







(1)数据时效性
日常工作中,我们一般会先把数据存储在表,然后对表的数据进行加工、分析。既然先存储在表中,那就会涉及到时效性概念。如果我们是处理以年,月、周为单位的级别的数据处理,进行统计分析,那么最新数据与当前相差几周 几月或许都没太多影响。
但是如果我们处理的是以天为单位或者一小时甚至更小粒度的数据处理,那么就要求数据的时效性更高了。比如:对车辆的报警、车辆定位计算、网站的监控、等等,这些场景下都需要工作人员根据信息立即作出响应,如果按照以往传统的统一收集数据,再存到数据库中,再取出来进行分析,或许会因为时间跨度较大,导致致信息滞后,无法满足高时效性的需求。
(2)流处理与批处理


- Batch Analytics,右边是 Streaming Analytics。批量计算: 统一收集数据->存储到DB->对数据进行批量处理,对数据实时性邀请不高,比如生成离线报表、月汇总,支付宝年度账单(一年结束批处理计算)
- Streaming Analytics 流式计算,顾名思义,就是对数据流进行处理,如使用流式分析引擎如 Storm,Flink 实时处理分析数据,应用较多的场景如 实时报表、车辆报警计算等等。
(3)流处理与批处理对比
数据时效性不同
流处理,即数据流式计算,实时性高,低延迟。
批处理,即数据批量处理,实时性地,高延迟。
数据特征不同
流式计算的数据一般是动态的,即无边界流,没有很显示的知道数据什么时候结束,比如车辆定位。
批量处理计算的数据一般是静态的,即有边界流,比如读取文件中内容,或者读取数据库中某一时段的内容等等。
运行方式不同
流式计算由于数据是无边界的,不知道数据什么时候结束,所以计算任务是持续性的。
批量计算是每读取一次有边界流计算结束后任务便完成结束了。
应用场景不同
流式计算作用于,高时效性,低延迟性业务场景,例如实时车辆里程计算、报警计算等
批量处理作用于对数据时效性不高的业务场景,例如天报表(次日凌晨读取前一天数据进行批处理汇总计算)、年报表等等
(4)流批一体API(DataStream)


什么是数据流?
DataStream API的名称来自特殊DataStream类,该特殊类用于表示Flink程序中的数据集合。您可以将它们视为包含重复项的不可变数据集合。此数据可以是有限的,也可以是无限制的,用于处理它们的API是相同的。
Flink DataStream API编程指南
Flink中的DataStream程序是常规程序,可对数据流实施转换(例如,过滤,更新状态,定义窗口,聚合)。最初从各种来源(例如,消息队列,套接字流,文件)创建数据流。结果通过接收器返回,接收器可以例如将数据写入文件或标准输出(例如命令行终端)。Flink程序可以在各种上下文中运行,既可以独立运行,也可以嵌入其他程序中。执行可以在本地JVM或许多计算机的群集中进行。
DataStream API 支持批执行模式
Flink 的核心 API 最初是针对特定的场景设计的,尽管 Table API / SQL 针对流处理和批处理已经实现了统一的 API,但当用户使用较底层的 API 时,仍然需要在批处理(DataSet API)和流处理(DataStream API)这两种不同的 API 之间进行选择。鉴于批处理是流处理的一种特例,将这两种 API 合并成统一的 API,有一些非常明显的好处,比如:
**可复用性:**作业可以在流和批这两种执行模式之间自由地切换,而无需重写任何代码。因此,用户可以复用同一个作业,来处理实时数据和历史数据。
维护简单:统一的 API 意味着流和批可以共用同一组 connector,维护同一套代码,并能够轻松地实现流批混合执行,例如 backfilling 之类的场景。
考虑到这些优点,社区已朝着流批统一的 DataStream API 迈出了第一步:支持高效的批处理(FLIP-134)
手动流批处理方式选择
RuntimeExecutionMode.STREAMING 表示使用流处理模式
RuntimeExecutionMode.BATCH:表示使用批处理模式
RuntimeExecutionMode.AUTOMATIC:表示根据数据源自行选择(有限的数据肯定是批嘛,无限的自然是流…)
// 1.准备环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 设置运行模式
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
DataStream计算程序开发流程:
1.准备环境-env 设置运行模式
2.准备数据-source
3.处理数据-transformation
4.输出结果-sink
5.触发执行-execute (实际开发中使用execute执行后,程序会一直运行,注意try-catch,否则会因为异常导致整个计算程序挂掉)
Flink提供了多个层次的API供开发者使用,越往上抽象程度越高,使用起来越方便;越往下越底层,使用起来难度越大
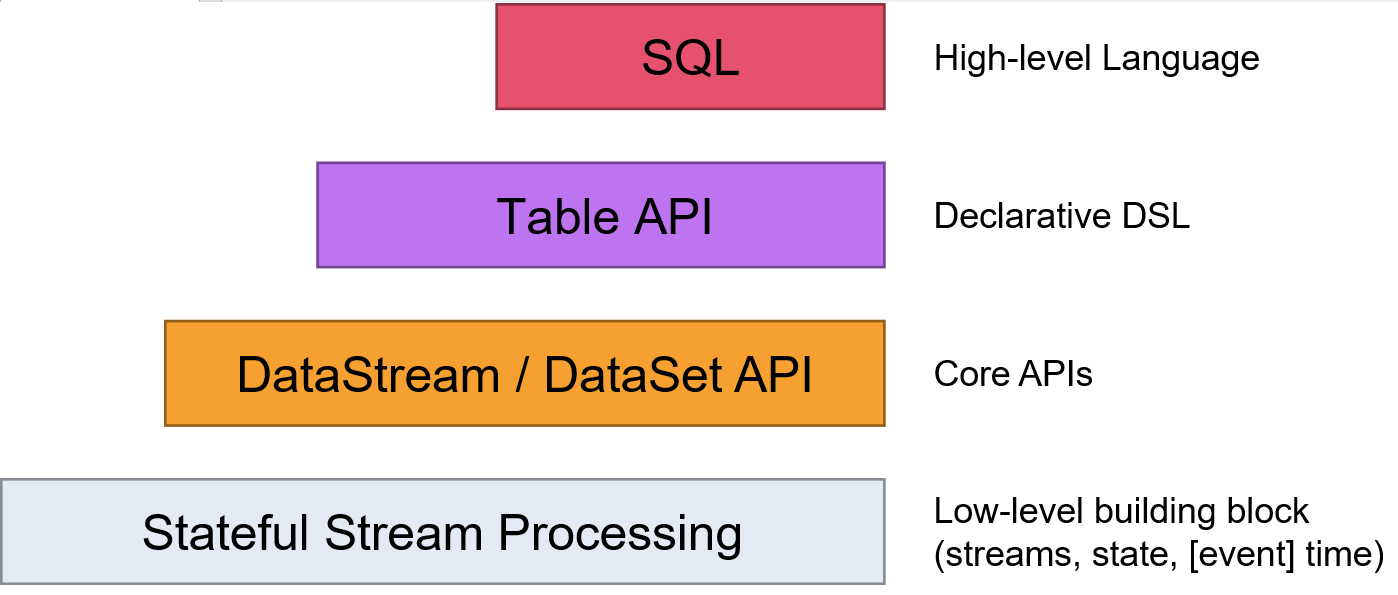
如图所示,flink甚至能够直接操作SQL来进行数据处理














 3258
3258











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









