







错误率:
m个样本中有a个分类错误,则错误率E=a/m;
精度
1-a/m;
误差
实际预测输出与样本真实输出之间的差异称为误差,学习器在训练集上的误差称为‘训练误差’或者‘经验误差’,在新样本上的误差称为‘泛化误差’(generalization error)。
显然我们希望得到泛化误差小的机器。
过拟合与欠拟合
过拟合:学习器把训练样本学的太好,很可能把训练样本本身的特点当做了所有潜在样本都具有的一般性质,这样会导致泛化性能下降,这种现象称为‘过拟合’。
欠拟合:这是指对一般性质都没有学好。
造成过拟合原因:学习能力强,连样本所包含的不一般的特性都学习到了,而欠拟合是由于学习能力低造成的。欠拟合比较容易克服,如在决策树学习中扩展分支、在神经网络学习中增加训练轮数。
评估方法
1.留出法
分层采样,部分比例做训练集/剩余测试集
2.交叉验证法
将数据集划分为k个大小相似的互斥子集。每个子集尽可能保持数据分布的一致性。每次用k-1个子集的并集作为训练集,余下那个子集作为测试集。这样获得k组训练/测试集。最终返回均值。
交叉验证法评估结构的稳定性和保真性在很大程度上取决于k的均值,通常把交叉验证法称为k折交叉验证。
3.自助法
在留出法和交叉验证法中,由于保留一部分样本用于测试,因此实际评估的模型比所要使用的训练集D小,会引入一些因训练样本规模不同而导致的估计偏差。自助法是比较好的解决方案。
给定m个样本数据集,
查准率(precision)与查全率(recall)

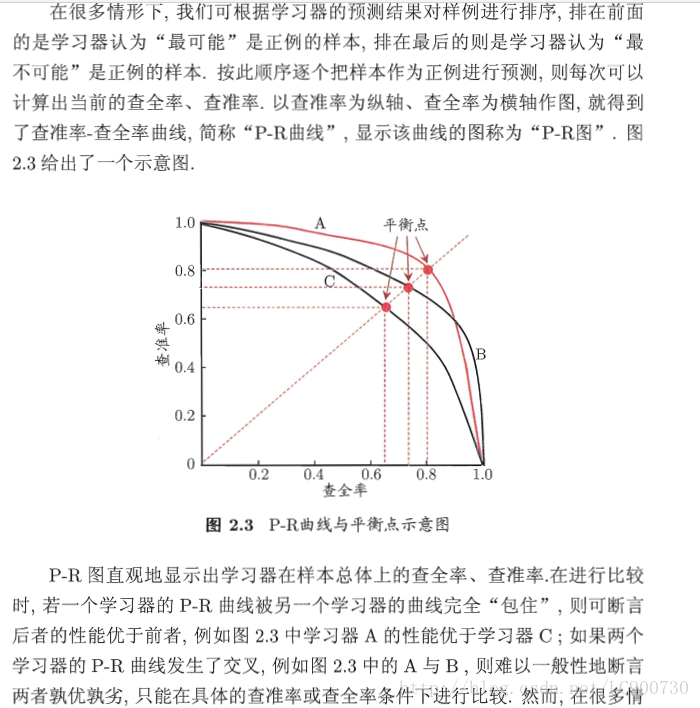
在某些情况下,对查准率和查全率的重试程度不同。在商品推荐系统中,为了尽可能少打扰用户,更希望推荐内容是用户感兴趣的,此时查准率更重要。而在逃犯信息检索系统中,更希望尽可能减少漏掉逃犯,此时查准确更重要。
F1定义
基于查准率与查全率的调和平均(harmonic mean)定义的
1F1=12∗(1P+1R)
Fβ定义
加权调和平均
1Fβ=11+β2∗(1P+β2R)
其中β>0度量了查全率对查准率的相对重要性。β=1退化为标准的F1;β>1时查全率有更大影响,β<1时查准率有更大影响。
与算数平均
P+R2
和几何平均
P∗R‾‾‾‾‾√
相比,调和平均更重视较小值。














 3067
3067











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









