






序
今天来翻译一篇文章,关于c++中算法的使用,及KISS原则。https://arne-mertz.de/2019/05/algorithms-and-the-kiss-principle 大家如果有兴趣的话,求个赞,同时也是本人创作的动力,十分感谢。以下开始为正文:
您可能已经听说过优先选择标准算法而不是原始for循环的规则。主要原因是这些算法在名称中说明了正在发生的事情并封装了循环逻辑。但它们一般来说并不总是最佳选择。
使用标准算法
特别是实现一些复杂的算法时,可能会变的相当的混乱。因此,除了在代码中包含算法的名称外,将算法部分与其余逻辑分开是一个好主意。这样可以使得代码更加简单,符合KISS原则。
KISS原则是Keep It Simple, Stupid,指在设计当中应当注重简约的原则,笨蛋原则,傻瓜都可以看懂的。《帮你省一步百度:)》
我强烈建议你学习这些算法,或者说如果你了解它们,进一步更好的使用。一个很好的资源是这里:
https://www.youtube.com/watch?v=2olsGf6JIkU
例子
我们来展示一些例子,是一些内部封装了循环的标准算法。过去几周在我的代码中我遇到了类似的例子,这里有两个。
Copy
想象我们有一个容器,自己写的或者是来自第三方库。兼容标准的迭代器,用来存放Employee数据的,为了重用这块数据,我们需要把它转移到std::vector中。
OtherContainer<Employee> source;
//...
std::vector<Employee> employees;
employees.reserve(source.size());
for (auto const& employee : source) {
employees.push_back(employee);
}
我们使用算法来替代上边,简化版的copy:
std::vector<Employee> employees;
employees.reserve(source.size());
std::copy(std::begin(source), std::end(source), std::back_inserter(emplyoees));
这里std::back_inserter帮助我们创建std::back_insert_iterator,内部也会进一步调用push_back函数。
看起来很简单,还有一个更简单的版本:
std::vector<Employee> employees(std::begin(source), std::end(source));
这里是调用std::vector的迭代器范围构造函数,其他的容器也有。因此,有时候有比标准算法更好的替代原始循环的方法。
Transform
然后在我的代码库里,我想要分析员工(employees)的薪水,因为Employee类有一个uniqueName函数,所以我们这里把名字和薪水组成一个std::map:
std::map<std::string, unsigned> salariesByName;
for (auto const& employee : employees) {
salariesByName[employee.uniqueName()] = employee.salary();
}
我们也可以使用map的insert函数替代访问操作符:
std::map<std::string, unsigned> salariesByName;
for (auto const& employee : employees) {
salariesByName.insert(
std::make_pair(
employee.uniqueName(),
employee.salary()
)
);
}
从一个容器获取元素,并通过这些元素为另外一个容器创建不同的元素的算法是std::transform:
std::map<std::string, unsigned> salariesByName;
std::transform(
std::begin(employees),
std::end(employees),
std::inserter(salariesByName, std::end(salariesByName)),
[](auto const& employee) {
return std::make_pair(
employee.uniqueName(),
employee.salary());
}
);
std::inserter类似back_inserter,但是他需要一个迭代器作为插入的地方,lambda表达式执行Employee元素到map元素的转化。
现在这看起来并不像我们之前的第一个for循环那样清晰明了。
条件Tranform
列出所有员工的薪水是非常有趣的,但也许你的经理不想让你知道他的薪水是多少,因此,将经理的薪水排除在map之外。针对于原始的循环,我们简单修改下:
std::map<std::string, unsigned> salariesByName;
for (auto const& employee : employees) {
if (!employee.isManager()) {
salariesByName[employee.uniqueName()] = employee.salary();
}
}
循环变得有一点复杂,不过仍然是可读的。我们可能不相信,在这里使用算法是必要的,以使其更具可读性。但是如果我们这么做了,看看会怎么样。一般来说一个有条件的算法,是有一个_if的后缀。std::copy_if就会拷贝满足条件的元素。std::find_if及std::remove_if也是处理满足相应谓词的元素。那么这里我们需要的算法就是transform_if,但是标准库里没有这个算法。幸运的是,在看完std::transform和std::copy_if后我们实现这个算法也不难。那么下边则是我们自己实现的代码:
template <typename InIter, typename OutIter,
typename UnaryOp, typename Pred>
OutIter transform_if(InIter first, InIter last,
OutIter result, UnaryOp unaryOp, Pred pred) {
for(; first != last; ++first) {
if(pred(*first)) {
*result = unaryOp(*first);
++result;
}
}
return result;
}
//...
std::map<std::string, unsigned> salariesByName;
transform_if(
std::begin(employees),
std::end(employees),
std::inserter(salariesByName, std::end(salariesByName)),
[](auto const& employee) {
return std::make_pair(
employee.uniqueName(),
employee.salary()
);
},
[](auto const& employee) {
return !employee.isManager();
}
);
现在我们有两个lambda表达式,一个是转化的实际实现,另一个是条件谓词。后者通常是算法的最后一个参数。如果我们真的要完整的写transform_if,还不止于此。有四个版本的std::transform,我们不得不依次实现。
已经很明显了,任何时候我更愿意在循环里使用三行代码(加上括号五行)实现而不是使用这个庞然大物。
性能怎么样
这个问题总是会被拿出来说,我的答案在这里 https://arne-mertz.de/2015/03/simple-and-clean-code-vs-performance, 首先写可读的代码。其次检查该代码是否性能问题。第三,测量。
至于可读的代码,我已经在上边说明了我的偏好。这些简单的例子中,for循环看起来是更加可读的。其次我们目的是创建一个容器,这可能是发生在输入的地方,而不是一个热点的循环中。任何情况下,插入数据到map中都会分配内存。与我们编写的循环和库实现者编写的循环之间的区别相比,内存分配对性能的影响要大得多。
当然我使用QuickBench也做了一些初步的测量:
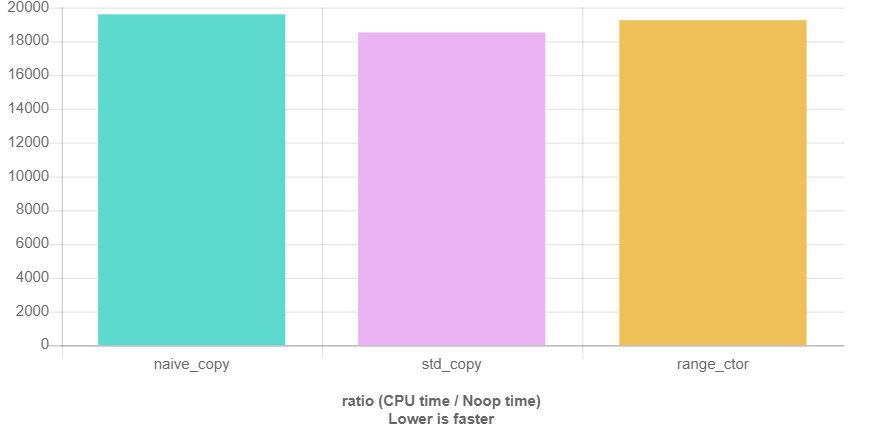
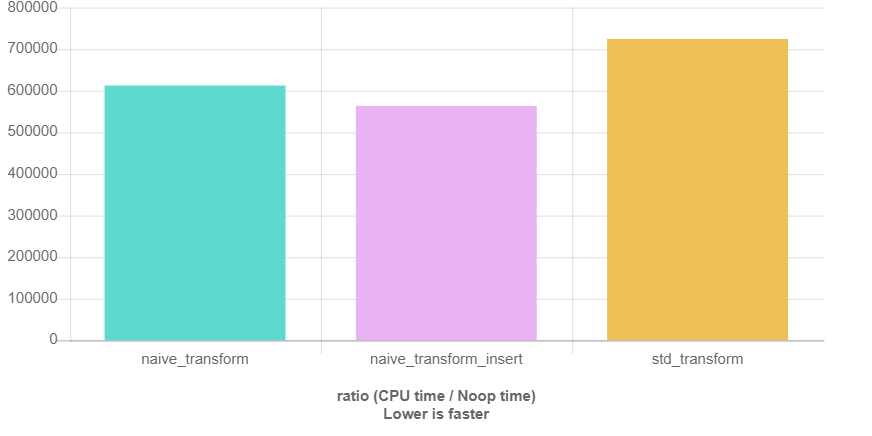
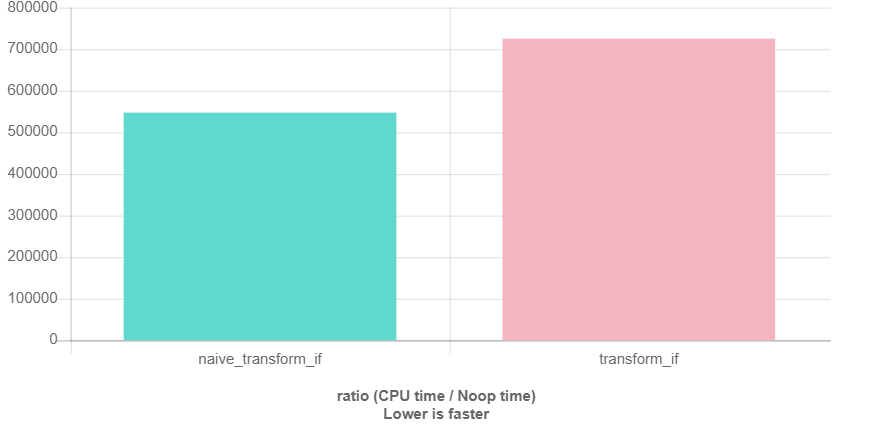
这里“native_”表示的是循环的实现,并且对于上面的每个代码片段都有一个测量。容器包含100000个Employee的结构体,结构体的名字是随机的“uniqueName_1”到“uniqueName_100000”。
我不去分析为什么算法在map插入方面表现更差,我能想到的最好的猜想是insert_iterator在大多数情况下有错误的位置指示(这里是hin,我感觉是写错了,应该是hint)。使用排序过的的输入针对于vector下运行相同的基准测试看起来完全不同。不过可以看的出来,算法和普通的循环在性能的比较上差异很小。
如果使用ranges呢
C++20我们引入了Ranges,拷贝自定义容器中的元素可能实现是这样:
OtherContainer<Employee> source;
auto employees = source | std::ranges::to_vector;
留给你来看是不是比迭代器范围的构造函数写法更加简单呢,对我来说看起来更加的优雅。不过我还没有进行性能测试。
transform_if的那个例子可能实现是这样的:
auto salariesByName = employees
| std::view::filter([](auto const& employee) {
return !employee.isManager();
})
| std::view::transform([](auto const& employee) {
return std::make_pair(
employee.uniqueName(),
employee.salary()
);
})
| to<std::map>;
也可以看到和之前类似的两个lambda表达式,不过更加结构化化,因为每个lambda被传递给一个具有描述性名称的函数。个人来说,我还是更加喜欢for循环,因为它更加紧凑。但是,如果有更多的需求,循环将很快变得不那么明显了。
总结
优先使用算法的准则依然有效:无论什么时候,如果你看到了for循环,确认下是不是可以被算法替代或者ranges,然后这个准则更像一个指导方针:不要盲目跟随,而是要有意识地做出选择,选择那些更简单、更易读的方法,并注意其他替代方法,比如迭代器范围构造函数。
尾
以上便是全文了,作者其实是想让大家选择最简单有效的方法,而不是盲目推崇算法,有些情况下算法可能性能或者可读性上不如简单的for循环。不过有时也还是可以选择算法,还需要根据你的实际情况进行调整。假如说你的for循环中内容很多,或许使用算法就会更加高效和可读。再比如说
c++17引入的并行算法。
ref
- https://arne-mertz.de/2019/05/algorithms-and-the-kiss-principle
- https://en.wikipedia.org/wiki/KISS_principle
- https://channel9.msdn.com/Events/GoingNative/2013/Cpp-Seasoning
- https://www.youtube.com/watch?v=2olsGf6JIkU
- https://en.cppreference.com/w/cpp/container/map/insert
- https://en.cppreference.com/w/cpp/algorithm/transform
- https://arne-mertz.de/2015/03/simple-and-clean-code-vs-performance/
- http://quick-bench.com/
- https://arne-mertz.de/2017/01/ranges-stl-next-level/















 425
425











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









