







目录
参考资料
梯度提升:
https://borgwang.github.io/ml/2019/04/12/gradient-boosting.html
XGBoost文档:
https://xgboost.readthedocs.io/
代码:
GitHub - Dod-o/Statistical-Learning-Method_Code: 手写实现李航《统计学习方法》书中全部算法
XGBoost论文:
https://arxiv.org/pdf/1603.02754.pdf
推导视频:
https://www.bilibili.com/video/BV1wE411J7tG?p=2
本文配套代码:
AdaBoost代码数据集+注释与修改.zip-机器学习文档类资源-CSDN文库![]() https://download.csdn.net/download/lagoon_lala/44805167
https://download.csdn.net/download/lagoon_lala/44805167
什么是提升方法
强可学习(strongly learnable)等价弱可学习(weakly learnable)
| 强可学习: 一个概念(一个类),如果存在一个多项式的学习算法能够学习它,并且正确率很高 弱可学习:一个概念,如果存在一个多项式的学习算法能够学习它,学习的正确率仅比随机猜测略好 |
“弱学习算法”提升(boost)为“强学习算法”(Boosting 是集成学习算法)
其基本原理: 串行生成一系列弱学习器(weak learner),这些弱学习器直接通过组合到一起构成最终的模型。
| 提升方法就是得到一系列弱分类器(又称为基本分类器),然后组合(加权多数表决)这些弱分类器,构成一个强分类器。 大多数的提升方法都是改变训练数据的概率分布(训练数据的权值分布),针对不同的训练数据分布学习一系列弱分类器。 |
AdaBoost代码实践
Adaboost即二类分类学习方法:
模型为加法模型(加权多数表决+基分类器线性组合)、
损失函数为指数函数、
学习算法为前向分步算法.
修改数据集读取地址
| print('start read transSet') trainDataList, trainLabelList = loadData('./Mnist/mnist_train.csv') # 获取测试集 print('start read testSet') testDataList, testLabelList = loadData('./Mnist/mnist_test.csv') |
模型除了获取数据之外主要分为两个部分:
| #创建提升树(训练) tree = createBosstingTree(trainDataList[:10000], trainLabelList[:10000], 40) |
| #测试 accuracy = model_test(testDataList[:1000], testLabelList[:1000], tree) |
createBosstingTree
创建算法依据“8.1.2 AdaBoost算法” 算法8.1(P156)
输入:训练数据集T={(x1,y1),(x2,y 2),…,(xN,yN)},其中xi∊x⊆R^n,yi∊γ={-1,+1};弱学习算法;
输出:最终分类器G(x)。
(1)初始化训练数据的权值分布
假设训练数据集具有均匀的权值分布:
$$ D_{1}=\left(w_{11}, \cdots, w_{1 i}, \cdots, w_{1 N}\right), \quad w_{1 i}=\frac{1}{N}, \quad i=1,2, \cdots, N $$
| #依据算法8.1步骤(1)初始化训练数据的权值分布D为1/N D = [1 / m] * m |
其中, m=N为训练集样本数量;
[ ] * m是浅拷贝, 再用等号复制到D, 即[1 / m, 1 / m, 1 / m, 1 / m]. 参考:
https://blog.csdn.net/weixin_41888257/article/details/108449289
(2)对m=1,2,…,M
(a)使用具有权值分布Dm的训练数据集学习,得到基本分类器
$$ G_{m}(x): \mathcal{X} \rightarrow\{-1,+1\} $$
| #得到当前层的提升树 curTree = createSigleBoostingTree(trainDataArr, trainLabelArr, D) |
此处利用前向分步算法, 将对整个模型的优化法(同时求解从m=1到M所有参数βm, γm)转化为每一步只学习一个基函数及其系数的优化问题(逐次求解各个βm, γm)(串行集成学习), 逐步逼近优化目标(左式)
$$ \min _{\beta_{m},\gamma_{m}} \sum_{i=1}^{N} L\left(y_{i}, \sum_{m=1}^{M}\beta_{m} b\left(x_{i} ; \gamma_{m}\right)\right) \Rightarrow \min _{\beta, \gamma} \sum_{i=1}^{N} L\left(y_{i}, \beta b\left(x_{i} ; \gamma\right)\right) $$
(b)计算Gm(x)在训练数据集上的分类误差率
即分类误差率=被该学习器Gm(x)误分类样本的权值之和
$$ e_{m}=\sum_{i=1}^{N} P\left(G_{m}\left(x_{i}\right) \neq y_{i}\right)\\=\sum_{i=1}^{N} w_{m i} I\left(G_{m}\left(x_{i}\right) \neq y_{i}\right) =\sum_{G_{m}\left(x_{i}\right) \neq y_{i}} w_{m i}$$
其中, w_mi表示第m个基学习器中第i个实例的权值
在createSigleBoostingTree创建的单层提升树过程中, 通过calc_e_Gx计算
| #初始化分类误差率为0 e = 0 |
| #遍历所有样本的特征m for i in range(trainDataArr.shape[0]): if x[i] < div: #如果小于划分点,则预测为L #如果设置小于div为1,那么L就是1, #如果设置小于div为-1,L就是-1 predict.append(L) #如果预测错误,分类错误率要加上该分错的样本的权值(8.1式) if y[i] != L: e += D[i] elif x[i] >= div: #与上面思想一样 predict.append(H) if y[i] != H: e += D[i] #返回预测结果predict和分类错误率e #预测结果其实是为了后面做准备的,在式8.4中exp内部需要Gx |
(c)计算Gm(x)的系数
$$ \alpha_{m}=\frac{1}{2} \log \frac{1-e_{m}}{e_{m}} $$
(此处为自然对数ln)
学习器误差率\( e_{m} \)↓, 此基学习器在集成后学习器中的作用\( \alpha_{m} \) ↑
学习器误差率\( e_{m} \)<1/2, 此基学习器在集成后学习器中的作用\( \alpha_{m} \) >0
| #根据式8.2计算当前层的alpha alpha = 1/2 * np.log((1 - curTree['e']) / curTree['e']) |
其中curTree['e']代表Gm(x)在训练数据集上的分类误差率(b)
此处可以看作损失函数为指数损失函数时, 前向分步使损失最小
(d)更新训练数据集的权值分布
\( D_m\rightarrow D_{m+1} \)
$$ D_{m+1}=\left(w_{m+1,1}, \cdots, w_{m+1, i}, \cdots, w_{m+1, N}\right) \\ w_{m+1, i}=\frac{w_{m i}}{Z_{m}} \exp \left(-\alpha_{m} y_{i} G_{m}\left(x_{i}\right)\right), \quad i=1,2, \cdots, N\\= \begin{cases}\frac{w_{m i}}{Z_{m}} \mathrm{e}^{-\alpha_{m}}, & G_{m}\left(x_{i}\right)=y_{i} \\ \frac{w_{m i}}{Z_{m}} \mathrm{e}^{\alpha_{m}}, & G_{m}\left(x_{i}\right) \neq y_{i}\end{cases} $$
其中Zm为规范化因子
$$ Z_{m}=\sum_{i=1}^{N} w_{m i} \exp \left(-\alpha_{m} y_{i} G_{m}\left(x_{i}\right)\right) $$
误分类样本的权值↑,正确分类样本的权值↓
考虑到该式每次只更新D中的一个w,要循环进行更新直到所有w更新结束, 表达式会很复杂,所以该式以向量相乘的形式,一个式子将所有w全部更新完。
| #依据式8.4更新权值分布D D = np.multiply(D, np.exp(-1 * alpha * np.multiply(trainLabelArr, Gx))) / sum(D) |
np.multiply(trainLabelArr, Gx)代表exp中的\(\boldsymbol y G_{m}(\boldsymbol x)\),结果是一个行向量,内部为\( y_{i} G_{m}\left(x_{i}\right) \),长度均为样本个数
np.multiply () 函数用于数组或矩阵对应元素相乘,输出与相乘数组或矩阵的大小一致
np.exp(-1 * alpha * np.multiply(trainLabelArr, Gx)):上面求出来的行向量内部全体元素再乘以-αm,然后作为e的指数,只不过书上式子是一个数,这里是一个向量
D是一个行向量,取代了式中的\( w_{mi} \),然后D求和看作\( Z_m \) (此处比书上规范公式少了exp中的内容, 相当于用的是上一次的权值分布做规范化, 整体相差一个常数, 在计算该基学习器Gm的误差率em和基学习器系数α的时候, 由于不能满足使新的D成为一个概率分布, 会使基学习器的权重有微小偏差. 但在训练收敛后, 各样本权值趋向稳定, 上一次和这一次的D基本一致, 后续的基学习器不会产生太大影响)
按书上公式可以写作:
| #更新权值 D=np.multiply(D, np.exp(-1 * alpha * np.multiply(trainLabelArr, Gx))) #规范化 D = D / sum(D) |
书中的式子最后得出来一个数w,所有数w组合形成新的D
这里是直接得到一个向量,向量内元素是所有的w
该公式用矩阵表示:
$$ D_{m+1}=D_{m}\mathrm{e}^{-\alpha_{m}\boldsymbol y G_{m}(\boldsymbol x)}/Z_{m} $$
(3)构建基分类器的线性组合
$$ f(x)=\sum_{m=1}^{M} \alpha_{m} G_{m}(x) $$
| #根据8.6式:将结果加上当前层乘以α,得到目前的最终输出预测 finallpredict += alpha * Gx |
这就是加法模型:
$$ f(x)=\sum_{m=1}^{M} \beta_{m} b\left(x ; \gamma_{m}\right) $$
其中, \( b\left(x ; \gamma_{m}\right) \)为基函数, \( \gamma_{m} \) 为基函数的参数, \( \beta_{m} \)为基函数的系数
最终分类器
$$ G(x)=\mathop{sign}(f(x)) \\ =\mathop{sign}\left(\sum_{m=1}^{M} \alpha_{m} G_{m}(x)\right) $$
| np.sign(finallpredict[i]) |
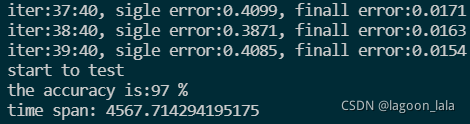
40层效果:
| iter:39:40, sigle error:0.4085, finall error:0.0154 start to test the accuracy is:97 % time span: 4567.714294195175 |
Boosting主要算法
提升方法Boosting=加法模型(即基函数的线性组合)+前向分步算法
提升树(boosting tree)=提升方法Boosting+基函数决策树
Gradient Boosting=提升方法Boosting+损失函数的负梯度优化
L2Boosting= Gradient Boosting+损失函数设为平方损失
AdaBoost= Gradient Boosting+指数损失
GBDT(Gradient Boosting Decision Tree)= Gradient Boosting+弱学习器决策树
XGBoost= GBDT的优化(损失函数加正则项防止过拟合/对预测评分等)
提升树(boosting tree)模型
(决策树的加法模型)
$$ f_{M}(x)=\sum_{m=1}^{M} T\left(x ; \Theta_{m}\right) $$
其中,\( T\left(x ; \Theta_{m}\right) \)表示决策树;\( \Theta_{m} \)为决策树的参数;M为树的个数
回归提升树
算法8.3
输入:训练数据集\( T=\left\{\left(x_{1}, y_{1}\right),\left(x_{2}, y_{2}\right), \cdots,\left(x_{N}, y_{N}\right)\right\}, x_{i} \in \mathcal{X} \subseteq \mathbf{R}^{n}, y_{i} \in \mathcal{Y} \subseteq \mathbf{R} \)
输出:提升树 \( f_{M}(x) \)
(1)初始化 \( f_{0}(x)=0 \)
(2)对m=1,2,…,M
(a)计算残差$$ r_{m i}=y_{i}-f_{m-1}\left(x_{i}\right), \quad i=1,2, \cdots, N $$
(b)拟合残差\( r_{m i} \)学习一个回归树,得到\( T\left(x ; \Theta_{m}\right) \)
(c)更新\( f_{m}(x)=f_{m-1}(x)+T\left(x ; \Theta_{m}\right) \)
(3)得到回归问题提升树
$$ f_{M}(x)=\sum_{m=1}^{M} T\left(x ; \Theta_{m}\right) $$
举例
给定数据

不同模型所得的总误差:

可看出最佳模型, 根据这个模型计算残差

再把这个残差当作训练数据训练下一轮模型
梯度提升
Gradient Boosting(梯度提升机GBM)一种boosting的对损失函数优化的算法
Gradient Boosting 的算法流程具有一般性,根据其中的损失函数和弱学习器的不同可以演变出多种不同的算法。
如果损失函数换成平方损失,则算法变成 L2Boosting;
指数损失,则算法演变成 AdaBoost;
弱学习器如果使用决策树,则算法成为 GBDT(Gradient Boosting Decision Tree)
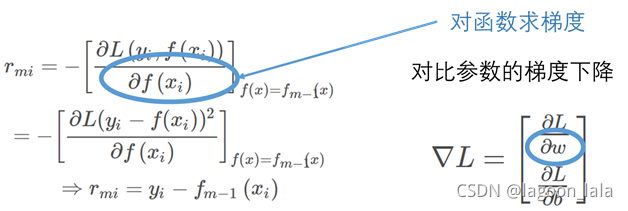
回归树(L2Boosting): 将残差看作平方损失函数的负梯度
$$ r_{m i}=-\left[\frac{\partial L\left(y_{i}, f\left(x_{i}\right)\right)}{\partial f\left(x_{i}\right)}\right]_{f(x)=f_{m-1}(x)}\\ =-\left[\frac{\partial L(y_i-f(x_i))^{2} }{\partial f\left(x_{i}\right)}\right]_{f(x)=f_{m-1}(x)}\\ \Rightarrow r_{m i}=y_{i}-f_{m-1}\left(x_{i}\right) $$

XGBoost
XGBoost = “Extreme Gradient Boosting”
XGBoost模型: 决策树集成decision tree ensembles
简单决策树(CART)
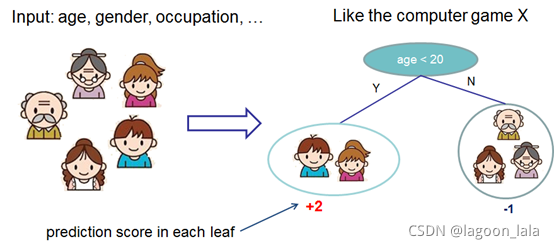
每个预测(叶结点)都有对该预测的评分, 预测时把每个score加起来就是最后预测结果
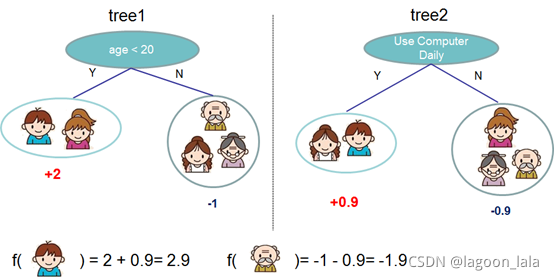
两棵树集成
预测得分公式:
$$ \hat{y}_i = \sum_{k=1}^K f_k(x_i), f_k \in \mathcal{F} $$
其中K为树的数量, f_k为第k棵树的预测函数关系
加上正则化项, 得到优化目标:
$$ \text{obj}(\theta) = \sum_i^n l(y_i, \hat{y}_i) + \sum_{k=1}^K \Omega(f_k) $$
使用均方误差(MSE)作为损失函数, 展开得到一个一次项(即为残差), 一个二次项+ 常数项:
$$ \text{obj}^{(t)} = \sum_{i=1}^n [l(y_i, \hat{y}_i^{(t-1)}) + g_i f_t(x_i) + \frac{1}{2} h_i f_t^2(x_i)] + \Omega(f_t) + \mathrm{constant} $$
组会Q&A整理
1. (8.2节)Adaboost算法的训练误差分析, 定理8.1 Adaboost的训练误差界证明

2. AdaBoost具有适应性的原因

3. (8.3.2小节)前向分步算法推导出Adaboost, 式(8.22)求参数α
















 1856
1856











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









