










梯度下降(GD)是最小化风险函数、损失函数的一种常用方法,下面的h(x)是要拟合的函数,J(theta)损失函数,theta是参数,要迭代求解的值,theta求解出来了那最终要拟合的函数h(theta)就出来了。其中m是训练集的记录条数,j是参数的个数。
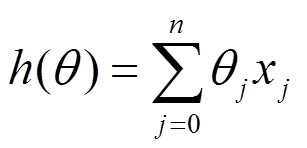
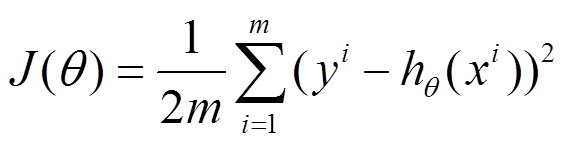
梯度下降法函数function [k ender]=steepest(f,x,e),需要三个参数f、x和e,其中f为目标函数,x为初始点,e为终止误差。输出也为两个参数,k表示迭代的次数,ender表示找到的最低点。
function [k ender]=steepest(f,x,e)
%梯度下降法,f为目标函数(两变量x1和x2),x为初始点,如[3;4]
syms x1 x2 m; %m为学习率
d=-[diff(f,x1);diff(f,x2)]; %分别求x1和x2的偏导数,即下降的方向
flag=1; %循环标志
k=0; %迭代次数
while(flag)
d_temp=subs(d,x1,x(1)); %将起始点代入,求得当次下降x1梯度值
d_temp=subs(d_temp,x2,x(2)); %将起始点代入,求得当次下降x2梯度值
nor=norm(d_temp); %范数
if(nor>=e)
x_temp=x+m*d_temp; %改变初始点x的值
f_temp=subs(f,x1,x_temp(1)); %将改变后的x1和x2代入目标函数
f_temp=subs(f_temp,x2,x_temp(2));
h=diff(f_temp,m); %对m求导,找出最佳学习率
m_temp=solve(h); %求方程,得到当次m
x=x+m_temp*d_temp; %更新起始点x
k=k+1;
else
flag=0;
end
end
ender=double(x); %终点
end批量梯度下降是一种对参数的update进行累积,然后批量更新的一种方式。用于在已知整个训练集时的一种训练方式,但对于大规模数据并不合适。
随机梯度下降是一种对参数随着样本训练,一个一个的及时update的方式。常用于大规模训练集,当往往容易收敛到局部最优解。
公式区别:
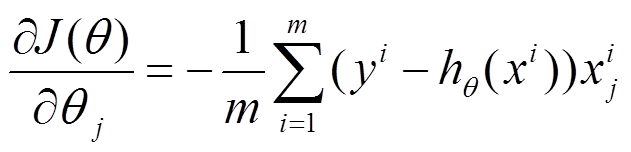
BGD:
按每个参数theta的梯度负方向,来更新每个theta
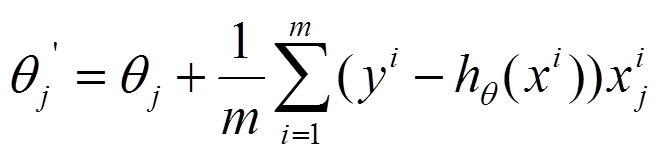
SGD:
每个样本的损失函数,对theta求偏导得到对应梯度,来更新theta
这样批量梯度下降---最小化所有训练样本的损失函数,使得最终求解的是全局的最优解,但是不适合数据比较大的应用,随机梯度下降---最小化每条样本的损失函数,不是每次迭代得到的损失函数都向着全局最优方向, 但是大的整体的方向是向全局最优(最优解附近)。
关于随机梯度下降法步长的选择,最好按3倍来调整,也就是0.00001、0.00003、0.0001、0.0003、0.001、0.003、0.01、0.03、0.1、0.3……然后确定范围之后再微调。如果α取值过大,可能会导致迭代不收敛,从而发散。所以,一开始α的取值也要比较小心才行。 随着迭代次数的增加,一般需要慢慢减小α,因为这样能得到一个更好的结果。至于怎么减小α,可以每次迭代都更新α的值,如α *= 0.96, 也可以 α*=α, 也可以每迭代几次更新一次 α的值 。 一般来说λ不会取太小(经验值0.001和1之间),也可以每次迭代都更新λ的值。比如一开始取比较小的值,然后随着迭代次数的增加,慢慢增加λ。 总结下,学习速率α越大,收敛越快,正则化参数λ越大,收敛越慢。收敛速度太快,可能一下子就越过极值点,导致发散;太慢则可能需要迭代非常多次,导致时间成本非常高。所以,α和λ取到一个合适的值,还是非常重要的。
C++的实现对比:
批量梯度下降法:
#include "stdio.h"
int main(void)
{
float matrix[4][2]={{1,4},{2,5},{5,1},{4,2}};
float result[4]={19,26,19,20};
float theta[2]={2,5}; //initialized theta {2,5}, we use the algorithm to get {3,4} to fit the model
float learning_rate = 0.01;
float loss = 1000.0; //set a loss big enough
for(int i = 0;i<100&&loss>0.0001;++i)
{
float error_sum = 0.0;
for(int j = 0;j<4;++j)
{
float h = 0.0;
for(int k=0;k<2;++k)
{
h += matrix[j][k]*theta[k];
}
error_sum = result[j]-h;
for(int k=0;k<2;++k)
{
theta[k] += learning_rate*(error_sum)*matrix[j][k];
}
}
printf("*************************************\n");
printf("theta now: %f,%f\n",theta[0],theta[1]);
loss = 0.0;
for(int j = 0;j<4;++j)
{
float sum=0.0;
for(int k = 0;k<2;++k)
{
sum += matrix[j][k]*theta[k];
}
loss += (sum-result[j])*(sum-result[j]);
}
printf("loss now: %f\n",loss);
}
return 0;
}随机梯度下降法 :
int main(void)
{
float matrix[4][2]={{1,4},{2,5},{5,1},{4,2}};
float result[4]={19,26,19,20};
float theta[2]={2,5};
float loss = 10.0;
for(int i =0 ;i<100&&loss>0.001;++i)
{
float error_sum=0.0;
int j=i%4;
{
float h = 0.0;
for(int k=0;k<2;++k)
{
h += matrix[j][k]*theta[k];
}
error_sum = result[j]-h;
for(int k=0;k<2;++k)
{
theta[k] = theta[k]+0.01*(error_sum)*matrix[j][k];
}
}
printf("%f,%f\n",theta[0],theta[1]);
float loss = 0.0;
for(int j = 0;j<4;++j)
{
float sum=0.0;
for(int k = 0;k<2;++k)
{
sum += matrix[j][k]*theta[k];
}
loss += (sum-result[j])*(sum-result[j]);
}
printf("%f\n",loss);
}
return 0;
}matlab实现:
BGD:
clear ;
close all;
x = [1:50].';
y = [4554 3014 2171 1891 1593 1532 1416 1326 1297 1266 ...
1248 1052 951 936 918 797 743 665 662 652 ...
629 609 596 590 582 547 486 471 462 435 ...
424 403 400 386 386 384 384 383 370 365 ...
360 358 354 347 320 319 318 311 307 290 ].';
m = length(y); % store the number of training examples
x = [ ones(m,1) x]; % Add a column of ones to x
n = size(x,2); % number of features
theta_vec = [0 0]';
alpha = 0.002;
err = [0 0]';
for kk = 1:10000
h_theta = (x*theta_vec);
h_theta_v = h_theta*ones(1,n);
y_v = y*ones(1,n);
theta_vec = theta_vec - alpha*1/m*sum((h_theta_v - y_v).*x).';
err(:,kk) = 1/m*sum((h_theta_v - y_v).*x).';
endSGD:
cNN里面的SGD实现:
function [ optParams ] = SGD( funObj,theta,data,labels,options )
% Runs stochastic gradient descent with momentum to optimize the
% parameters for the given objective.
%
% Parameters:
% funObj - function handle which accepts as input theta,
% data, labels and returns cost and gradient w.r.t
% to theta.
% theta - unrolled parameter vector
% data - stores data in m x n x numExamples tensor
% labels - corresponding labels in numExamples x 1 vector
% options - struct to store specific options for optimization
%
% Returns:
% opttheta - optimized parameter vector
%
% Options (* required)
% epochs* - number of epochs through data
% alpha* - initial learning rate
% minibatch* - size of minibatch
% momentum - momentum constant, defualts to 0.9
%% Setup
assert(all(isfield(options,{'epochs','alpha','minibatch'})),...
'Some options not defined');
if ~isfield(options,'momentum')
options.momentum = 0.9;
end;
epochs = options.epochs;
alpha = options.alpha;
minibatch = options.minibatch;
m = length(labels); % training set size
% Setup for momentum
mom = 0.5;
momIncrease = 20;
velocity = zeros(size(theta));
%%======================================================================
%% SGD loop
patience = options.patience;
patienceIncreasement = options.patienceIncreasement;
improvement = options.improvement;
validationHandler = options.validationHandler;
bestParams = [];
bestValidationLoss = inf;
validationFrequency = min(ceil(m/minibatch), patience/2);
doneLooping = false;
it = 0;
e = 0;
while (e < epochs) && (~doneLooping)
e = e + 1;
% randomly permute indices of data for quick minibatch sampling
rp = randperm(m);
for s=1:minibatch:(m-minibatch+1)
it = it + 1;
% increase momentum after momIncrease iterations
if it == momIncrease
mom = options.momentum;
end;
% get next randomly selected minibatch
mb_data = data(:,rp(s:s+minibatch-1));
mb_labels = labels(rp(s:s+minibatch-1));
% evaluate the objective function on the next minibatch
[cost grad] = funObj(theta,mb_data,mb_labels);
% early stop
if mod(it, validationFrequency) == 0
validationLoss = validationHandler(theta);
if validationLoss < bestValidationLoss
fprintf('validate=====================================current cost:%f, last cost:%f\n', validationLoss, bestValidationLoss);
if validationLoss < bestValidationLoss*improvement
patience = max(patience, it* patienceIncreasement);
bestParams.param = theta;
bestParams.loss = validationLoss;
end
bestValidationLoss = validationLoss;
end
end
if patience < it
doneLooping = true;
fprintf('stop due to patience[%d] greater than iterate[%d]\n', patience, it);
break;
end
% Instructions: Add in the weighted velocity vector to the
% gradient evaluated above scaled by the learning rate.
% Then update the current weights theta according to the
% sgd update rule
%%% YOUR CODE HERE %%%
velocity = mom*velocity + alpha*grad;
theta = theta - velocity;
% fprintf('Epoch %d: Cost on iteration %d is %f\n',e,it,cost);
end;
% aneal learning rate by factor of two after each epoch
alpha = alpha/2.0;
end;
optParams = theta;
end
简单应用:
A=round(50*rand(50,2));
theta=[10 6]';
result=(1:50)';
learning_rate=0.01;
loss=1000;
i=0;
switch(2)
case 1,
while(i<=100&&loss>0.0001)
i=i+1;
error=result-A*theta;
theta=theta+learning_rate.*A'*error;
fprintf('theta is %f\n',theta);
loss=(A*theta-result)'*(A*theta-result);
fprintf('loss is %f\n',loss);
break;
end
case 2,
while(i<=100&&loss>0.0001)
error=zeros(50,1);
j=mod(i,50)+1;
error(j,:)=result(j,:)-A(j,:)*theta;
theta=theta+learning_rate.*A'*error;
fprintf('theta is %f\n',theta);
loss=(A*theta-result)'*(A*theta-result);
fprintf('loss is %f\n',loss);
i=i+1;
break;
end
end
python实现:
// 随机梯度下降,更新参数
public void updatePQ_stochastic(double alpha, double beta) {
for (int i = 0; i < M; i++) {
ArrayList<Feature> Ri = this.dataset.getDataAt(i).getAllFeature();
for (Feature Rij : Ri) {
// eij=Rij.weight-PQ for updating P and Q
double PQ = 0;
for (int k = 0; k < K; k++) {
PQ += P[i][k] * Q[k][Rij.dim];
}
double eij = Rij.weight - PQ;
// update Pik and Qkj
for (int k = 0; k < K; k++) {
double oldPik = P[i][k];
P[i][k] += alpha
* (2 * eij * Q[k][Rij.dim] - beta * P[i][k]);
Q[k][Rij.dim] += alpha
* (2 * eij * oldPik - beta * Q[k][Rij.dim]);
}
}
}
}
// 批量梯度下降,更新参数
public void updatePQ_batch(double alpha, double beta) {
for (int i = 0; i < M; i++) {
ArrayList<Feature> Ri = this.dataset.getDataAt(i).getAllFeature();
for (Feature Rij : Ri) {
// Rij.error=Rij.weight-PQ for updating P and Q
double PQ = 0;
for (int k = 0; k < K; k++) {
PQ += P[i][k] * Q[k][Rij.dim];
}
Rij.error = Rij.weight - PQ;
}
}
for (int i = 0; i < M; i++) {
ArrayList<Feature> Ri = this.dataset.getDataAt(i).getAllFeature();
for (Feature Rij : Ri) {
for (int k = 0; k < K; k++) {
// 对参数更新的累积项
double eq_sum = 0;
double ep_sum = 0;
for (int ki = 0; ki < M; ki++) {// 固定k和j之后,对所有i项加和
ArrayList<Feature> tmp = this.dataset.getDataAt(i).getAllFeature();
for (Feature Rj : tmp) {
if (Rj.dim == Rij.dim)
ep_sum += P[ki][k] * Rj.error;
}
}
for (Feature Rj : Ri) {// 固定k和i之后,对多有j项加和
eq_sum += Rj.error * Q[k][Rj.dim];
}
// 对参数更新
P[i][k] += alpha * (2 * eq_sum - beta * P[i][k]);
Q[k][Rij.dim] += alpha * (2 * ep_sum - beta * Q[k][Rij.dim]);
}
}
}
}














 6937
6937











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









