









这例子是我查询增量导入数据的例子,增量导入语句deltaQuery:select id from article where cdate>'${dataimporter.last_index_time} ,此语句是先查询所有增量id然后在拼接到deltaImportQuery="select id,title,catid from article where id='${dataimporter.delta.id}' 查询增量的数据,按照官方这种写法没错,但是我查到多少id就会发起多少请求去拼接,影响相率,何不一次性查询全部增量数据呢于是对查询语句进行了改造
<dataConfig>
<dataSource driver="com.mysql.jdbc.Driver" url="jdbc:mysql://localhost:3306/blog" user="root" password="admin"/>
<document>
<entity name="article" query="select id,title,catid from article" deltaImportQuery="select id,title,catid from article where id='${dataimporter.delta.id}'" deltaQuery="select id from article where cdate > '${dataimporter.last_index_time}'">
<field column="id" name="id" />
<field column="title" name="title" />
<field column="title" name="suggest"/>
<entity name="category" query="select catname from category where id=${article.catid}">
<field column="catname" name="catname"/>
</entity>
</entity>
</document>
</dataConfig>
增量
可以改造成deltaQuery 查询时只查询一次 sql语句改成select -1 id from dual,改造成这样增量时获取id结果只有一条数据,然后按照全量方式去一次性获取增量的数据,deltaImportQuery改造为select id,title,catid from article where cdate > '${dataimporter.last_index_time}'
改造后的完整语句
<dataConfig>
<dataSource driver="com.mysql.jdbc.Driver" url="jdbc:mysql://localhost:3306/blog" user="root" password="admin"/>
<document>
<entity name="article" query="select id,title,catid from article" deltaImportQuery="select id,title,catid from article where cdate > '${dataimporter.last_index_time}'" deltaQuery="select -1 id from dual">
<field column="id" name="id" />
<field column="title" name="title" />
<field column="title" name="suggest"/>
<entity name="category" query="select catname from category where id=${article.catid}">
<field column="catname" name="catname"/>
</entity>
</entity>
</document>
</dataConfig>
改造语句前增量Request:42个请求
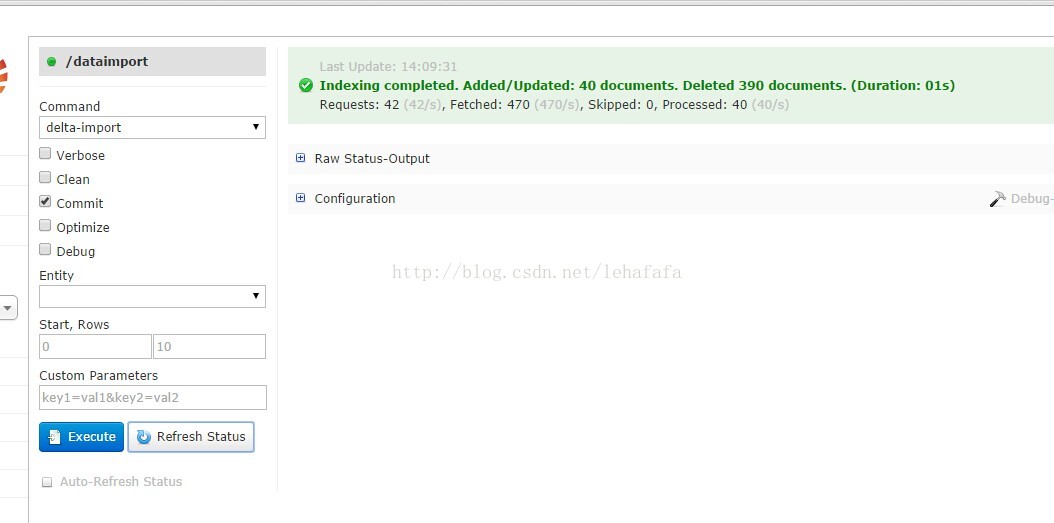
改造语句后增量Request:3个请求
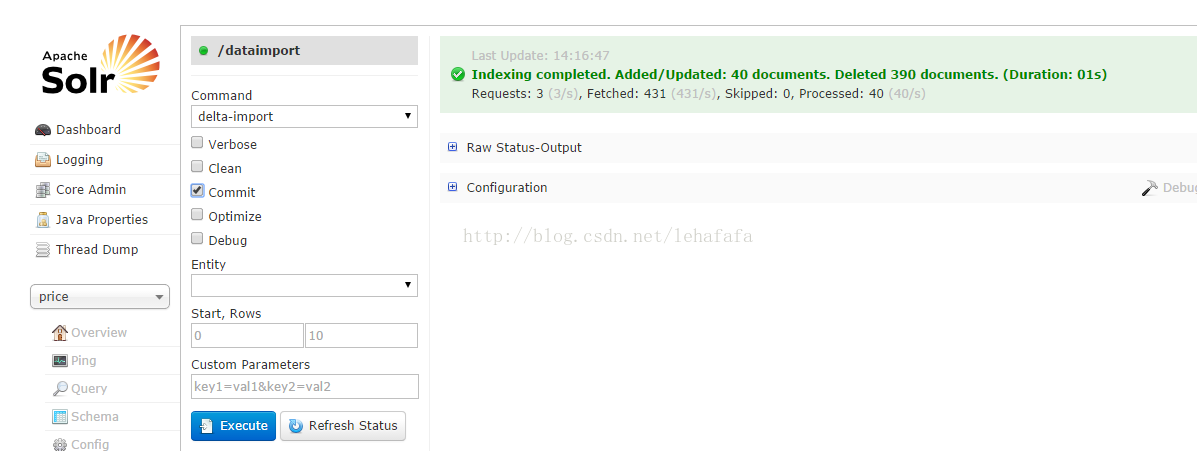














 11万+
11万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









