







1、RDD的缓存(cache和persist)
spark最重要一个能力就是:在不同的操作中把数据集缓存(cache)或存留(persist)在内存(memory)
中。当持久化一个RDD后,每个节点都会把计算的分片的结果保存在内存中,之后可以对此数据集在其他action中
再次使用。这使得后续的action变得迅速(通常快10x)[1].
2、缓存的级别
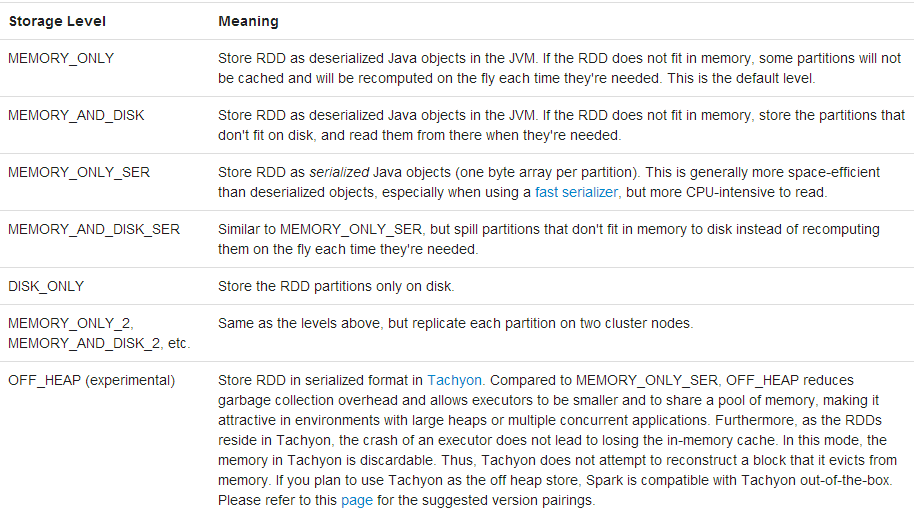
源码在:package org.apache.spark.storage这个包,官方给出的各个级别的意思如下:
3、cache和persist关系
RDD缓存函数persist和cache关系如下(附录:源码1):

从源码发现其实cache就是persist(StorageLevel.MEMORY_ONLY),也就是说我们选择缓存的时候是把数据缓存在内存中的(memory)。這样加快了数据在再次使用的调用速度。我们再来查看最核心函数:
persist(newLevel: StorageLevel, allowOverride: Boolean),
StorageLevel:存储的级别,
allowOverride:RDD1转换为RDD2之后RDD2是否重写它之前定义的级别
存储部分如下:
// If this is the first time this RDD is marked for persisting, register it // with the SparkContext for cleanups and accounting. Do this only once. if (storageLevel == StorageLevel.NONE) { sc.cleaner.foreach(_.registerRDDForCleanup(this)) sc.persistRDD(this) } storageLevel = newLevel this它的存储是用sparkcontext来进行缓存这个RDD的:第一次调用的时候,清理缓存,然后进行登记,每个cache的RDD只做一次。
private[spark] def cleaner: Option[ContextCleaner] = _cleaner
private var _cleaner: Option[ContextCleaner] = None
registerRDDForCleanup函数如下:
/** Register a RDD for cleanup when it is garbage collected. */ def registerRDDForCleanup(rdd: RDD[_]): Unit = { registerForCleanup(rdd, CleanRDD(rdd.id)) }之后用sc.persistRDD(this)进行注册:
/** * Register an RDD to be persisted in memory and/or disk storage */ private[spark] def persistRDD(rdd: RDD[_]) { persistentRdds(rdd.id) = rdd }
// Keeps track of all persisted RDDs private[spark] val persistentRdds = { val map: ConcurrentMap[Int, RDD[_]] = new MapMaker().weakValues().makeMap[Int, RDD[_]]() map.asScala }用persistentRdds这个函数进行跟踪所有进行缓存的函数,它就用一个hashmap进行存储的,形式是:[Int, RDD[_]]
类型为:
new MapMaker().weakValues().makeMap[Int, RDD[_]]()
我们知道我们创建一个RDD时候,系统会分配一个id给这个RDD(看http://blog.csdn.net/legotime/article/details/51223572),那么这个[Int, RDD[_]]中的Int存储的就是这个id
4、RDD的存储
我们从调用数据的角度来分析,需要数据的时候,是怎么拿数据的。我们知道真正对RDD进行动刀的是action,也就是说当一个stage的ResultTask触发,我们才进行存储,我们查看ResultTask(源码2),在runTask中发现调用了RDD的iterator,下面我们看看RDD中iterator是什么,源码如下:
/** * Internal method to this RDD; will read from cache if applicable, or otherwise compute it. * This should ''not'' be called by users directly, but is available for implementors of custom * subclasses of RDD. */ final def iterator(split: Partition, context: TaskContext): Iterator[T] = { if (storageLevel != StorageLevel.NONE) { getOrCompute(split, context) } else { computeOrReadCheckpoint(split, context) } }我们发现iterator会判断这个存储级别是否为NONE,NONE的值如下:
val NONE = new StorageLevel(false, false, false, false)
class StorageLevel private( private var _useDisk: Boolean, private var _useMemory: Boolean, private var _useOffHeap: Boolean, private var _deserialized: Boolean, private var _replication: Int = 1) extends Externalizable {/*集合体*/}如果判断这个存储级别不是NONE,也就是说之前已经cache了,那么会调用getOrCompute函数,getOrCompute如下: 首先,我们输入blockid和存储级别(storageLevel):会向blockManager发送请求,是否可以直接拿还是需要计算
private[spark] def getOrCompute(partition: Partition, context: TaskContext): Iterator[T] = { val blockId = RDDBlockId(id, partition.index) //获取RDD的blockID var readCachedBlock = true // This method is called on executors, so we need call SparkEnv.get instead of sc.env. SparkEnv.get.blockManager.getOrElseUpdate(blockId, storageLevel, () => { readCachedBlock = false computeOrReadCheckpoint(partition, context) }) match { case Left(blockResult) => if (readCachedBlock) { val existingMetrics = context.taskMetrics().registerInputMetrics(blockResult.readMethod) existingMetrics.incBytesReadInternal(blockResult.bytes) new InterruptibleIterator[T](context, blockResult.data.asInstanceOf[Iterator[T]]) { override def next(): T = { existingMetrics.incRecordsReadInternal(1) delegate.next() } } } else { new InterruptibleIterator(context, blockResult.data.asInstanceOf[Iterator[T]]) } case Right(iter) => new InterruptibleIterator(context, iter.asInstanceOf[Iterator[T]]) } }
如果存在,那么我们就检索我们的block,如果不存在那么我们就提供` makeiterator `方法,这个方法就是处理:
() => {
readCachedBlock = false
computeOrReadCheckpoint(partition, context)}
它的作用就是如果我们想要的block不存在,那么就调用computeOrReadCheckpoint(partition, context)这个函数,具体getOrElseUpdate函数如下
def getOrElseUpdate( blockId: BlockId, level: StorageLevel, makeIterator: () => Iterator[Any]): Either[BlockResult, Iterator[Any]] = { // Initially we hold no locks on this block. doPut(blockId, IteratorValues(makeIterator), level, keepReadLock = true) match { //我们调用的block不存在,那么需要计算 case None => // doPut() didn't hand work back to us, so the block already existed or was successfully // stored. Therefore, we now hold a read lock on the block. val blockResult = get(blockId).getOrElse { // Since we held a read lock between the doPut() and get() calls, the block should not // have been evicted, so get() not returning the block indicates some internal error. releaseLock(blockId) throw new SparkException(s"get() failed for block $blockId even though we held a lock") } Left(blockResult) //我们调用的block已经存在了 case Some(failedPutResult) => // The put failed, likely because the data was too large to fit in memory and could not be // dropped to disk. Therefore, we need to pass the input iterator back to the caller so // that they can decide what to do with the values (e.g. process them without caching). Right(failedPutResult.data.left.get) } }
doput是存储管理,代码量很大,所以打算放到存储那块一起分析,不过可以从它返回的信息,来补充我们需要的分
析资料。doput的返回的信息如下:
* @return `Some(PutResult)` if the block did not exist and could not be successfully cached, * or None if the block already existed or was successfully stored (fully consuming * the input data / input iterator).函数
private def doPut( blockId: BlockId, data: BlockValues, level: StorageLevel, tellMaster: Boolean = true, effectiveStorageLevel: Option[StorageLevel] = None, keepReadLock: Boolean = false): Option[PutResult] = {/*集合体*/}
/** * Compute an RDD partition or read it from a checkpoint if the RDD is checkpointing. */ private[spark] def computeOrReadCheckpoint(split: Partition, context: TaskContext): Iterator[T] = { if (isCheckpointedAndMaterialized) { firstParent[T].iterator(split, context) } else { compute(split, context) //从新计算 } }
综上所述,分析到最后如果都没有找到我们所需,那么就会先看看有没有checkpoint,最后在重新计算我们所需。下面是寻找数据的流程图:

附录
源码1
/** * Mark this RDD for persisting using the specified level. * * @param newLevel the target storage level * @param allowOverride whether to override any existing level with the new one */ private def persist(newLevel: StorageLevel, allowOverride: Boolean): this.type = { // TODO: Handle changes of StorageLevel if (storageLevel != StorageLevel.NONE && newLevel != storageLevel && !allowOverride) { throw new UnsupportedOperationException( "Cannot change storage level of an RDD after it was already assigned a level") } // If this is the first time this RDD is marked for persisting, register it // with the SparkContext for cleanups and accounting. Do this only once. if (storageLevel == StorageLevel.NONE) { sc.cleaner.foreach(_.registerRDDForCleanup(this)) sc.persistRDD(this) } storageLevel = newLevel this } /** * Set this RDD's storage level to persist its values across operations after the first time * it is computed. This can only be used to assign a new storage level if the RDD does not * have a storage level set yet. Local checkpointing is an exception. */ def persist(newLevel: StorageLevel): this.type = { if (isLocallyCheckpointed) { // This means the user previously called localCheckpoint(), which should have already // marked this RDD for persisting. Here we should override the old storage level with // one that is explicitly requested by the user (after adapting it to use disk). persist(LocalRDDCheckpointData.transformStorageLevel(newLevel), allowOverride = true) } else { persist(newLevel, allowOverride = false) } } /** Persist this RDD with the default storage level (`MEMORY_ONLY`). */ def persist(): this.type = persist(StorageLevel.MEMORY_ONLY) /** Persist this RDD with the default storage level (`MEMORY_ONLY`). */ def cache(): this.type = persist() /** * Mark the RDD as non-persistent, and remove all blocks for it from memory and disk. * * @param blocking Whether to block until all blocks are deleted. * @return This RDD. */ def unpersist(blocking: Boolean = true): this.type = { logInfo("Removing RDD " + id + " from persistence list") sc.unpersistRDD(id, blocking) storageLevel = StorageLevel.NONE this } /** Get the RDD's current storage level, or StorageLevel.NONE if none is set. */ def getStorageLevel: StorageLevel = storageLevel
源码2
private[spark] class ResultTask[T, U]( stageId: Int, stageAttemptId: Int, taskBinary: Broadcast[Array[Byte]], partition: Partition, locs: Seq[TaskLocation], val outputId: Int, _initialAccums: Seq[Accumulator[_]] = InternalAccumulator.createAll()) extends Task[U](stageId, stageAttemptId, partition.index, _initialAccums) with Serializable { @transient private[this] val preferredLocs: Seq[TaskLocation] = { if (locs == null) Nil else locs.toSet.toSeq } override def runTask(context: TaskContext): U = { // Deserialize the RDD and the func using the broadcast variables. val deserializeStartTime = System.currentTimeMillis() val ser = SparkEnv.get.closureSerializer.newInstance() val (rdd, func) = ser.deserialize[(RDD[T], (TaskContext, Iterator[T]) => U)]( ByteBuffer.wrap(taskBinary.value), Thread.currentThread.getContextClassLoader) _executorDeserializeTime = System.currentTimeMillis() - deserializeStartTime metrics = Some(context.taskMetrics) func(context, rdd.iterator(partition, context)) } // This is only callable on the driver side. override def preferredLocations: Seq[TaskLocation] = preferredLocs override def toString: String = "ResultTask(" + stageId + ", " + partitionId + ")" }
参考文献:
http://spark.apache.org/docs/latest/programming-guide.html#rdd-persistence














 1620
1620











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









