







正文共6182个字,7张图,预计阅读时间35分钟。
笔者作为一名根正苗红的理工男,内心却常常有很多文艺青年才会有的想法,例如写首诗、做首词,甚至包括春节写副对联,空有一番愿望却胸无点墨。随着对机器学习和深度学习的了解,逐渐萌生了使用机器帮助笔者完成文艺青年的转型。
本文借助递归神经网络RDD的变种之一LSTM算法,对收集到的6900多条对联进行学习,训练好模型后可以由机器写出对联。
故事从人工神经网络开始,人工神经网络诞生已久。如下图所示,神经网络的基本结构由输入层、输出层和一个或多个隐含层组成。
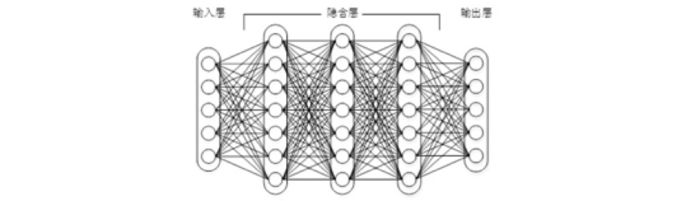
多层神经网络
全连接的神经网络下一层神经元的输入由上一层所有神经元的输出决定,因此带来了一个严重的问题即参数数量过大导致无法训练。因此,随时神经网络的发展,衍生了一系列的变化。比较流行的有应用于图像识别领域的卷积神经网络CNN、应用于自然语言处理的递归神经网络RNN。本文应用到的LSTM算法即为RNN的一种形态。RNN解决了这样的问题:即样本出现的时间顺序对于自然语言处理、语音识别、手写体识别等应用非常重要,神经元的输出可以在下一个时间戳直接作用到自身。因此RNN很适合处理时序对结果影响较深的领域。
关于RNN和LSTM原理的说明可以移步 http://www.jianshu.com/p/9dc9f41f0b29 ,本文不多加赘言。
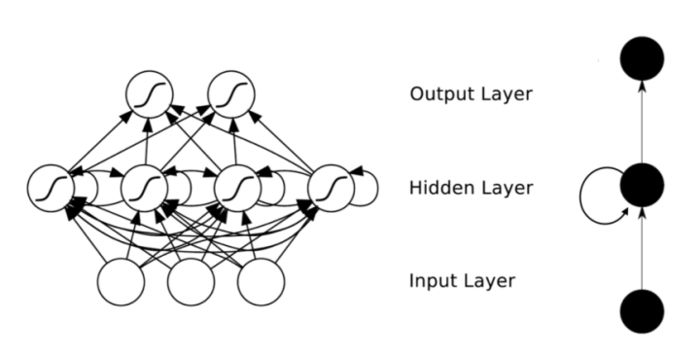
RNN
由于LSTM算法非常适用自然语言处理领域,因此网上出现了很多应用LSTM做文字领域的尝试,例如: LSTM写诗 中使用LSTM写诗,LSTM创作歌词中使用LSTM模仿歌手风格写歌词,以及使用LSTM算法给小孩起名(是多么不靠谱的粑粑麻麻)。
因此,笔者突发想法,如果给一个足够的春联训练样本,一样可以照猫画老虎,训练一个可以写对联的文艺“机器模型”。因此,问题就分解为:找样本、写算法、训练、应用模型。
借助于强大的度娘,费劲九牛之力,从网上搜集了各式春联共6900对,其中上联下联之间是用","分割区分上下联,对联之间是用"。"区分一联的结束。样式如下:

训练样本
这些样本将会在训练阶段进行类型转换并输入给LSTM模型中。如果您也想试下本文案例,请私信我这些样本(毕竟搜集训练样本是个苦差事(: )
本文使用TensorFlow进行建模,TensorFlow就无需多言,是这个领域目前最活跃的框架。写对联的算法主要工作包括:根据样本数据产生LSTM输入数据和结果值;定义LSTM的模型以及损失函数;将训练数据喂给TensorFlow用来训练模型。接下来会逐步列举本例中使用的方法。
训练数据转换
由于样本数据是一条条汉字组成的对联,这样的数据是无法交给模型训练的,因此需要对样本数据进行转换。基本思想是:将样本的所有对联加载录入,统计出所有出现的汉字,并将汉字进行编码,例如:一共有10000个汉字出现在样本中,那么对出现的汉字按 0 - 999 进行编码,每个汉字对应一个编码。
对原始样本进行编码转换,生成用数字编码表示的对联集。
每条对联作为一个输入序列,每批次训练batch_size条,生成输入数据xdata,输出y值为xdata+1。因为文本分析的特点是有时序性。
couplet_file ="couplet.txt"#对联couplets = []with open(couplet_file,'r') as f: for line in f: try: content = line.replace(' ','') if '_' in content or '(' in content or '(' in content or '《' in content or '[' in content: continue if len(content) < 5*3 or len(content) > 79*3: continue content = '[' + content + ']' # print chardet.detect(content) content = content.decode('utf-8') couplets.append(content) except Exception as e: pass# 按字数排序couplets = sorted(couplets,key=lambda line: len(line)) print('对联总数: %d'%(len(couplets)))# 统计每个字出现次数all_words = []for couplet in couplets: all_words += [word for word in couplet] counter = collections.Counter(all_words) count_pairs = sorted(counter.items(), key=lambda x: -x[1]) words, _ = zip(*count_pairs) words = words[:len(words)] + (' ',)# 每个字映射为一个数字IDword_num_map = dict(zip(words, range(len(words)))) to_num = lambda word: word_num_map.get(word, len(words)) couplets_vector = [ list(map(to_num, couplet)) for couplet in couplets]# 每次取64首对联进行训练, 此参数可以调整batch_size = 64n_chunk = len(couplets_vector) // batch_size x_batches = [] y_batches = []for i in range(n_chunk): start_index = i * batch_size#起始位置 end_index = start_index + batch_size#结束位置 batches = couplets_vector[start_index:end_index] length = max(map(len,batches))#每个batches中句子的最大长度 xdata = np.full((batch_size,length), word_num_map[' '], np.int32) for row in range(batch_size): xdata[row,:len(batches[row])] = batches[row] ydata = np.copy(xdata) ydata[:,:-1] = xdata[:,1:] x_batches.append(xdata) y_batches.append(ydata)
定义LSTM模型
使用TF api tf.nn.rnn_cell.BasicLSTMCell定义cell为一个128维的ht的cell。并使用MultiRNNCell 定义为两层的LSTM。
对训练样本输入进行embedding化。
使用tf.nn.dynamic_rnn计算输出值。(也可以通过循环step的方法,依次计算)
加入softmax层。
def neural_network(rnn_size=128, num_layers=2): cell = tf.nn.rnn_cell.BasicLSTMCell(rnn_size, state_is_tuple=True) cell = tf.nn.rnn_cell.MultiRNNCell([cell] * num_layers, state_is_tuple=True) initial_state = cell.zero_state(batch_size, tf.float32) with tf.variable_scope('rnnlm'): softmax_w = tf.get_variable("softmax_w", [rnn_size, len(words)+1]) softmax_b = tf.get_variable("softmax_b", [len(words)+1]) with tf.device("/cpu:0"): embedding = tf.get_variable("embedding", [len(words)+1, rnn_size]) inputs = tf.nn.embedding_lookup(embedding, input_data) outputs, last_state = tf.nn.dynamic_rnn(cell, inputs, initial_state=initial_state, scope='rnnlm') output = tf.reshape(outputs,[-1, rnn_size]) logits = tf.matmul(output, softmax_w) + softmax_b probs = tf.nn.softmax(logits) return logits, last_state, probs, cell, initial_state
训练阶段
使用TF sequence_loss_by_example计算所有examples(假设一句话有n个单词,一个单词及单词所对应的label就是一个example,所有example就是一句话中所有单词)的加权交叉熵损失。
tf.gradients 计算梯度,并使用clip_by_global_norm控制梯度爆炸的问题。梯度爆炸和梯度弥散的原因一样,都是因为链式法则求导的关系,导致梯度的指数级衰减。为了避免梯度爆炸,需要对梯度进行修剪。(来自网上的解释,不明觉厉(: )
定义步长,步长过大,会很可能越过最优值,步长过小则使优化的效率过低,长时间无法收敛。因此learning rate是一个需要适当调整的参数。一个小技巧是,随时训练的进行,即沿着梯度方向收敛的过程中,适当减小步长,不至于错过最优解。在代码中 0.01 * (0.97 ** epoch),learing rate基数值为0.01, 系数为0.97的epoch方,可以看出epoch越大,learing rate越小。
分批次将样本数据x_batches和y_batches喂给TF进行训练。
def train_neural_network(): logits, last_state, _, _, _ = neural_network() targets = tf.reshape(output_targets, [-1]) loss = tf.contrib.legacy_seq2seq.sequence_loss_by_example([logits], [targets], [tf.ones_like(targets, dtype=tf.float32)], len(words)) cost = tf.reduce_mean(loss) learning_rate = tf.Variable(0.0, trainable=False) tvars = tf.trainable_variables() grads, _ = tf.clip_by_global_norm(tf.gradients(cost, tvars), 5) optimizer = tf.train.AdamOptimizer(learning_rate) train_op = optimizer.apply_gradients(zip(grads, tvars)) with tf.Session() as sess: sess.run(tf.initialize_all_variables()) saver = tf.train.Saver(tf.all_variables()) for epoch in range(100): sess.run(tf.assign(learning_rate, 0.01 * (0.97 ** epoch))) n = 0 for batche in range(n_chunk): train_loss, _ , _ = sess.run([cost, last_state, train_op], feed_dict={input_data: x_batches[n], output_targets: y_batches[n]}) n += 1 print(epoch, batche, train_loss) if epoch % 7 == 0: saver.save(sess, './couplet.module', global_step=epoch)
训练结束 , 诗性大发
经过漫长的训练(取决于样本数和迭代次数), loss控制在1.5左右。

loss
可以看到,经过100次的迭代训练,每7次保存一次(saver.save(sess, './couplet.module', global_step=epoch)), 最后的模型保存在couplet.module-98里。

modle
在eval阶段,使用saver.restore(sess, 'couplet.module-98') 将训练好的模型加载, 因为机器算出来的依旧是上文提到的数字编码,因此需要再将数字转为汉字。
好啦,来看看机器创作的对联吧, 是不是有点意思呢?

couplet
原文链接:http://blog.csdn.net/v_JULY_v/article/details/71598551
查阅更为简洁方便的分类文章以及最新的课程、产品信息,请移步至全新呈现的“LeadAI学院官网”:
www.leadai.org
请关注人工智能LeadAI公众号,查看更多专业文章

大家都在看

TensorFlow从1到2 | 第三章 深度学习革命的开端:卷积神经网络















 473
473











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









