






六月 北京 | 高性能计算之GPU CUDA培训
6月22-24日 三天密集式学习 快速带你入门
阅读全文
>
三天密集式学习 快速带你入门
阅读全文
>
正文共2249个字,22张图,预计阅读时间15分钟。
个人博客:http://mcgrady.cn
github:https://github.com/TracyMcgrady6
前言:蛋疼的简书,不支持MathJax 编辑公式,所以请看我的个人博客:
对于二类分类问题,训练集T={(${ x }{ 1 }$,${ y }{ 1 }$),(${ x }{ 2 }$,${ y }{ 2 }$),...,(${ x }{ n }$,${ y }{ n }$)},其类别${ y }_{ n }\in ${-1,1},线性SVM通过学习得到分离超平面:
$$ w\bullet x+b=0 $$
以及相应的分类决策函数:
$$f\left( x \right) =sign(w\bullet x+b)$$
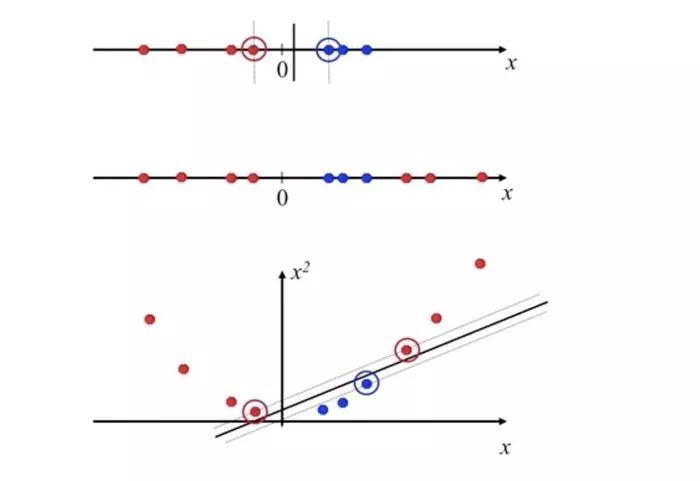
有如下图所示的分离超平面,哪一个超平面的分类效果更好呢?
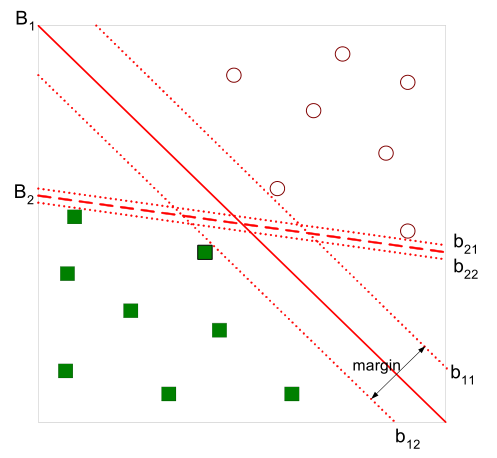
Margin
直观上,超平面B1的分类效果更好一些。将距离分离超平面最近的两个不同类别的样本点称为支持向量(support vector)的,构成了两条平行于分离超平面的长带,二者之间的距离称之为margin。显然,margin更大,则分类正确的确信度更高(与超平面的距离表示分类的确信度,距离越远则分类正确的确信度越高)。
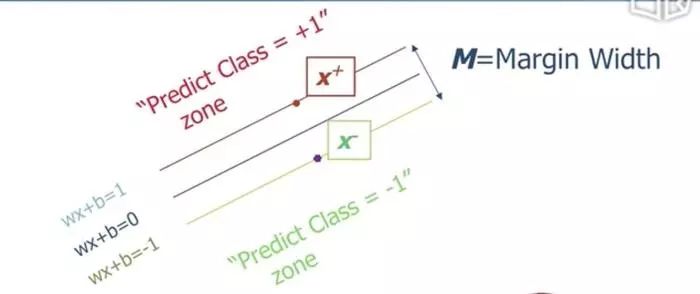
直线距离可知
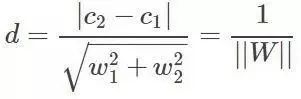
所以
$$Margin=\frac { 2 }{ \parallel w\parallel } $$
目标函数
约束条件
对于所有点,还要求分类正确,即:
$$w\bullet x+b\ge 1\quad \quad \quad if\quad { y }{ i }=+1$$$$ w\bullet x+b\ge -1\quad \quad \quad if\quad { y }{ i }=-1$$$${ y }_{ i }(w\bullet x+b)-1\ge 0$$
最大化Margin
$$\max { M } =\frac { 2 }{ \parallel w\parallel } \Rightarrow \min { \frac { 1 }{ 2 } { w }^{ T }w } $$
最优化问题
Minimize $\Phi (w)=\frac { 1 }{ 2 } { w }^{ T }w$
Subject to ${ y }_{ i }(w\bullet x+b)-1\ge 0$
引入拉格朗日乘子法了,优化的目标变为:
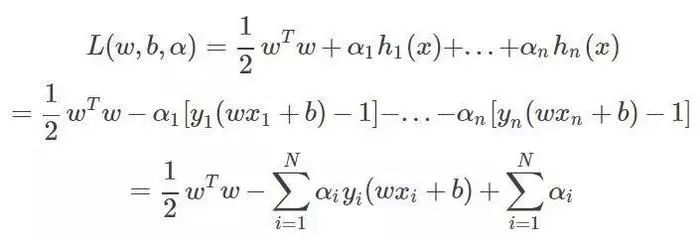
求导:
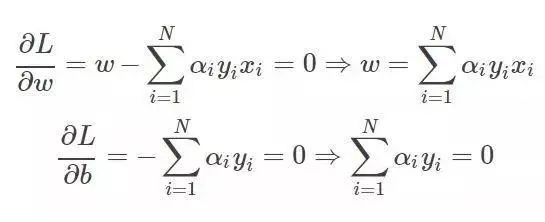
带入拉格朗日函数,对偶问题转为

等价于最优化问题:
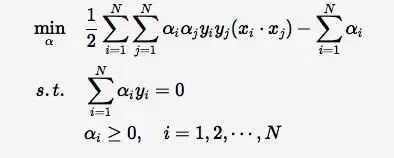
(1)求得${ \alpha }^{ * }={ ({ \alpha }{ 1 }^{ * },{ \alpha }{ 2 }^{ * },...,{ \alpha }{ N }^{ * }) }^{ T }$
(2)计算
${ \omega }^{ * }=\sum { i=1 }^{ N }{ { \alpha }{ i }^{ * } } { y }{ i }{ x }{ I }$
并选择${ \alpha }{ * }$的一个正分量 ${ \alpha }_{ j }^{ * }$>0,计算

(3)求得分离超平面
${ \omega }^{ * }\bullet x+b=0$
分类决策函数:
$$f\left( x \right) =sign({ \omega }^{ * }\bullet x+b)$$
在线性可分SVM中,${ \omega }^{ * }$和${ b }^{ * }$只依赖于训练数据中对应于${ \alpha }{ i }^{ * }$>0的样本点$({ x }{ i },{ y }{ i })$,其他样本点对${ \omega }^{ * }$和${ b }^{ * }$没有影响。我们将训练数据中对应${ \alpha }{ i }^{ * }$>0的样本点称为支持向量。
Example

Soft Margin

求解

Non-linear SVMs
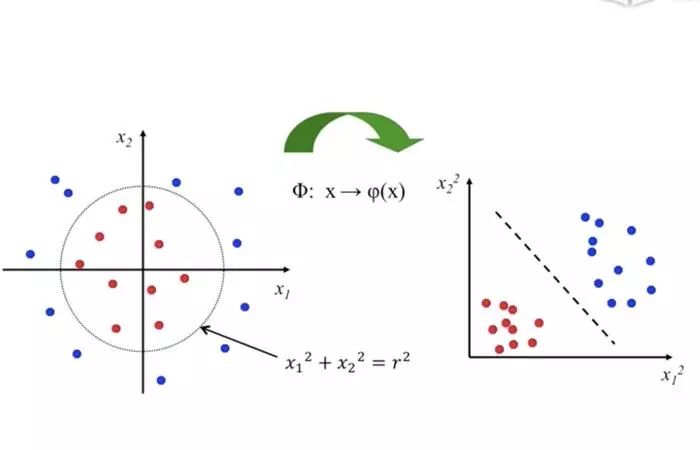


利用高维空间,数据更好的可分(优点),又避免了高维空间计算复杂(缺点)

1、Linear核:主要用于线性可分的情形。参数少,速度快,对于一般数据,分类效果已经很理想了。
2、RBF核:主要用于线性不可分的情形。参数多,分类结果非常依赖于参数。有很多人是通过训练数据的交叉验证来寻找合适的参数,不过这个过程比较耗时。个人体会是:使用libsvm,默认参数,RBF核比Linear核效果稍差。通过进行大量参数的尝试,一般能找到比linear核更好的效果。
3、多项式核函函数
4、字符串核函数
序列最小最优化算法SMO
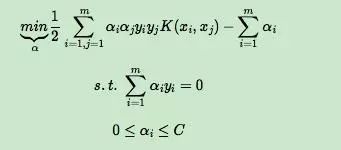
上面这个优化式子比较复杂,里面有m个变量组成的向量α需要在目标函数极小化的时候求出。直接优化时很难的。SMO算法则采用了一种启发式的方法。它每次只优化两个变量,将其他的变量都视为常数。由于:
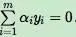
假如将
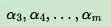
固定。那么a1,a2的之间的关系也确定了。这样SMO算法将一个复杂的优化算法转化为一个比较简单的两变量优化问题。
为了后面表示方便,我们定义
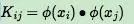
由于
成了常量,所有的常量我们都从目标函数去除,这样我们上一节的目标优化函数变成下式:
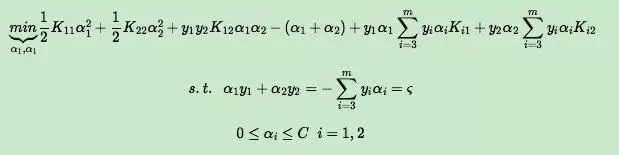
原文链接:https://www.jianshu.com/p/e7e308584b20
查阅更为简洁方便的分类文章以及最新的课程、产品信息,请移步至全新呈现的“LeadAI学院官网”:
www.leadai.org
请关注人工智能LeadAI公众号,查看更多专业文章

大家都在看















 7704
7704











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









