







1、闲聊
在讲高斯混合模型,我们先抛开一切,来一些推导。推导前,假设你认可两个统计学基础的两个定理
(1)大数定理(2)中心极限定理

联合实际情况就是说,假如我们坐在广州地铁1号线的某个地方进行蹲点1天,记录下地铁全部女性的身高。这一天下来她们的身高的均值和方差。和我们第二天继续第一天的工作得到的均值和方差是接近的。而且服从高斯分布。
下面可以证明每个点产生的概率值联合起来为什么是一个“钟形”曲线。也就是证明高斯的分布函数形式。

有了這个关于高斯密度分布函数,那么我们在上面取一个x就可以得到一个概率。它的意义在于,我们某一天又在哪
里蹲点。我们就可以说下一个女人身高为x的概率是多少。但是這里有两个假设
(1)任何一个女性都有可能在這里出现
(2)整个过程没有女性死亡和出生
但是现在细分下去就会出现的问题是,身高和区域有关
也就是说在北京地铁蹲点得到的身高比广州地铁蹲点得到身高会“普遍更高”。也就是出现我们在预测下一个的时候x,输入x到高斯分布函数函数中,得到的值会比真值“更低”或者“更高”的现象。这就说明一点高斯分布是和群体有关。
也可以得到一点的是:不同的群体,高斯分布的均值和方差不一样。
就是根据这样的思想,所以就可以利用高斯分布来聚类。
2、高斯混合模型(Gaussian Mixture Models (GMMs))
高斯和密度函数估计是一种参数化模型,有SGM(Single Gaussian Model)和GMM(Gaussian Mixture Model)

3、EM算法
对于EM算法可以参考andrew NG 的 <The EM Algorithm>[1],下面来简述EM算法步骤:
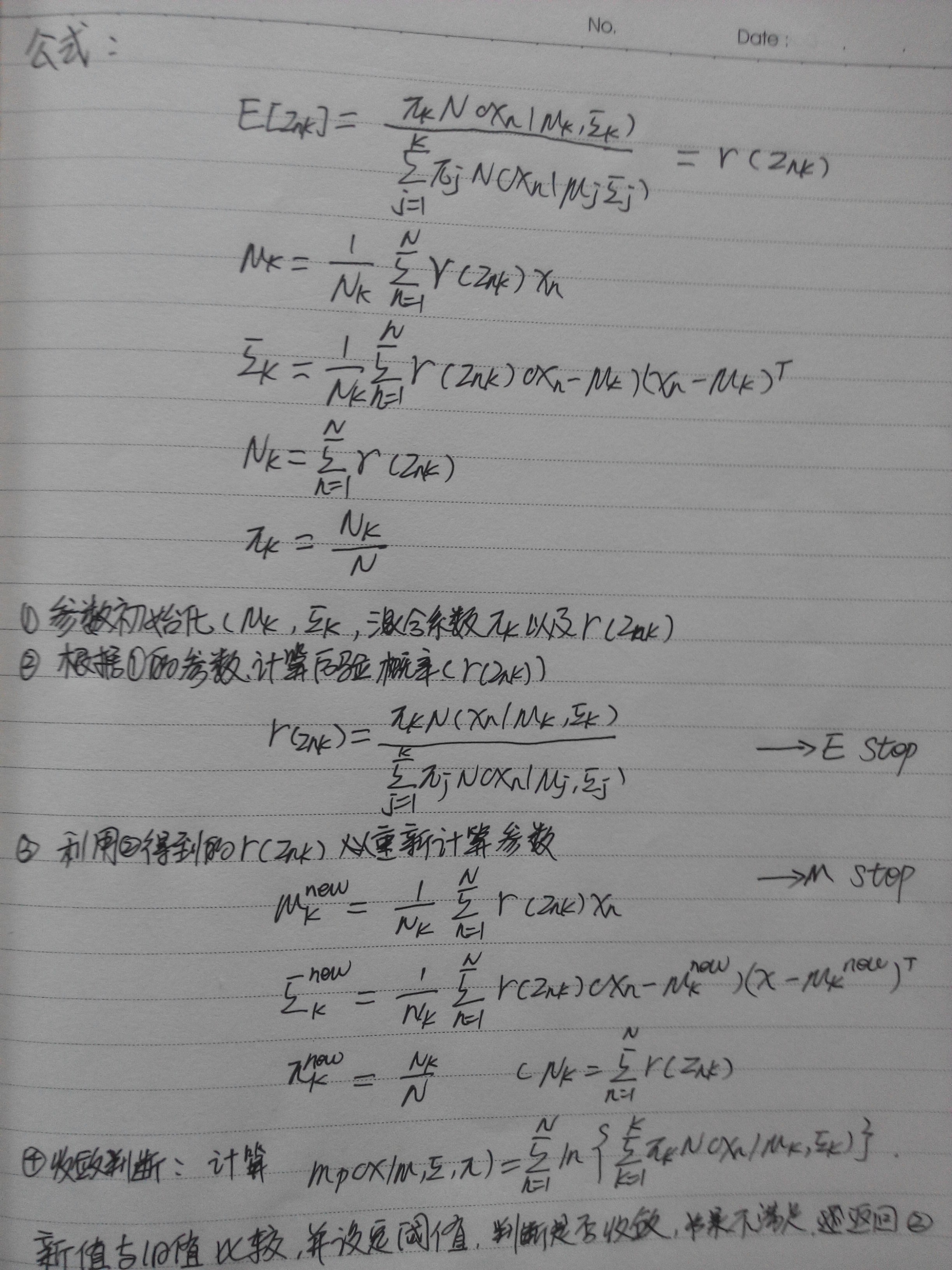
4、Matlab实现高斯混合模型分类
load gmm_data.txt
%gmm_data.txt为spark源码 data下的数据
X = gmm_data';
%设置分类数 k
k = 2;
[z,model,llh] = myEM(X,k);
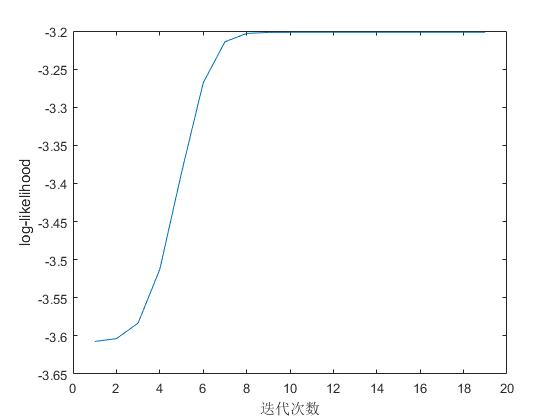
figure
plot(llh);
xlabel('迭代次数')
ylabel('log-likelihood')
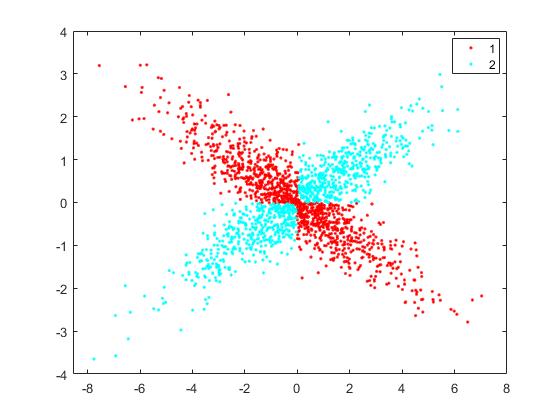
figure
gscatter(X(1,:),X(2,:),z)
%模型参数
model.E
%ans(:,:,1) =
% 4.9060 -2.0062
% -2.0062 1.0112
%ans(:,:,2) =
% 4.7809 1.8768
% 1.8768 0.9149
model.mu
%ans =
% -0.1044 0.0722
% 0.0429 0.0167
model.w
%ans =
% 0.5196 0.4804
function[label,model,llh]=myEM(X,k)
% 输入:
% X 是输入样本集
% k 是待分类别数
% 返回
% label: X对应的标签
% model: GMMS
% llh::log之后的极大似然(log-likelihood)
%指标
tol = 1e-8;
maxIter = 1000;
%初始化
n = length(X);
label = ceil(k*rand(1,n));
Z = full(sparse(1:n,label,1,n,k,n));
llh = -inf(1,maxIter);
%迭代优化
for iter = 2:maxIter
[~,label(1,:)] = max(Z,[],2);
model = M_Step(X,Z); %计算 model
[Z, llh(iter)] = E_Step(X,model);
if abs(llh(iter)-llh(iter-1)) < tol*abs(llh(iter)); break; end;
end
llh = llh(2:iter);
function model = M_Step(X,Z)
[d,n] = size(X);%d是X的维度
k = size(Z,2);%k 是类别
nk = sum(Z,1);% 计算类别下的数目
w = nk/n;%权重
mu = bsxfun(@times, X*Z, 1./nk);%计算mu
E = zeros(d,d,k);%协方差矩阵
r = sqrt(Z);
for i = 1:k
Xo = bsxfun(@minus,X,mu(:,i));
Xo = bsxfun(@times,Xo,r(:,i)');
E(:,:,i) = Xo*Xo'/nk(i)+eye(d)*(1e-6);
end
model.mu = mu;
model.E = E;
model.w = w;
function [Z, llh] = E_Step(X, model)
mu = model.mu;
E = model.E;
w = model.w;
n = size(X,2);
k = size(mu,2);
Z = zeros(n,k);
for i = 1:k
Z(:,i) = loggausspdf(X,mu(:,i),E(:,:,i));
end
Z = bsxfun(@plus,Z,log(w));
T = logsumexp(Z,2);
llh = sum(T)/n;
Z = exp(bsxfun(@minus,Z,T));
function y = loggausspdf(X, mu, E)
d = size(X,1);
X = bsxfun(@minus,X,mu);
U= chol(E);
Q = U'\X;
q = dot(Q,Q,1);
c = d*log(2*pi)+2*sum(log(diag(U)));
y = -(c+q)/2;
图像结果:
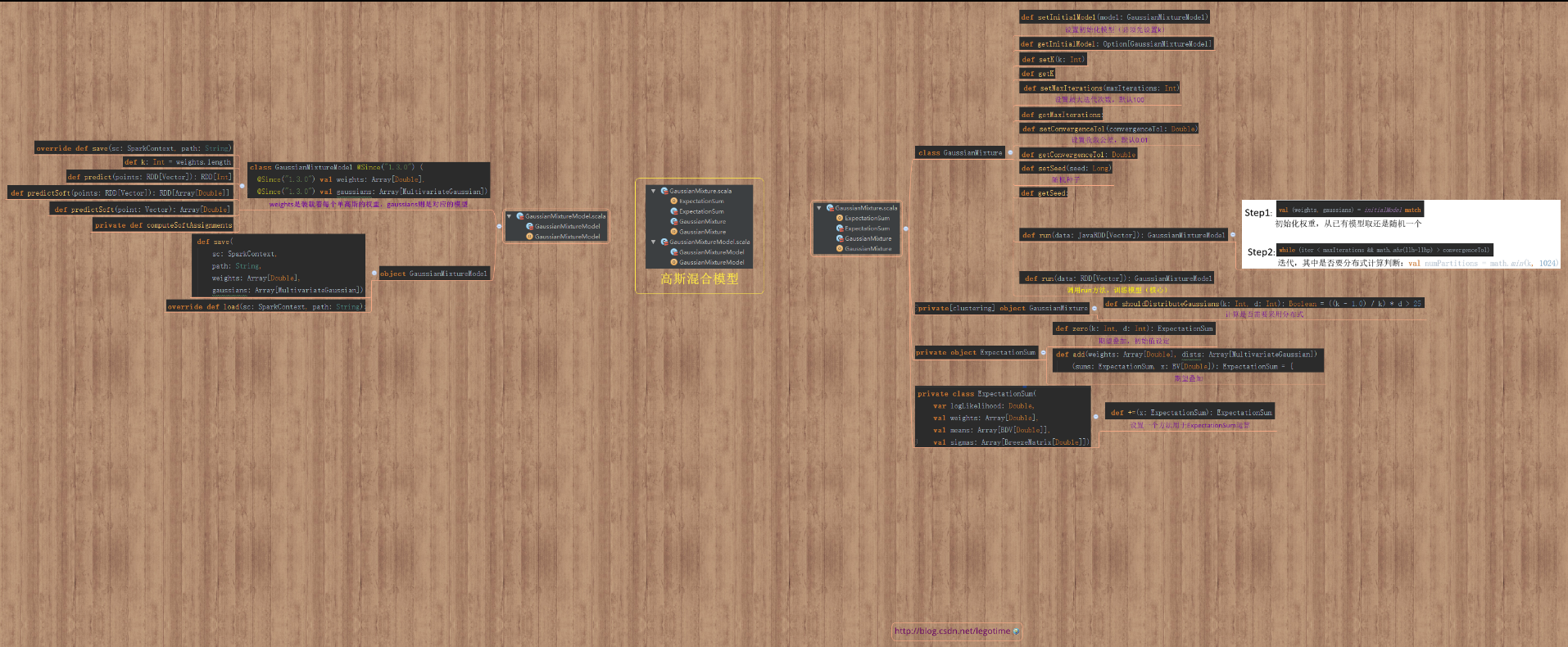
Spark源码图(大图见附录)
Spark实验
import org.apache.spark.{SparkConf, SparkContext} import org.apache.spark.mllib.clustering.{GaussianMixture} import org.apache.spark.mllib.linalg.Vectors object GaussianMixtureExample { def main(args: Array[String]) { val conf = new SparkConf().setAppName("GaussianMixtureExample").setMaster("local") val sc = new SparkContext(conf) // Load and parse the data val data = sc.textFile("C:\\Users\\alienware\\IdeaProjects\\sparkCore\\data\\mllib\\gmm_data.txt") val parsedData = data.map(s => Vectors.dense(s.trim.split(' ').map(_.toDouble))).cache() // Cluster the data into two classes using GaussianMixture val gmm = new GaussianMixture().setK(2).run(parsedData) // Save and load model //gmm.save(sc, "target/org/apache/spark/GaussianMixtureExample/GaussianMixtureModel") //val sameModel = GaussianMixtureModel.load(sc,"target/org/apache/spark/GaussianMixtureExample/GaussianMixtureModel") // output parameters of max-likelihood model for (i <- 0 until gmm.k) { println("weight=%f\nmu=%s\nsigma=\n%s\n" format (gmm.weights(i), gmm.gaussians(i).mu, gmm.gaussians(i).sigma)) } /** * weight=0.481027 mu=[0.07217189762937483,0.0166693219789788] sigma= 4.776177833343064 1.874381267946877 1.874381267946877 0.9140182655978455 weight=0.518973 mu=[-0.10458625214505539,0.042897423244107544] sigma= 4.910485828947743 -2.008602407570325 -2.008602407570325 1.0121329041756117 */ sc.stop() } }
参考文献
http://cs229.stanford.edu/notes/cs229-notes8.pdf














 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









