










在学习机器学习相关理论时,我们常常会会在公式中遇到指数函数和对数函数,但是很时候我们并不理解这些函数的的真正作用,这里结合几个机器学习中的公式来具体分析一下指数函数和对数函数的作用
指数函数
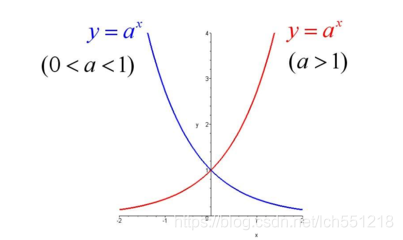
由上图可知:
- 指数函数的自变量范围是(-∞,+∞),因变量范围是(0,+∞)
- 当指数函数自变量范围在(-∞,0)时,因变量输出范围为(0,1)
因此,在神经网络中我们可以用指数函数的这两个性质对数据进行(-∞,+∞)到(0,+∞)或者(-∞,0)到(0,1)的映射
softmax函数就是一个使用指数函数将神经网络输出值转化为概率值的激活函数,softmax函数的公式如下:
S
i
=
e
V
i
∑
j
e
V
j
S_i = \frac{e^{V_i}}{\sum_j{e^{V_j}}}
Si=∑jeVjeVi
softmax首先使用指数函数讲每个输出节点的值映射到(0,+∞),然后计算每个节点对应值占总值的比例,然后输出。
指数函数的图像如下图所示:
softmax函数就是一个使用指数函数(ex,因为e>1,所以输出和输入是正相关)将神经网络输出值转化为概率值的激活函数,
你可能说 relu 这种分段函数也能实现这种映射啊,但是通过relu的公式我们可以发现,当自变量范围小于零时,因变量统一为0,这无疑会损失神经网络输出的大量负值信息;relu函数图像和公式如下:
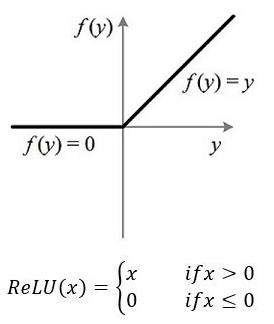
对数函数
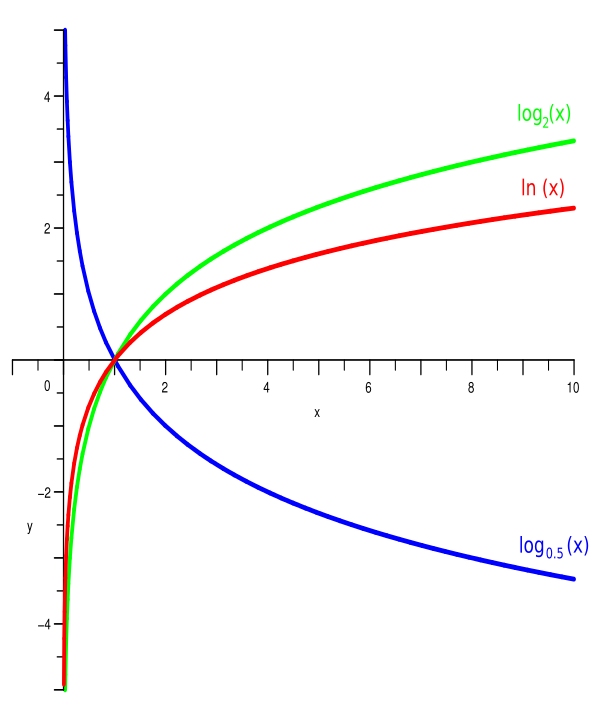
指数函数也可以实现区间映射,但对数函数和指数函数互为反函数,因此对数函数和指数函数映射的区间正好相反;
和由上图可知:
- 对数函数函数的自变量范围是(0,+∞),因变量范围是(-∞,+∞)
- 当对数函数自变量范围在(0,1)时,因变量输出范围为(-∞,0)
因此,在神经网络中我们可以用对数函数的这两个性质对数据进行(0,+∞)到(-∞,+∞)或者(0,1)到(-∞,0)的映射
跟熵(kl散度,交叉熵,熵)相关的公式中,大多包含对数函数;因为熵的输入是概率值,范围是[0,1],而熵值的范围是[0,+∞],因此需要使用上边总结的对数函数的第二条性质对概率值进行区间映射
熵的公式如下:
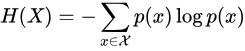
想要了解 kl散度,交叉熵,熵 三者的关系请移步这篇博客->#本质上理解# 熵、交叉熵、KL散度的关系















 2582
2582











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











