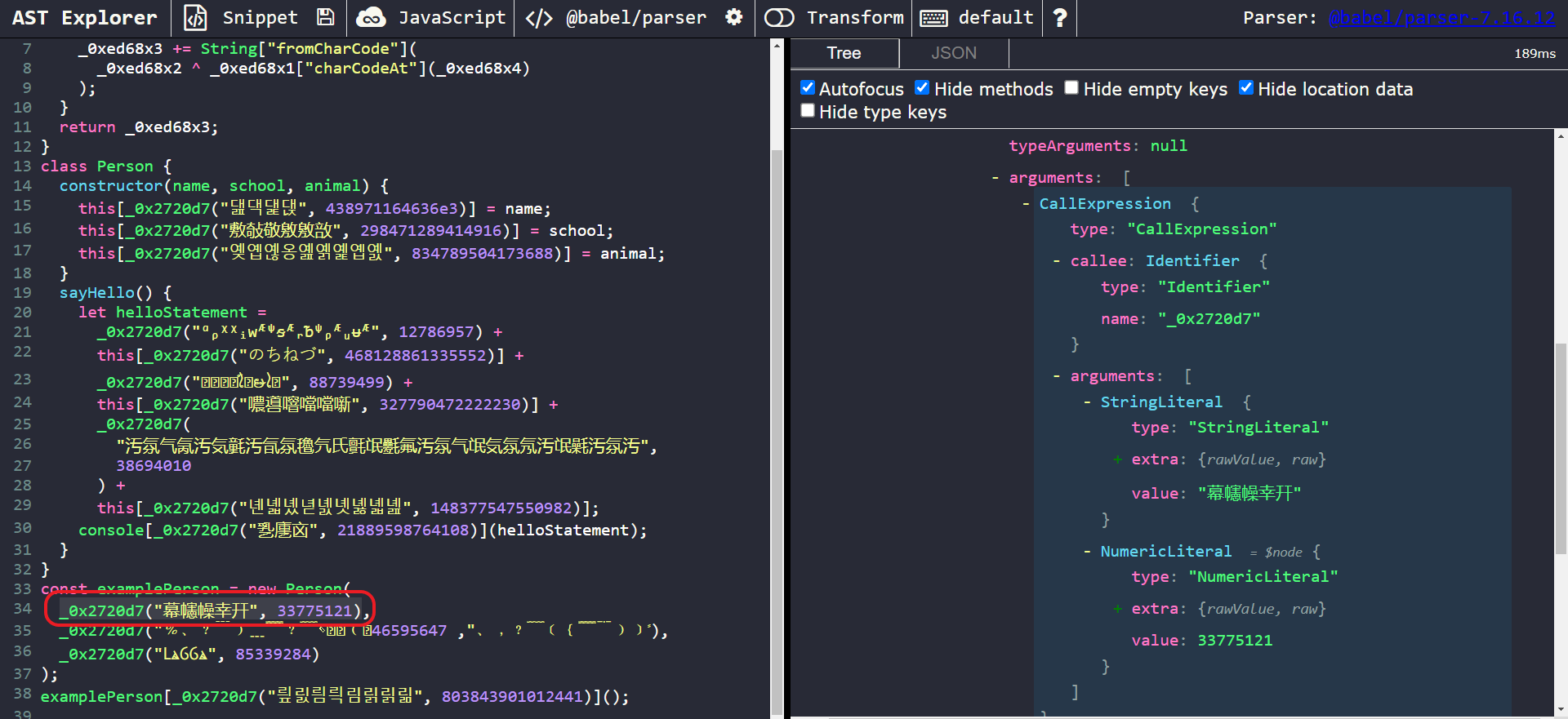{kind=link}
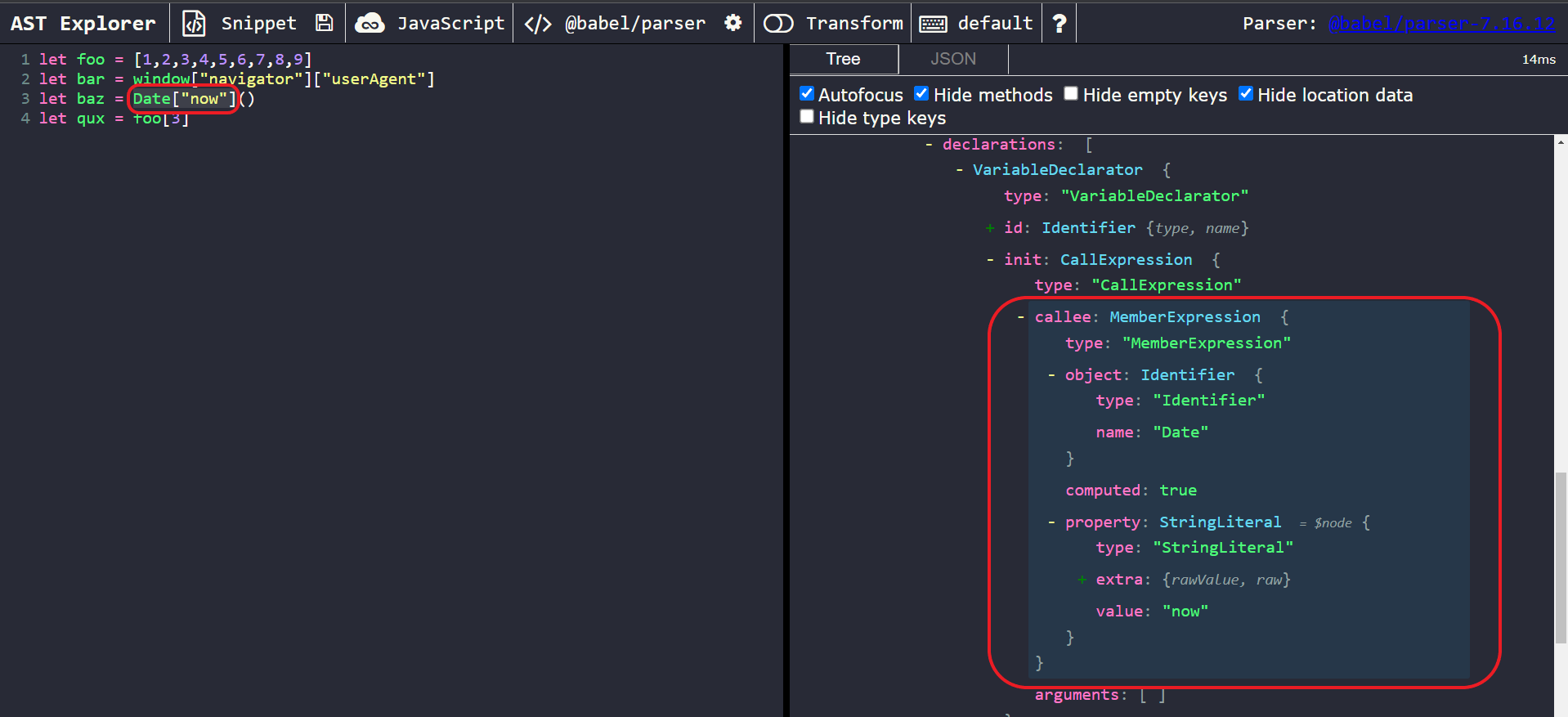{kind=link}
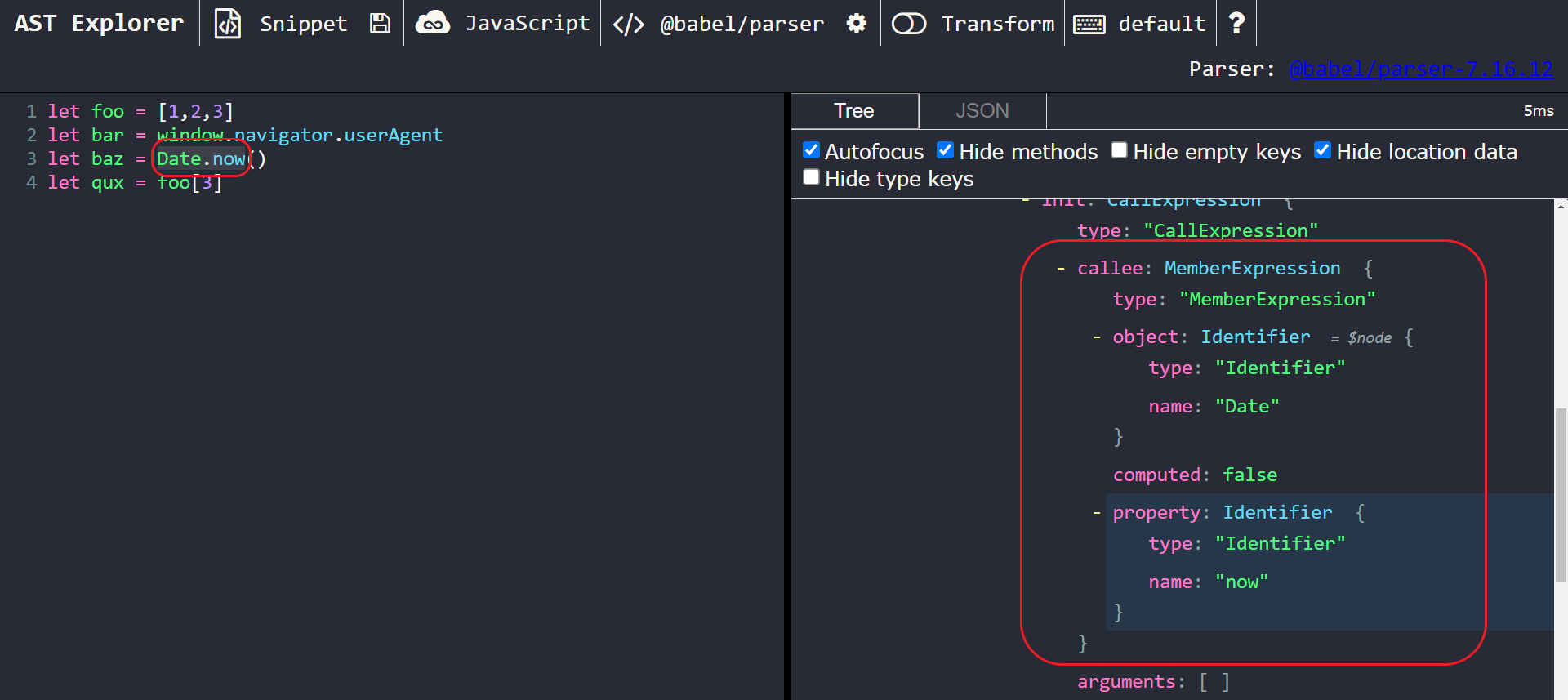{kind=link}
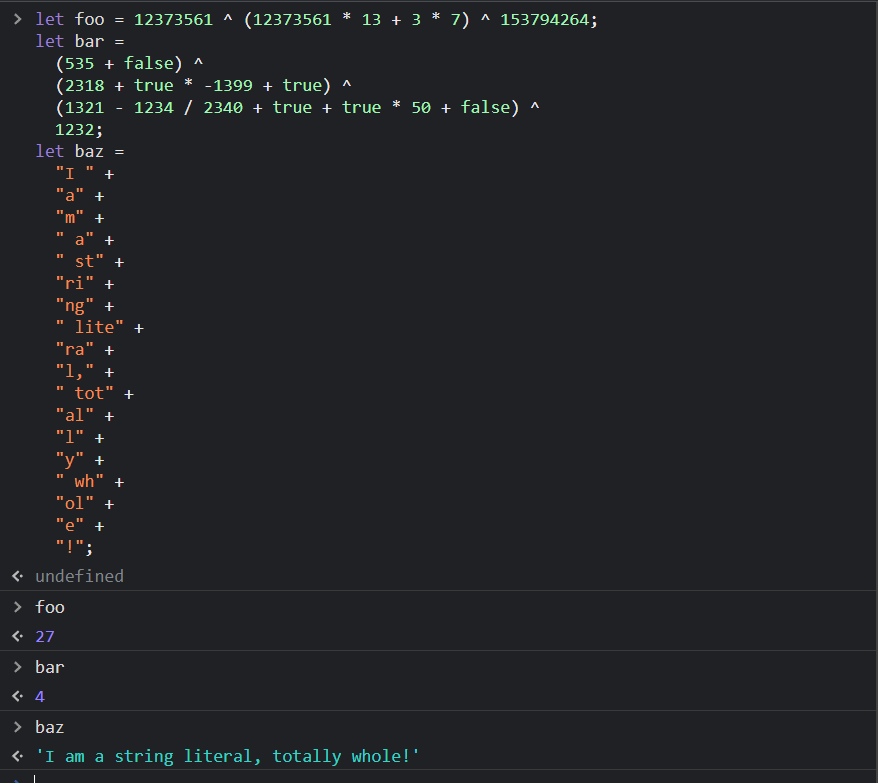{kind=link}
{kind=link}
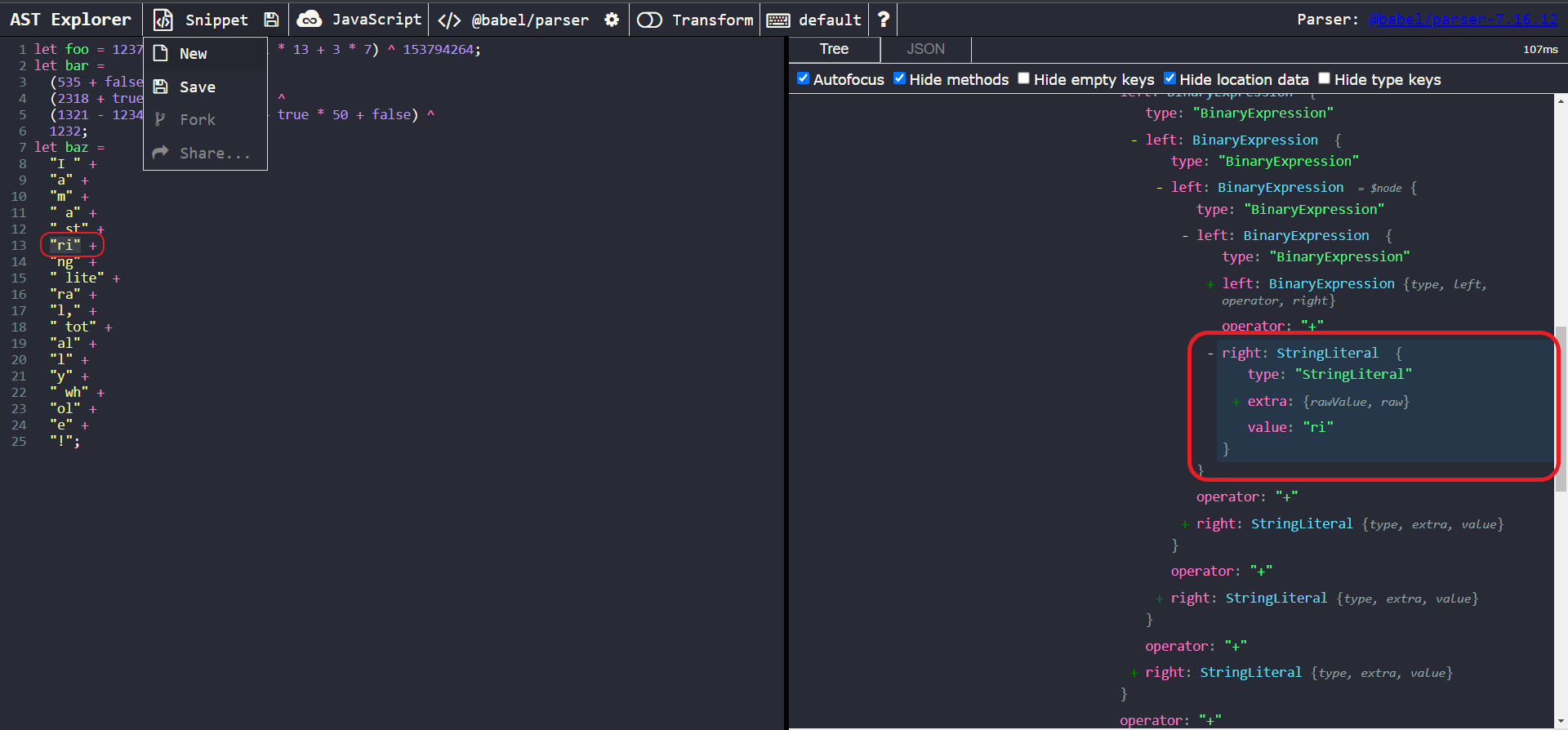{kind=link}
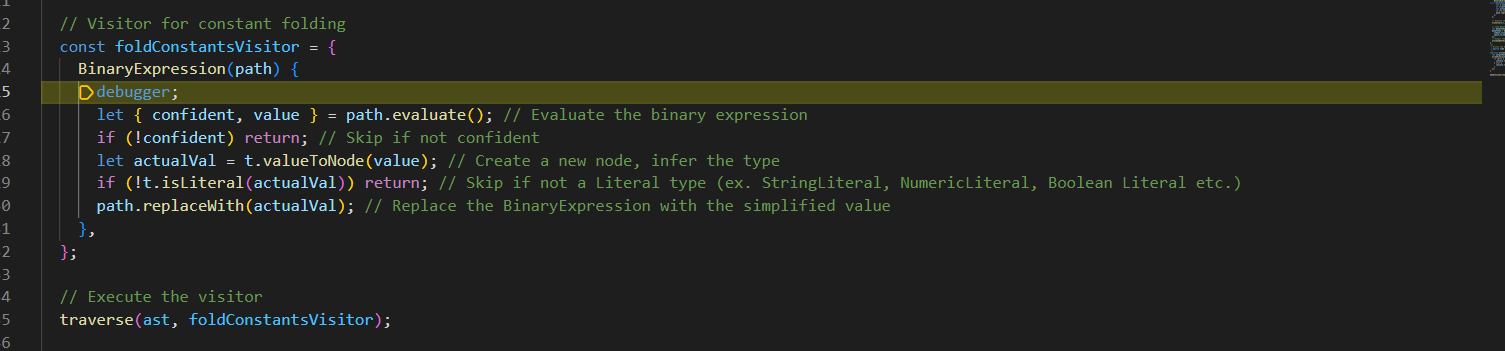{kind=link}
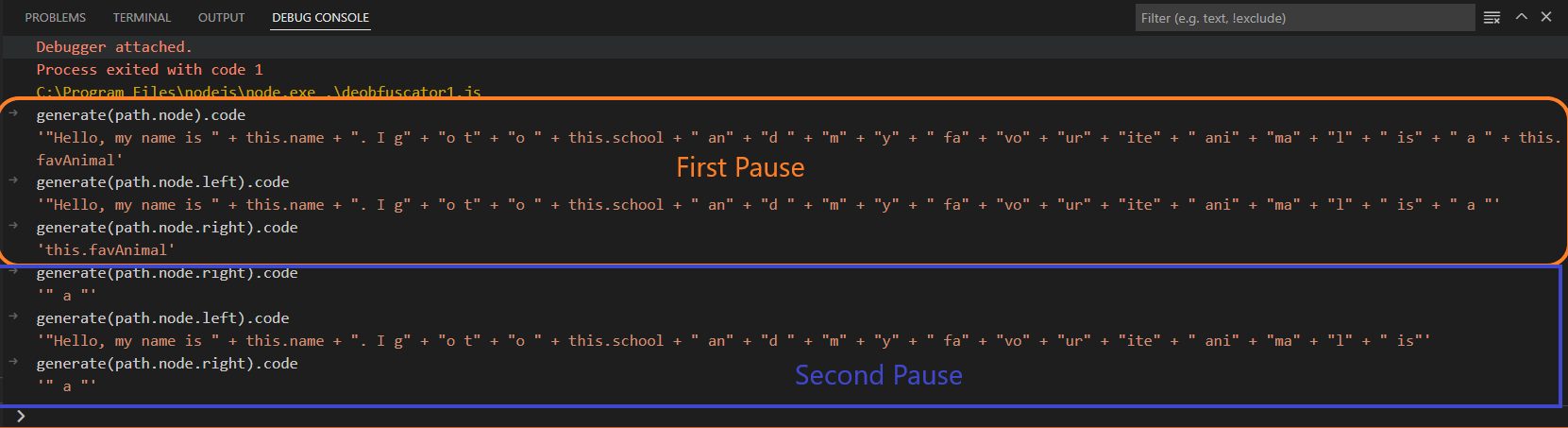{kind=link}
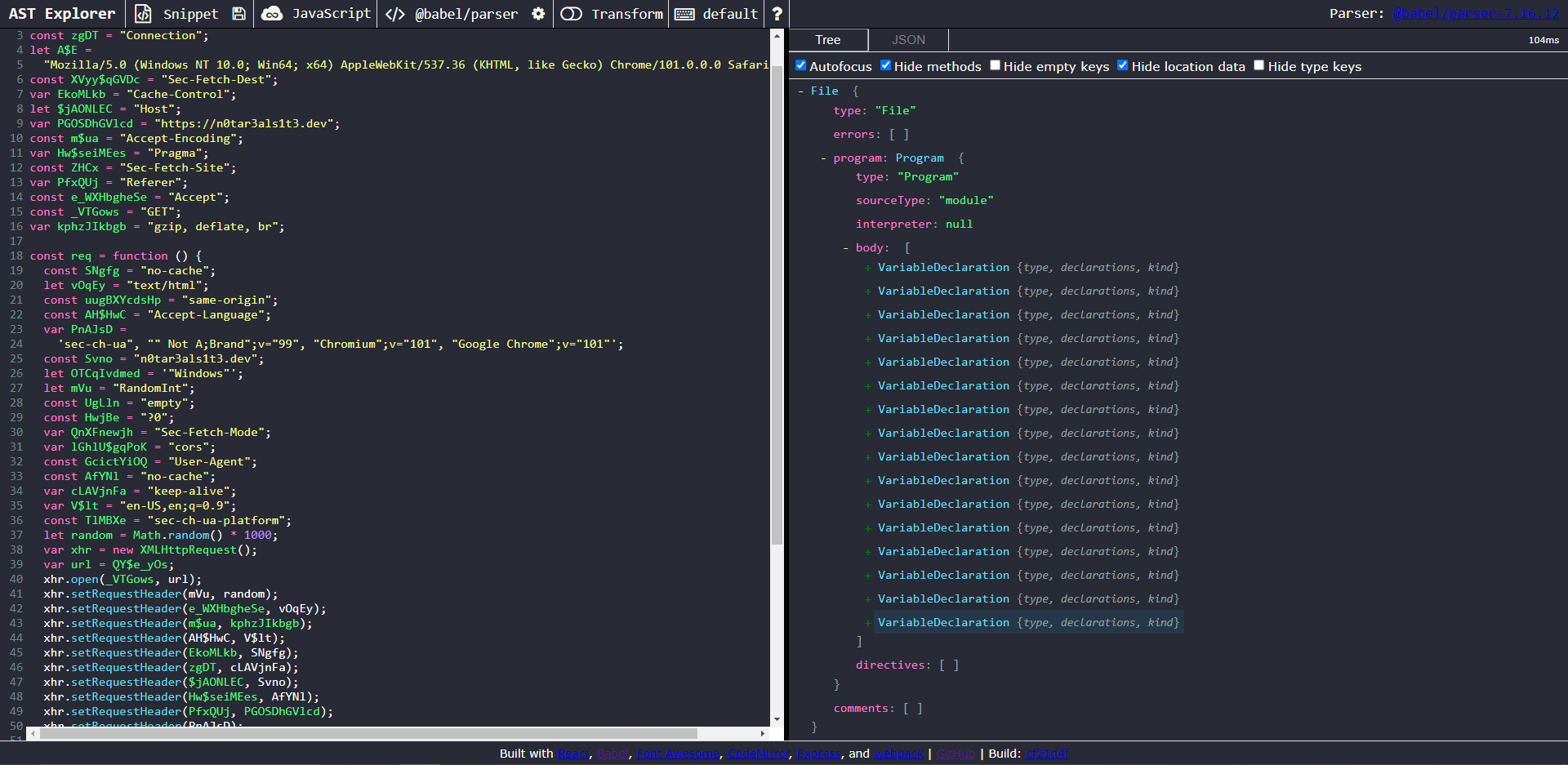{kind=link}
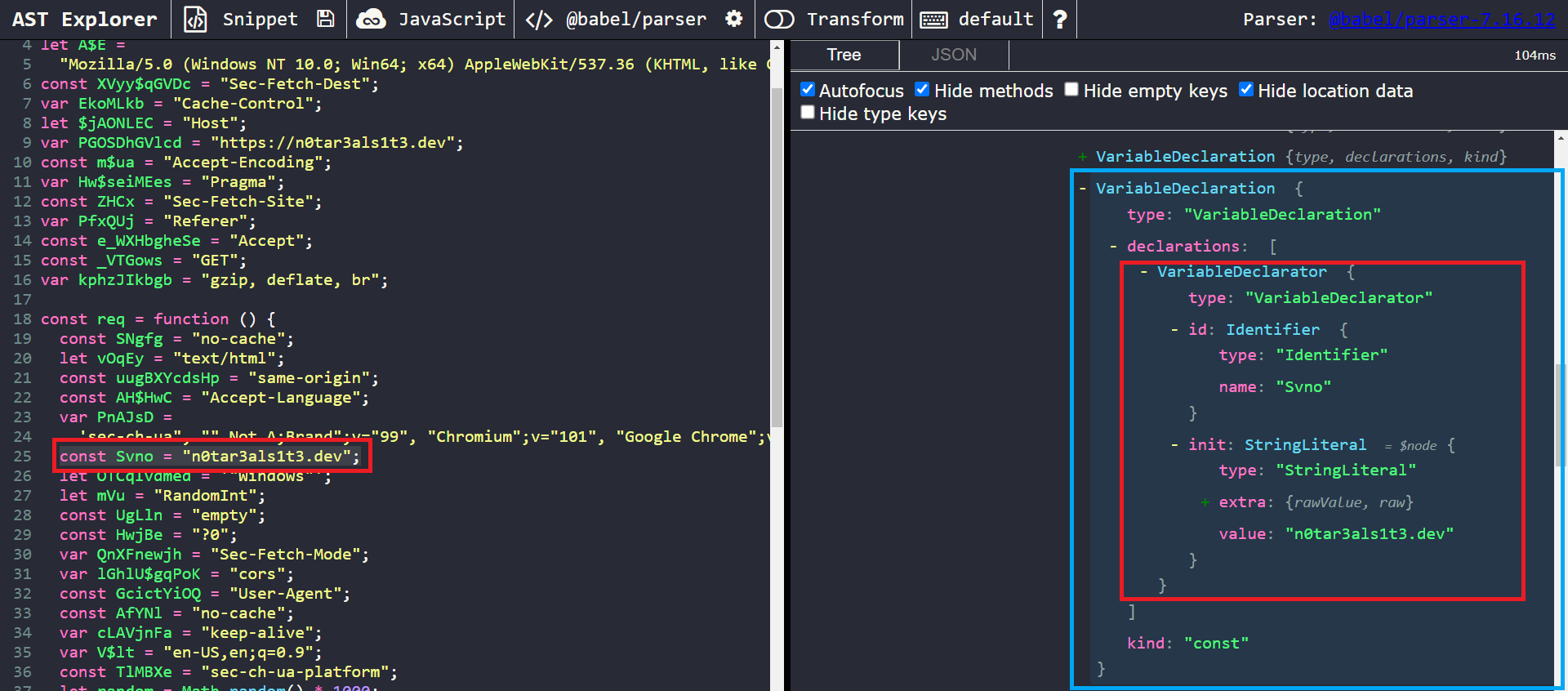{kind=link}
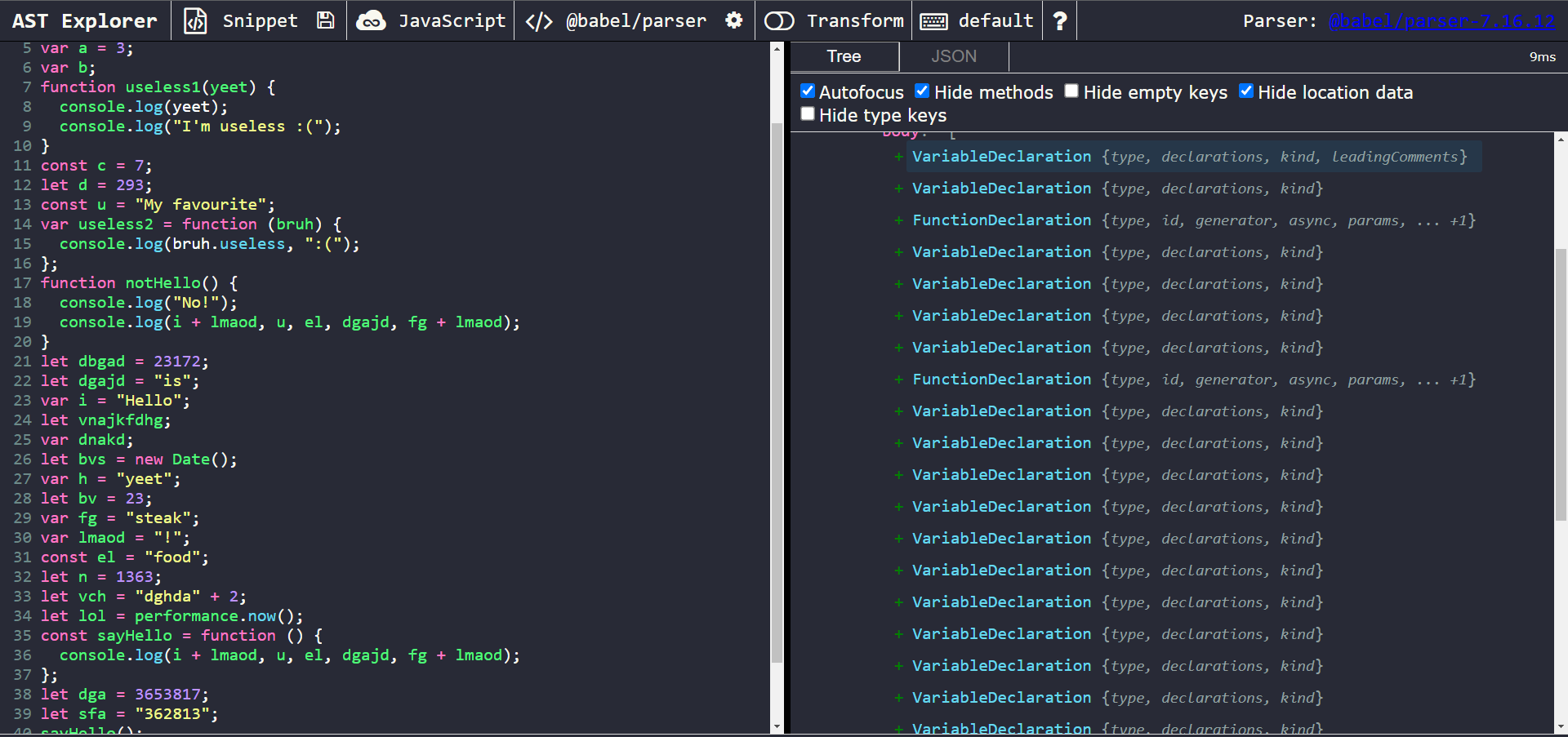{kind=link}
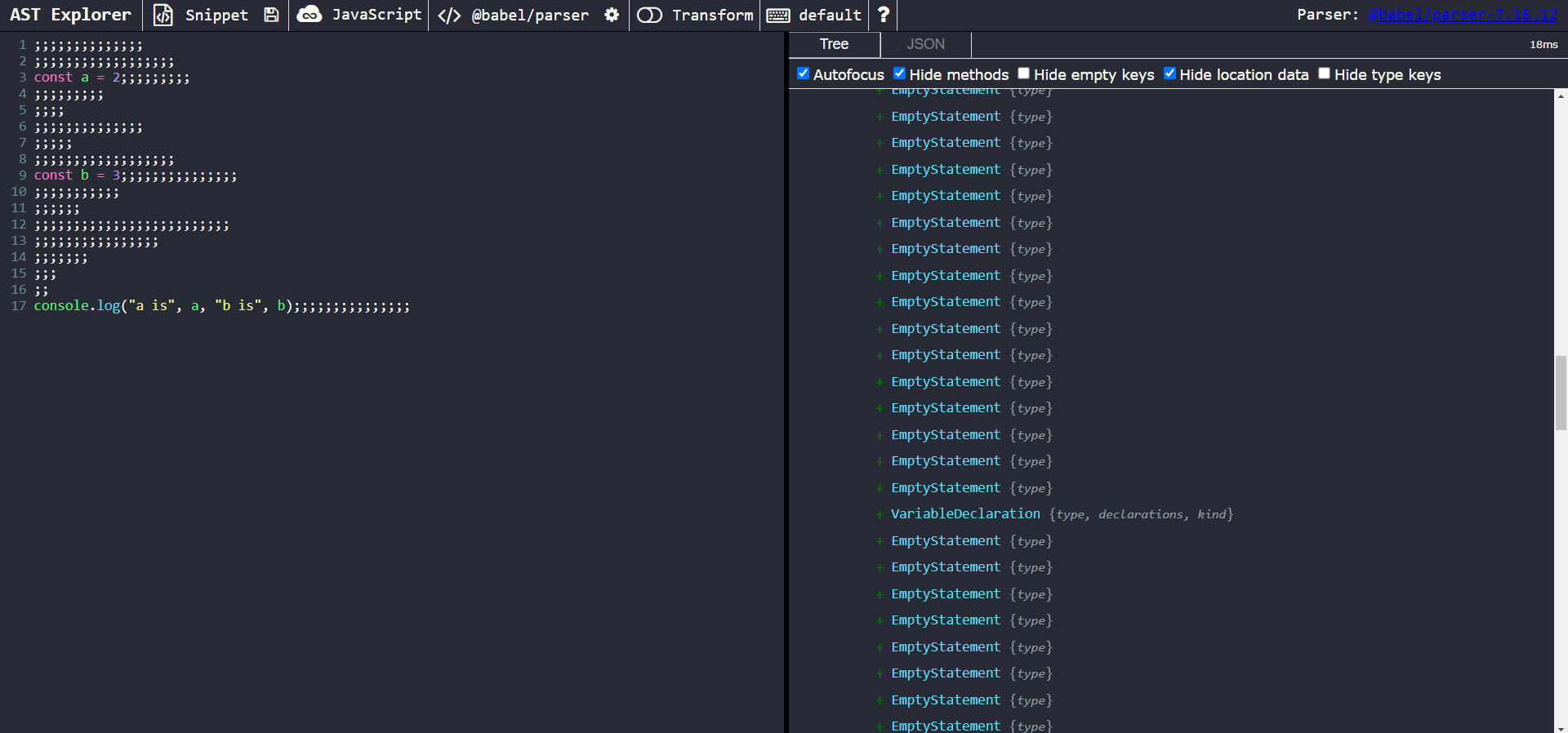{kind=link}
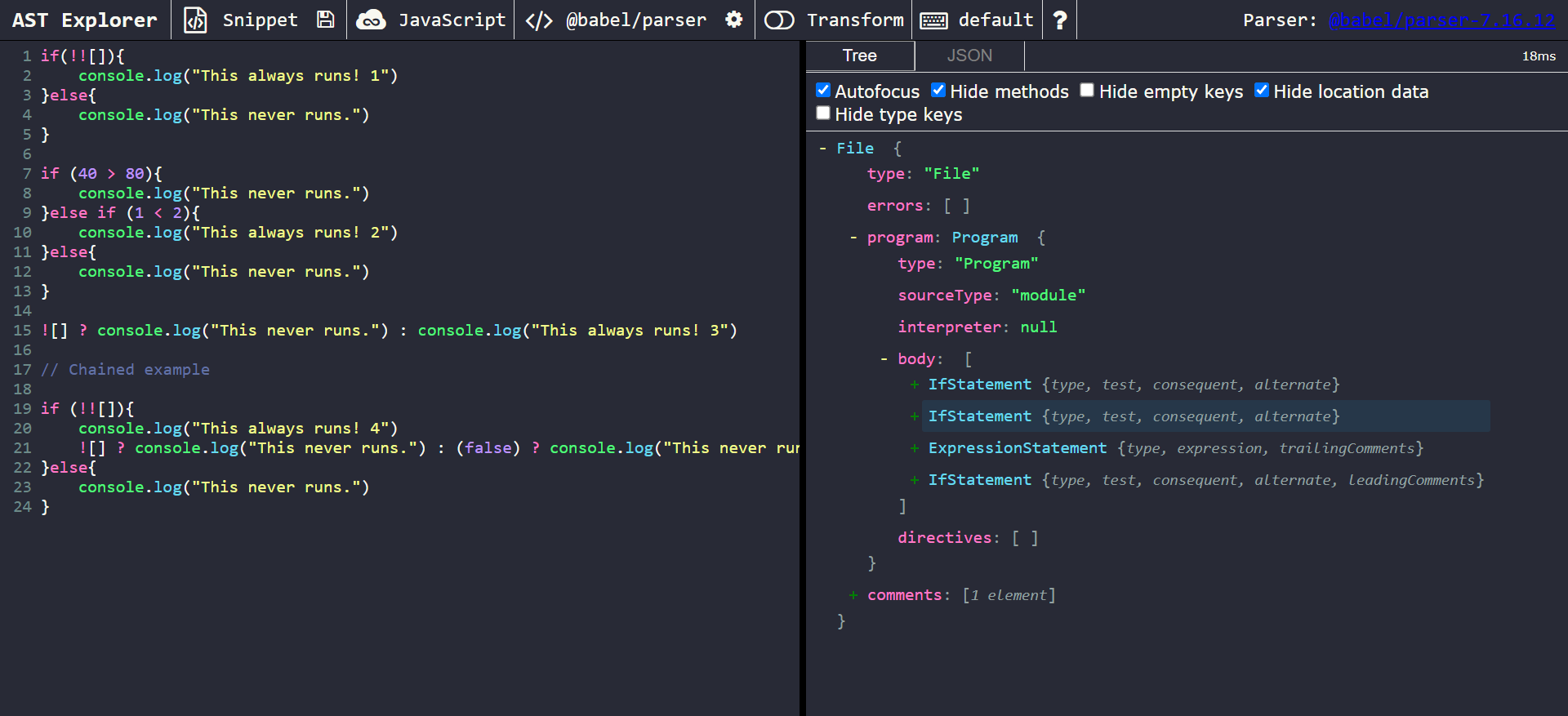{kind=link}
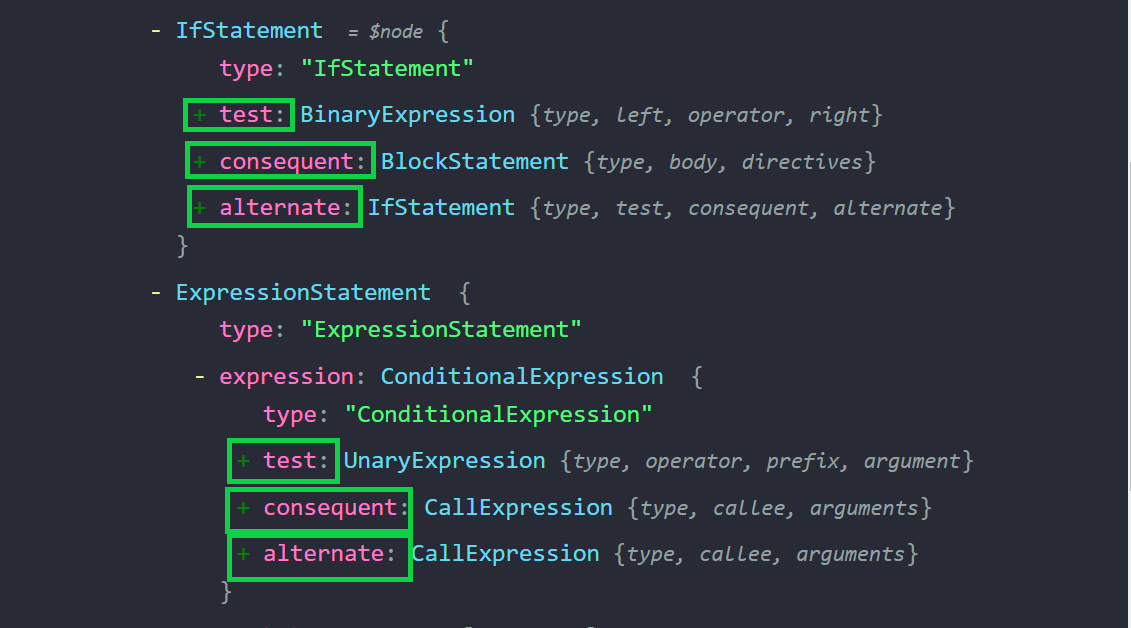{kind=link}