







A Discriminatively Learned CNN Embedding for Person Re-identification
link: https://arxiv.org/abs/1611.05666
Author: Zhedong Zheng, Liang Zheng and Yi Yang
Code: https://github.com/layumi/2016_person_re-ID
Author email: zdzheng12@gmail.com
Homepage: http://zdzheng.xyz
欢迎关注知乎专栏 行人重识别
这篇 行人重识别 paper主要ague的是
1. verification label 为0,1二值。如果输入的两张图片为同一人,则为1,否则为0。
显然,这个label较弱,由于它没有利用上整的数据集的标注信息(每次只考虑了两个或三个样本之间label的关系,如contrastive loss 和 triplet loss)。
2. identity label为身份label。比如在Market1501数据集上,有751个identity,那么就是751个label。这个label较强,为数据集原始的标注信息。
如下图,可以直观的看到 对于身份认证模型(verification model)来说,虽然他显式的考虑了样本之间的相似度,但显然没有充分利用所有的label信息。
而对于身份分类模型(classification model),在一个batch中一起bp。其实潜在就融合了类内数据在高维空间相似和类间差异的要求。
于是提出的模型融合了这两种loss。
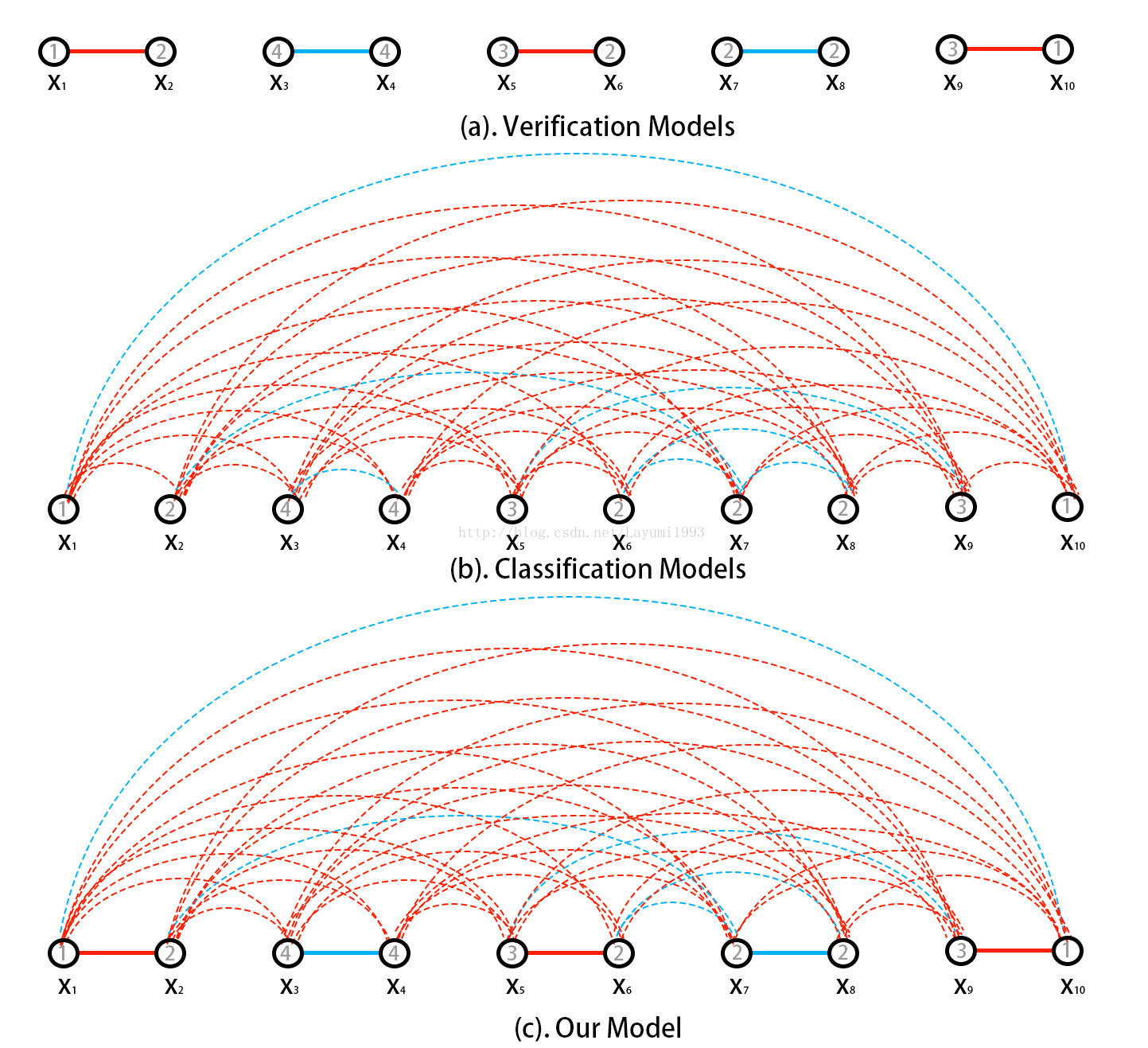
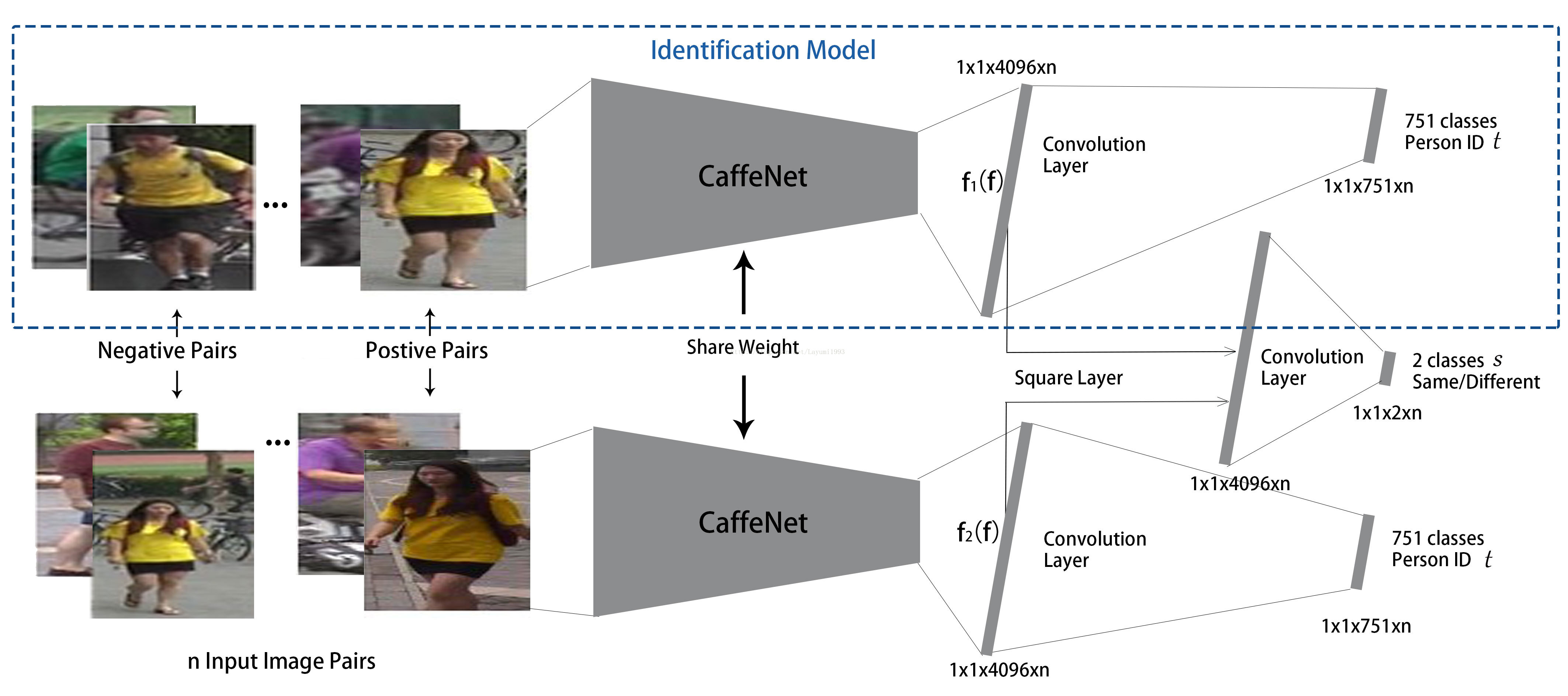
3. 网络模型如何
作者其实简单融合了原始的两种loss,并做了修改。在bp时,按权重将两种loss的梯度一同tune network。
篮框中的网络即为原来finetune的classification model,最后predict identity label。
其中Square Layer 即为 简单的欧式距离但element wise。所以得出的也是向量。再用这个向量去predict verification label。
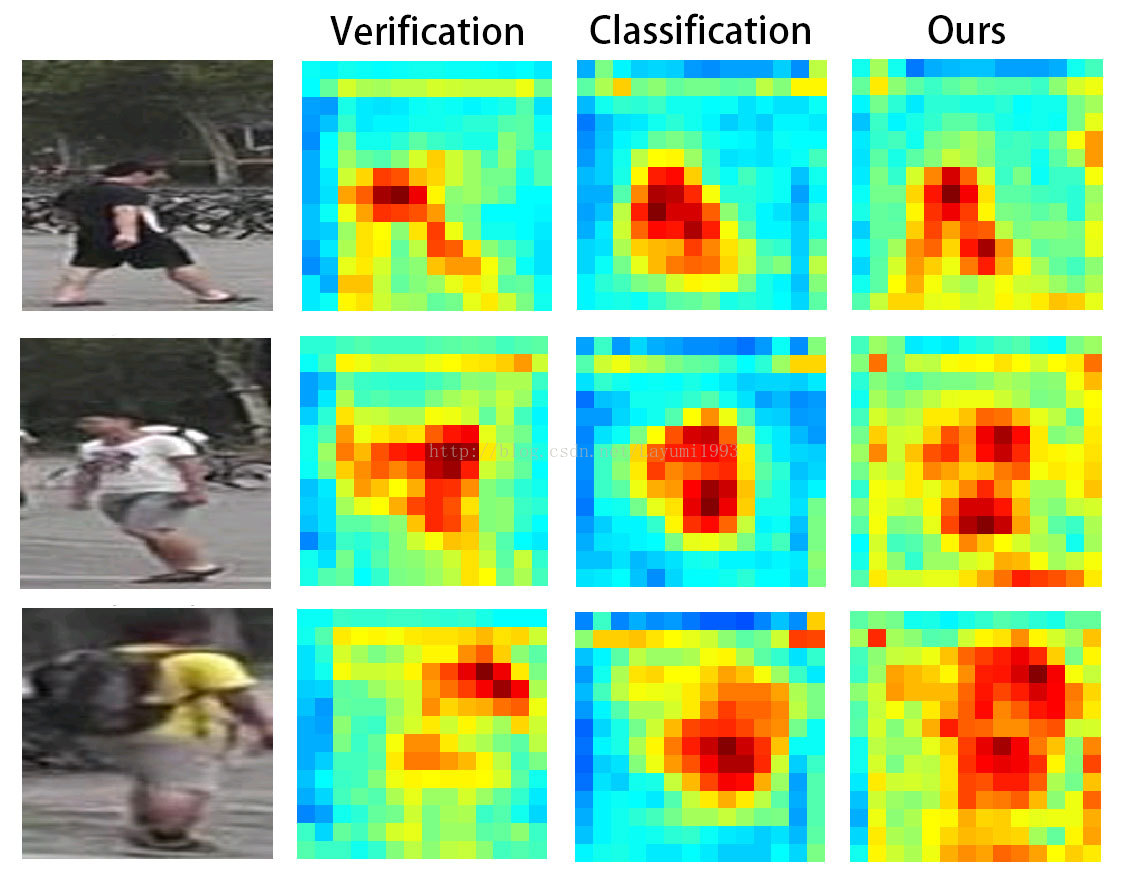
4.classification和verification谁贡献更大?为什么融合以后好了?
作者还比较了单独使用两个模型的效果。来找到谁的效果更强。Paper中发现classification mode 略好一些。
至于融合以后,如下图,我们可以明显地看出两个网络各自学到了不同的attetion。当fusion之后,the proposed model显示出了一个attention的融合。
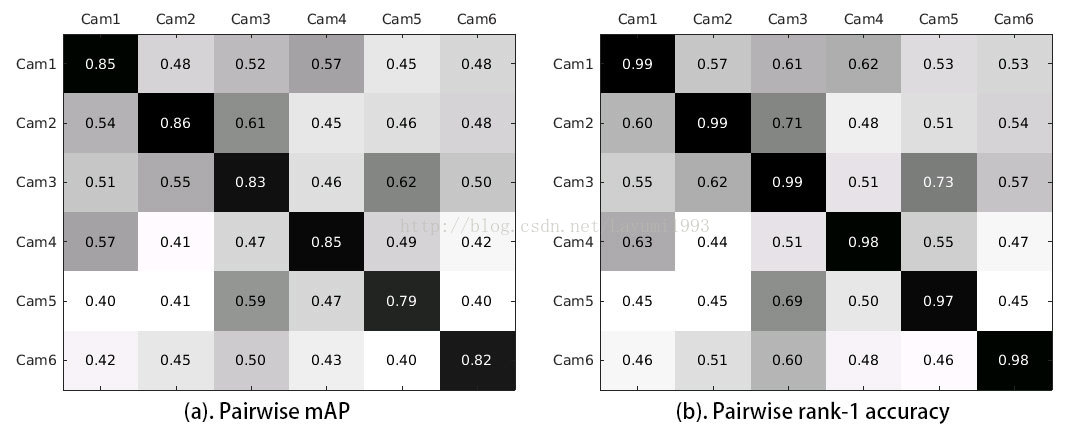
最后在market1501的无监督聚类效果图如下,可以看出学到了一些discriminative 特征

P.S. 虽然 Camera6为低清摄像头,但提出的embedding没有受到很大的影响。(相比于原始数据集中的Hist结果确实好很多了。。。)















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











