







向心性的计算
临近节点(Neighbourhood)
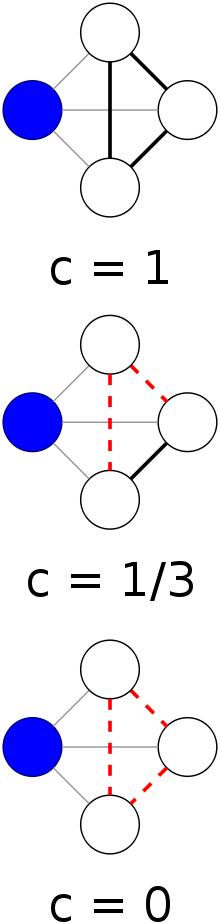
集中系数(Clustering Coefficient):节点的集中系数 == 其临近的节点中有边相连的节点数/其临近节点总数。图的集中系数是其每个节点的聚类系数的平均数。节点的集中系数表现了这个节点的临近节点的集中情况。图的集中系数表明图的集中水平。
度中心性(Degree Centrality):计算一个节点的边数,度中心性关注单个节点。
Hub节点:度很高的节点。在网络中通常扮演重要的角色。对于一个有向的网络来说,输入度通常用来代表受欢迎程度。
中介中心性(Betweenness Centrality):出现在许多其他节点间最短路径上的节点有较高的中介中心性分数。
节点A的度中心性高于节点H,因为节点H的直接连接更少。而节点H有更高的中介中心性,它在这个网络中扮演经纪人的角色,它处在网络内许多节点交往的路径上,因此,它具有控制其他人交往的能力。
特征向量中心性(Eigenvector Centrality):一个节点的特征向量中心性与其临近节点的中心性得分的总和成正比。与重要的节点连接的节点更重要。有少量有影响的联系人的节点其中心性可能超过拥有大量平庸的联系人的节点。这点与PR值类似。
特征向量中心性的计算:
1、计算图的成对临近矩阵的特征分解
2、选择有最大特征值的特征向量
3、第i个节点的中心性等于特征向量中的第i元素
随机网络(Random Networks)以及小世界网络(Small World Networks)
Erdős–Rényi随机图模型(Random Graph Model):一个有n个非连通节点的图,以概率p在每对节点间创建边。
小世界网络:
1、米尔格拉姆(著名的社会心理学家,曾主持服从实验)的小世界实验(Small World Experiment):
向内布拉斯加州随机选出的人发送一个包裹,让他们将这个包裹送给波士顿州的一名股票经纪人。要求他们将这个包裹转寄给可能认识这个股票经纪人的人。
尽管大部分节点不是直接连接,但是,每个节点可以通过一个相对较少的几次传递与其他节点相连。
2、凯文·贝肯的六度(Six Degrees of Kevin Bacon):基于小世界网络的一个室内游戏
从互联网电影数据库(IMDB)找出演员间合作的图。
一个演员的贝肯数是指他与贝肯相连最短路径的度数。
3、小世界网络的典型属性:
高集中系数
短平均路径
很多hub节点
构建一个直径较大的连通图,然后随机在其上添加几条边,图的直径将快速变小。
小世界网络有许多局部的联接和少量的“捷径”。
4、生成小世界网络:
创建n个节点的环,每一个节点与其最近的k个邻近节点相连
以概率p将每个节点与某个目标节点相连。
小团体(Clique):是指互相认识的一个社交群组(即每一对节点间都有边。)
极大团(Maximal Clique):当一个团不是图中其他团的子集时称为极大团。
最大团(Maximum Clique):当一个团的规模大于等于图中的其他团时称为最大团。
团体发现(Community Detection)
人们经常对在一个节点网络中识别团体很感兴趣
**团体(Community)/类别(Cluster)/模块(Module)**存在许多种定义:
一组有共同性质或在图中扮演类似角色的节点[Fortunato, 2010]
一个节点子集其中节点间联系密集,而到其他团体的边则密度较小[Girvan & Newman, 2002]
图的分割(Graph Partitioning)
目的:将图的节点分成用户指定数量的独立群组,用于优化与切分边相关的标准。
最小切分(Min-cut):就是找到一种分割使边的个数或边的权重最小。
近期的做法:使用更复杂的标准(即标准化分割)以及应用多层次的策略来扩展到大图。
**存在的问题:**需要预先制定分割的数量,切分原则通常基于聚类层次的强假设。
层次聚类(Hierarchical Clustering)
根据相似度计算构建一个聚类树来识别高相似度的节点组。
有两类基本算法:
**聚合:**从每个节点做为一个单独的群体开始,应用自下而上的策略,合并每个层次上最相似的群体。
**拆分:**从包含所有节点的单个群体开始,应用自上而下的策略,将每个层次上选定的群体分为两个子群体。(Hierarchical Clustering)
应用在团体发现时的问题:
如何从多种不同的聚类方式中进行选择?
在图是否真的存在层次结构?
通常对大图的扩展性很差
模块度最优化(Modularity Optimisation)
Newman & Girvan [2004]提出了分割质量的测量
随机图不应该有群体结构
通过比较实际的节点密度与随机图中的节点期望密度里验证群体的存在
Q = (群体中存在的节点数) − (群体中期望存在的节点数)
应用聚合技术迭代合并节点组组成更大的群体,使模块度在合并后提升。
近期出现的模块度最大化的高效贪婪方法可以将图的规模扩展到10的9次方个节点。
Louvain Method [Blondel et al, 2008]
应用在团体发现时的问题:
图的总节点数控制哪个团体被识别[Fortunato, 2010]
仅将节点分配给一个团体是否合理?
重叠VS不重叠
在现实的社交网络中,一个节点可能属于多个团体。(Overlapping Networks)
在许多的现实网络中,真正的“非重叠”团体很少大规模出现[Leskovec et al, 2008]。
团体重叠的普遍存在,使得无法分割网络而不拆分团体[Reid et al, 2011]。
(Overlapping In Large Graph)
重叠的团体发现
**CFinder:**基于小团体渗透技术(clique percolation method [Palla et al, 2005])的一种算法。
K-Clique识别:是完全连接的K个节点的子图。
如果一对K-Clique共享K-1Clique,那么,这两个K-Clique是临近的。
从最大的K-Cliques的组合就可以构成重叠的团体。
K-Cliques的组合是指可以通过临近的K-Clique互相达到的一组K-Clique。
贪婪小团体扩展(Greedy Clique Expansion,GCE):识别不同的小团体作为种子,通过优化本地适应性函数贪婪扩展这些种子[Lee et al, 2010]。
**MOSES:**识别高度重叠的团体的可扩展方法[McDaid et al, 2010]。
随机选择一条边,在这个边周围贪婪地扩展一个团体,以便优化目标函数。
删除“低质量”的团体
通过重新分配个别节点对团体进行微调
动态团体发现(Dynamic Community Finding)
在许多社交网络分析任务中,需要分析随着时间变化,团体是如何创建和发展的。
通常以“线下的”方式检查大量网络的快照来进行这项研究。
Snapshot of Network Snapshot of Network
可以用生命周期中的关键事件来描述动态团体的特征[Palla et al, 2007; Berger-Wolf et al, 2007]。Dynamic Community
为图的每个快照应用团体发现算法。
将新生成”后续团体”与过去发现的团体进行匹配。














 919
919











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









