






来源:数据STUDIO
在批量处理文件(后缀包括 ".csv"、".xlsx"、".xls"的文件)时,可能会出现同一个文件夹内同时存在不同编码的文件;亦或非"utf-8"格式的其他格式,即便相同格式也会出现有些文件能打开,而有些文件不能打开。
尤其是从SQL中导出的csv文件中,更容易出现因编码不同,使用pandas打开时报错的情况。
接下来介绍几种不同的解决方式,主要思想是将原始(编码)文件转换成目标(编码)文件utf-8,再用工具读取。

不使用任何三方包
一般转换方法
def correctSubtitleEncoding(filename,
newFilename,
encoding_from,
encoding_to='UTF-8'):
with open(filename, 'r', encoding=encoding_from) as fr:
with open(newFilename, 'w', encoding=encoding_to) as fw:
for line in fr:
fw.write(line[:-1]+'\r\n')
暴力转换
filelocation = ""
outputfilelocation = ""
try:
# open the CSV file
inputfile = open(filelocation, 'rb')
outputfile = open(outputfilelocation, 'w', encoding='utf-8')
for line in inputfile:
if line[-2:] == b'\r\n' or line[-2:] == b'\n\r':
output = line[:-2].decode('utf-8', 'replace') + '\n'
elif line[-1:] == b'\r' or line[-1:] == b'\n':
output = line[:-1].decode('utf-8', 'replace') + '\n'
else:
output = line.decode('utf-8', 'replace') + '\n'
outputfile.write(output)
outputfile.close()
except BaseException as error:
print("Error(18): opening CSV-file " + filelocation + " failed: " + str(error))
使用chardet模块
chardet模块有两种用法
1、检测特定页面的编码格式
with open(file, 'rb') as f:
rawdata = f.read()
detect(rawdata)
>>> {'confidence': 0.99, 'encoding': 'utf-8'}
结果分析: 其准确率99%的概率,编码格式为
'utf-8'
2、增量检测编码格式
def get_encoding_type(current_file):
detector.reset()
for line in file(current_file):
detector.feed(line)
if detector.done: break
detector.close()
return detector.result['encoding']
为了提高预测的准确性,基于
dector.feed()来实现持续的信息输入,在信息足够充足之后结束信息输入,给出相应的预测和判断。如果需要复用detector方法,需要进行
detector.reset()进行重置,从而可以复用。
自动检测原始文件编码,再转换。
import os
from chardet import detect
# get file encoding type
def get_encoding_type(file):
with open(file, 'rb') as f:
rawdata = f.read()
return detect(rawdata)['encoding']
from_codec = get_encoding_type(srcfile)
# add try: except block for reliability
try:
with open(srcfile, 'r', encoding=from_codec) as f, open(trgfile, 'w', encoding='utf-8') as e:
text = f.read() # 小文件使用read, 大文件使用chunks
e.write(text)
os.remove(srcfile) # 删除原始文件
os.rename(trgfile, srcfile) # 重命名新文件
except UnicodeDecodeError:
print('Decode Error')
except UnicodeEncodeError:
print('Encode Error')
使用codecs模块
codecs模块[1]
当python要做编码转换的时候,会借助于内部的编码,转换过程是这样的:
原有编码 -> 内部编码 -> 目的编码
python的内部是使用unicode来处理的,但是unicode的使用需要考虑的是它的编码格式有两种:
一是UCS-2,它一共有65536个码位,
另一种是UCS-4,它有2147483648g个码位。
对于这两种格式,python都是支持的,这个是在编译时通过--enable- unicode=ucs2或--enable-unicode=ucs4来指定的。
import sys
print(sys.maxunicode)
如果输出的值为
65535,那么就是UCS-2;如果输出是1114111就是UCS-4编码。
codecs专门用作编码转换
以下通过几个例子来初步了解下该模块的主要功能:
# 创建utf-8编码器
look = codecs.lookup("utf-8")
name = 'DataStudio'
# 把name编码为内部的 unicode
tem_name = look.decode(name)
# tem_name[0]是数据,tem_name[1]是长度,这个时候的类型是unicode
# 把内部编码的unicode转换为utf-8编码的字符串
name =look.encode(b[0])
# 用codecs提供的open方法来指定打开的文件的语言编码,
# 它会在读取的时候自动转换为内部unicode
file = codecs.open("dddd.txt", 'r', "big5")
CSV 转存 UTF-8 格式
import codecs
src="......\\xxxx.csv"
dst="......\\xxx_utf8.csv"
def ReadFile(filePath):
with codecs.open(filePath, "r") as f:
return f.read()
def WriteFile(filePath, u, encoding="utf-8"):
# with codecs.open(filePath,"w",encoding) as f:
with codecs.open(filePath, "wb") as f:
f.write(u.encode(encoding, errors="ignore"))
def CSV_2_UTF8(src, dst):
content = ReadFile(src)
WriteFile(dst, content, encoding="utf-8")
CSV_2_UTF8(src, dst)
UTF-8-SIG 转存 UTF-8
import codecs
src="......\\xxxx.csv"
dst="......\\xxx_utf8.csv"
def ReadFile(filePath,encoding="utf-8-sig"):
with codecs.open(filePath,"r",encoding) as f:
return f.read()
def WriteFile(filePath,u,encoding="utf-8"):
#with codecs.open(filePath,"w",encoding) as f:
with codecs.open(filePath,"wb") as f:
f.write(u.encode(encoding,errors="ignore"))
def UTF8_2_GBK(src,dst):
content = ReadFile(src,encoding="utf-8-sig")
WriteFile(dst,content,encoding="utf-8")
UTF8_2_GBK(src,dst)
综合以上方法
python中转换文件[2]
from __future__ import with_statement
import os
import sys
import codecs
from chardet.universaldetector import UniversalDetector
targetFormat = 'utf-8'
outputDir = 'converted'
detector = UniversalDetector()
def get_encoding_type(current_file):
detector.reset()
for line in file(current_file):
detector.feed(line)
if detector.done: break
detector.close()
return detector.result['encoding']
def convertFileBestGuess(filename):
sourceFormats = ['ascii', 'iso-8859-1']
for format in sourceFormats:
try:
with codecs.open(fileName, 'rU', format) as sourceFile:
writeConversion(sourceFile)
print('Done.')
return
except UnicodeDecodeError:
pass
def writeConversion(file):
with codecs.open(outputDir + '/' + fileName, 'w', targetFormat) as targetFile:
for line in file:
targetFile.write(line)
def convertFileWithDetection(fileName):
print("Converting '" + fileName + "'...")
format=get_encoding_type(fileName)
try:
with codecs.open(fileName, 'rU', format) as sourceFile:
writeConversion(sourceFile)
print('Done.')
return
except UnicodeDecodeError:
pass
print("Error: failed to convert '" + fileName + "'.")
# Off topic: get the file list and call convertFile on each file
# ...
这合并了原始的尝试多种格式,以及使用
chardet.universaldetector,不断尝试直到没有异常的转码方法。
使用Notepad++
巧用notepad++[3] 批量转换 ansi 和 utf8,notepad++中使用python脚本[4]
NotePad++下载地址[5]
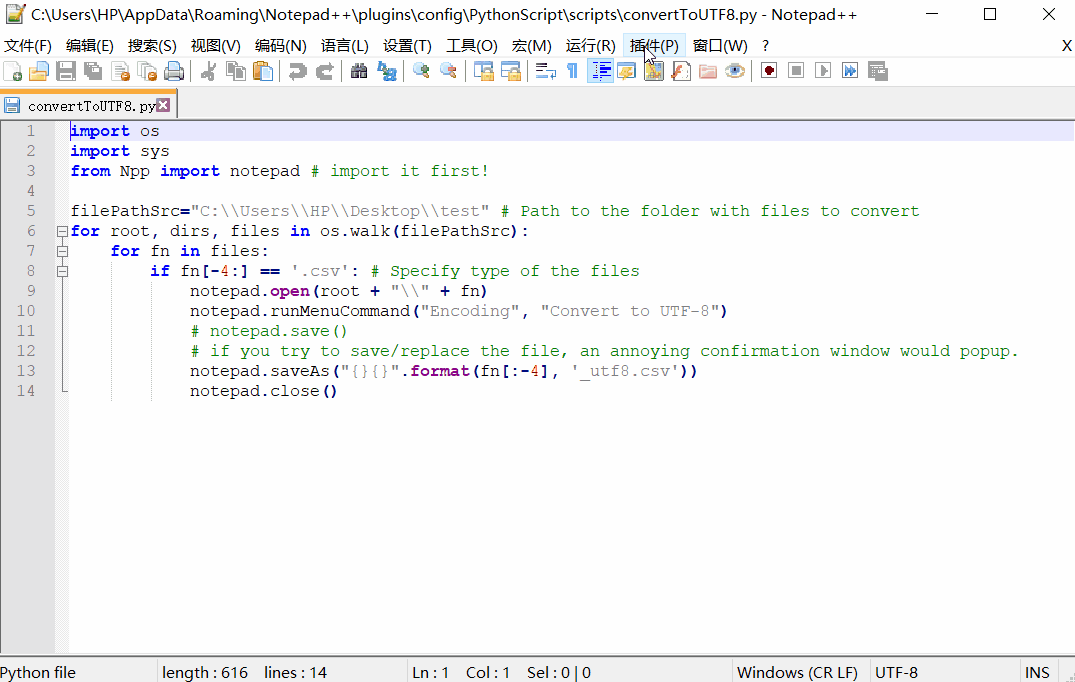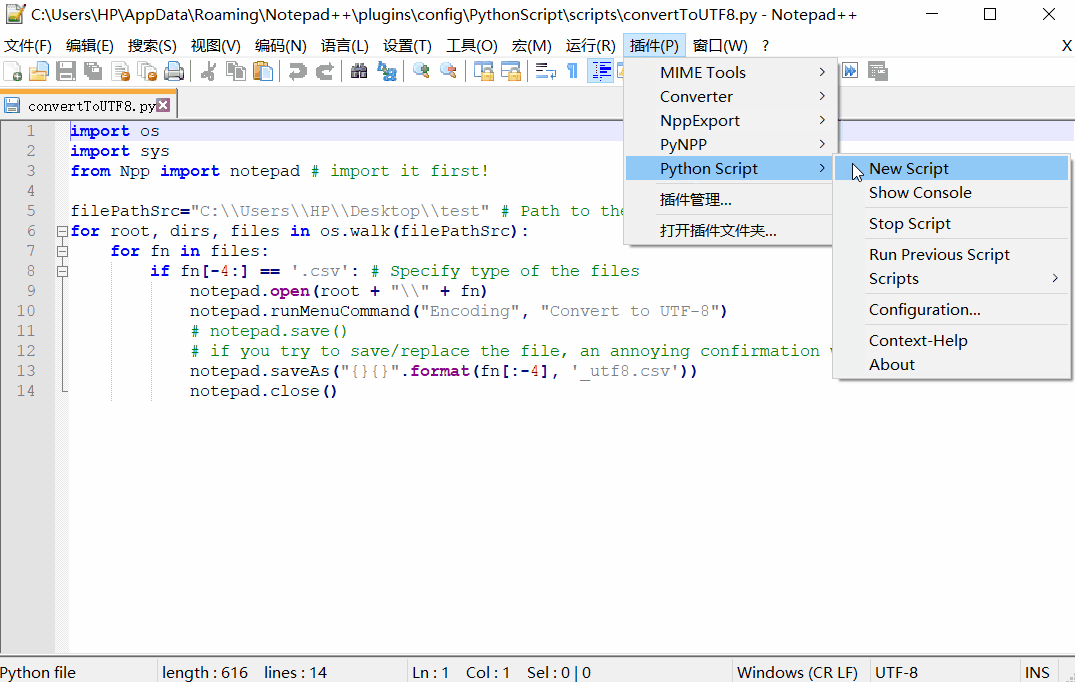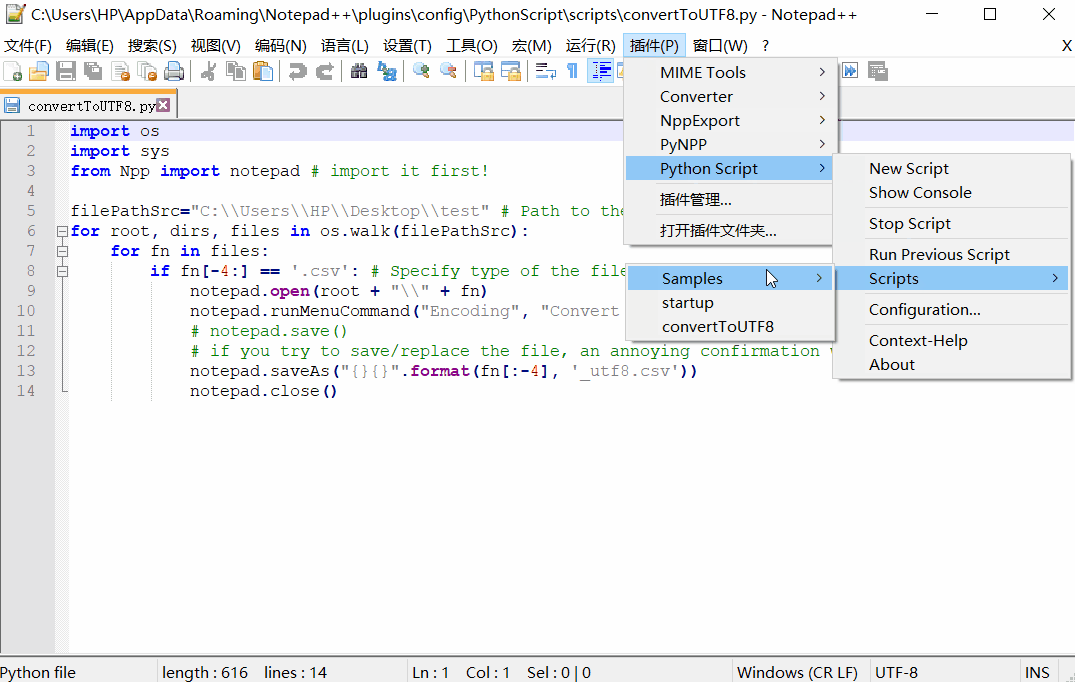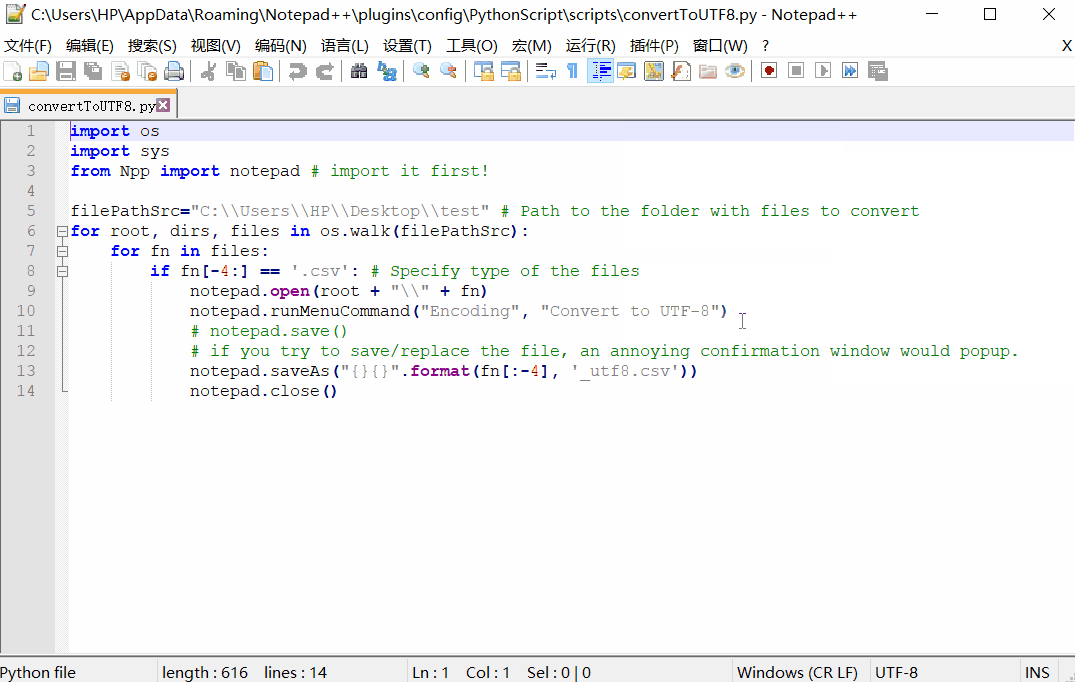
运行Notepad ++,然后打开菜单Plugins(插件)-> Plugin Manager(插件管理)-> Show Plugin Manager。
安装PythonScript(Python脚本)。安装插件后,重新启动应用程序。
选择菜单Plugins(插件)-> PythonScript(Python脚本)->New script(新建脚本)。
选择它的名称,然后加上以下代码。
convertToUTF8.py
import os
import sys
from Npp import notepad # import it first!
filePathSrc="C:\\Users\\" # Path to the folder with files to convert
for root, dirs, files in os.walk(filePathSrc):
for fn in files:
if fn[-4:] == '.csv': # Specify type of the files
notepad.open(root + "\\" + fn)
notepad.runMenuCommand("Encoding", "Convert to UTF-8")
# notepad.save()
# if you try to save/replace the file,
# an annoying confirmation window would popup.
notepad.saveAs("{}{}".format(fn[:-4], '_utf8.csv'))
notepad.close()
动画演示
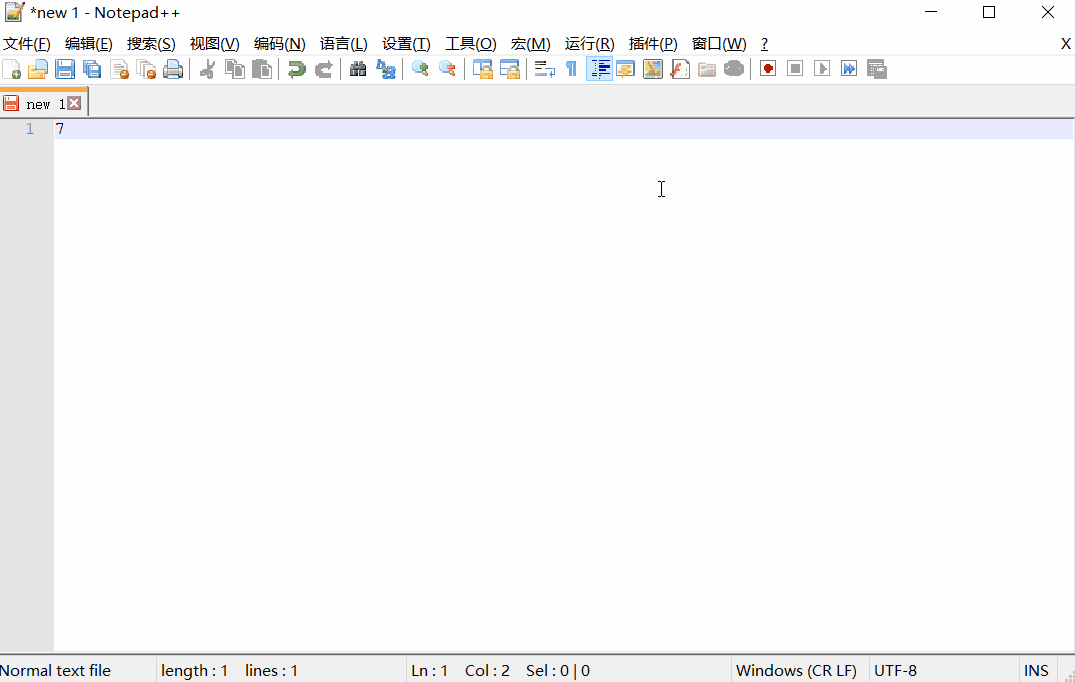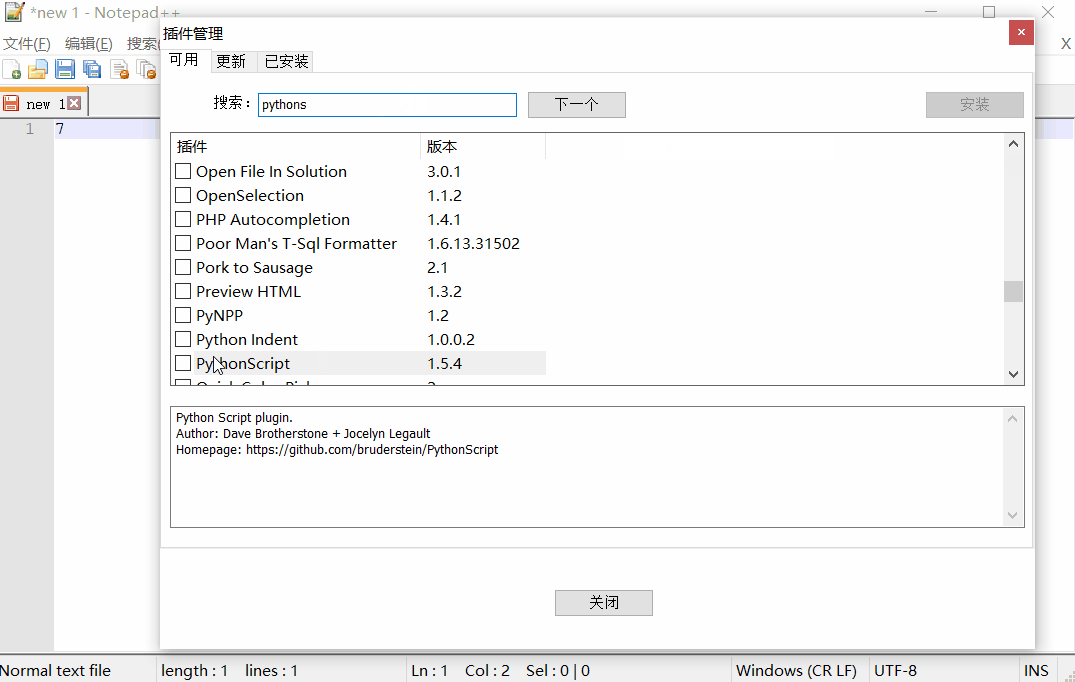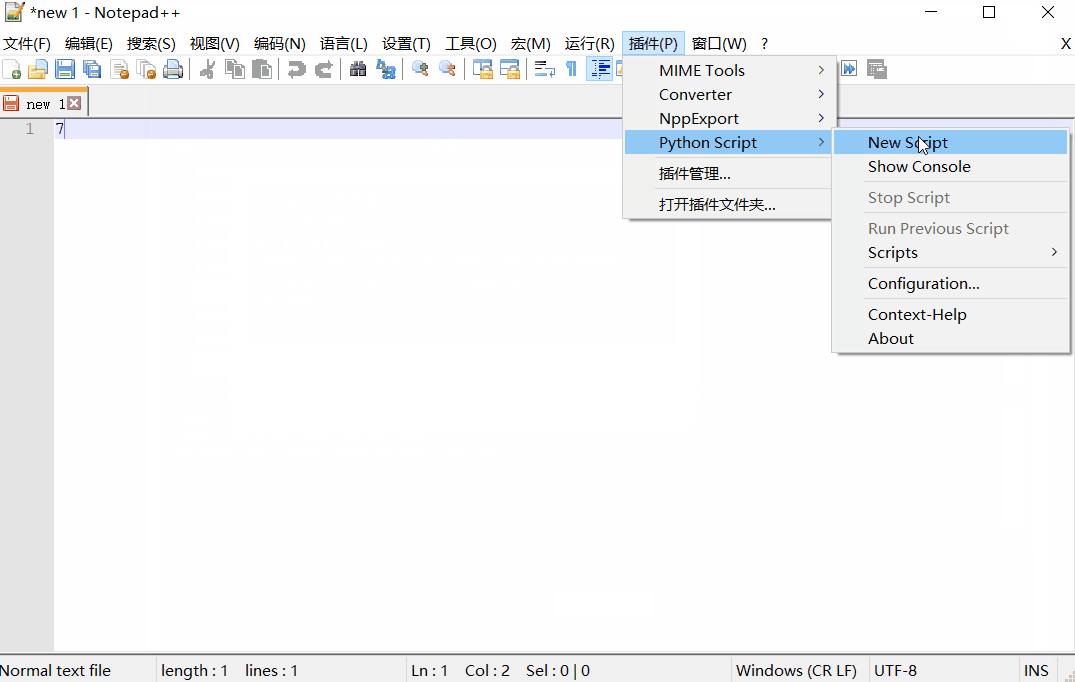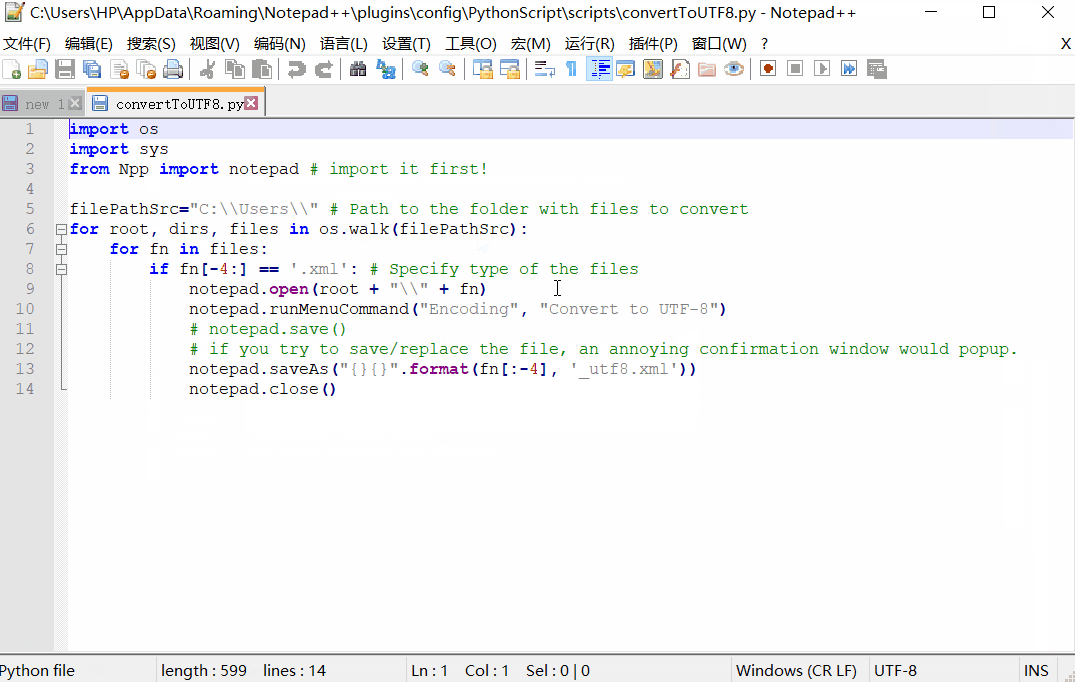
然后运行
使用记事本转换格式
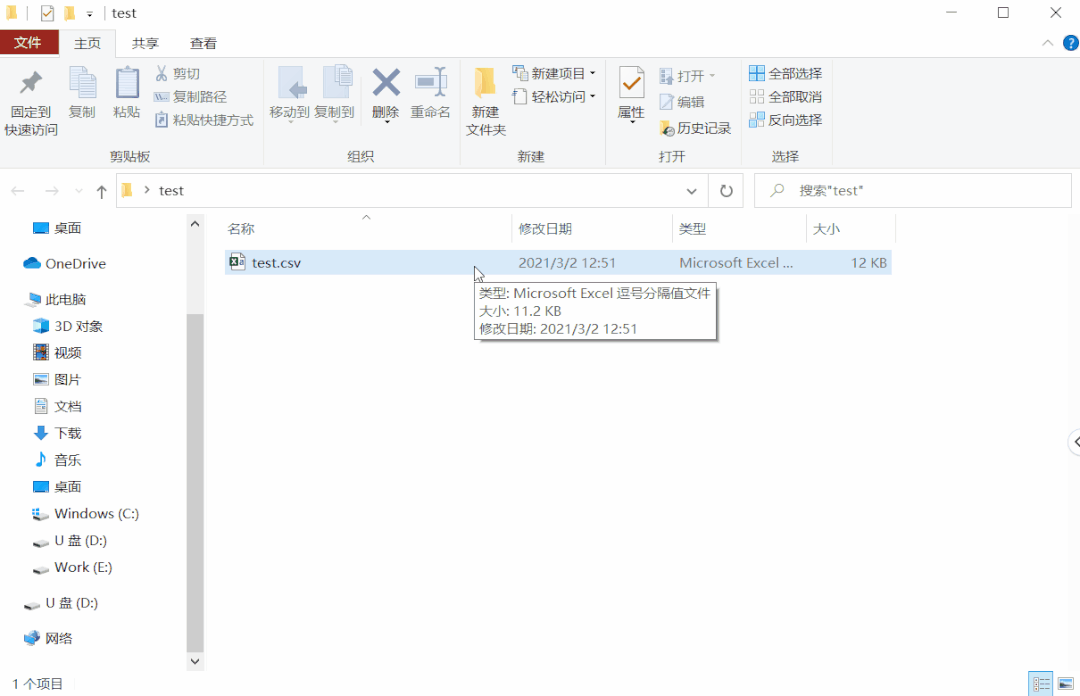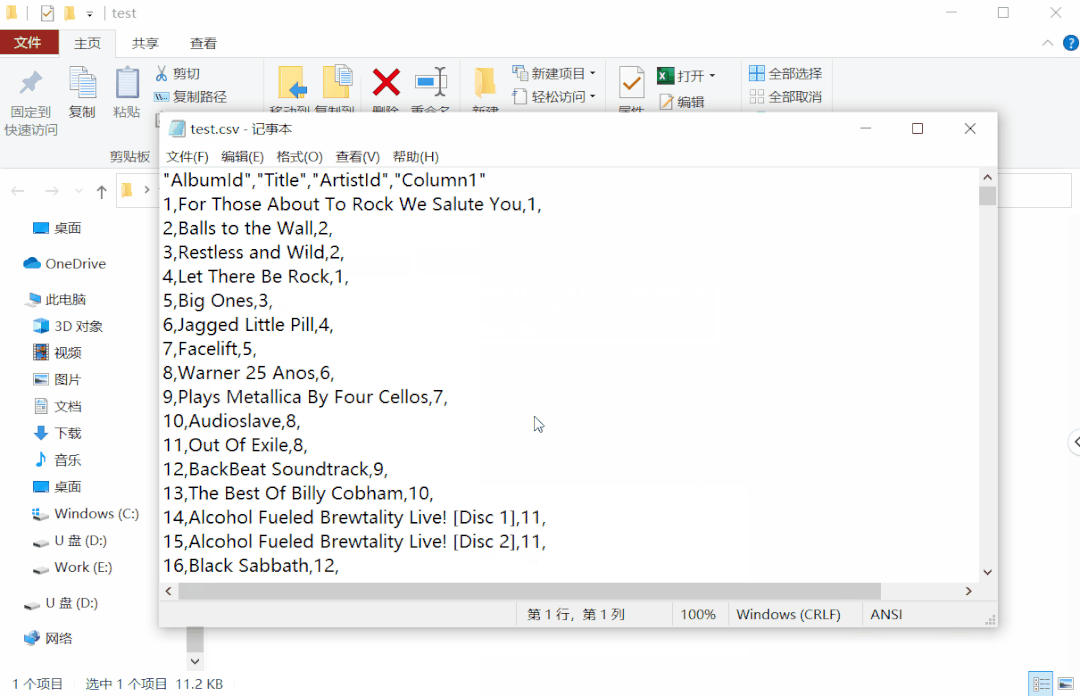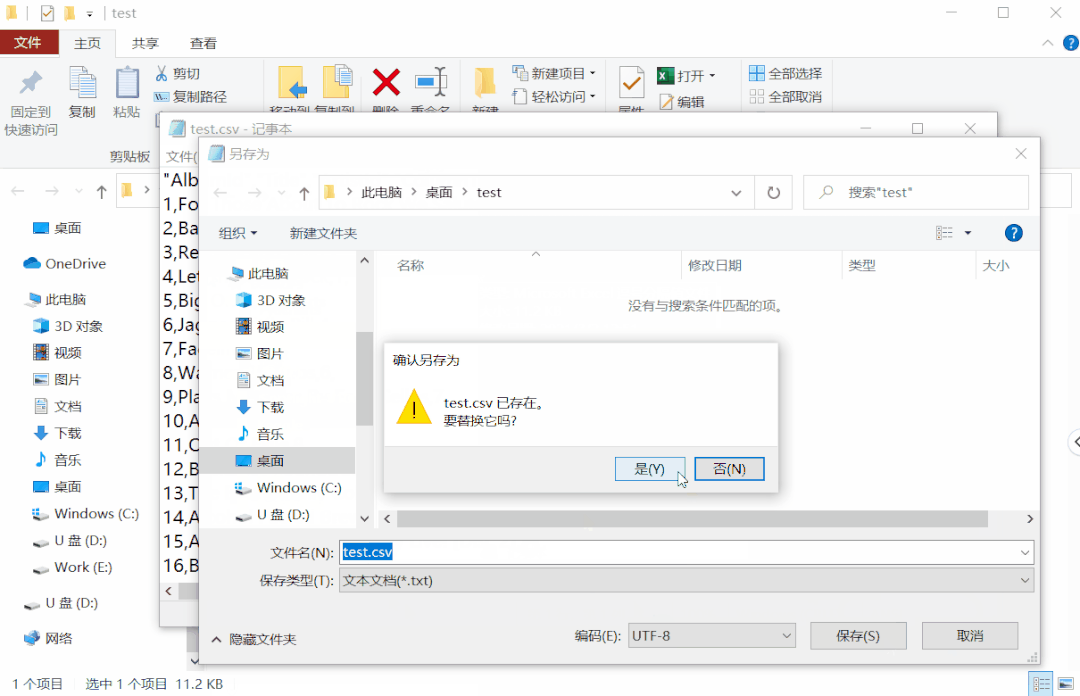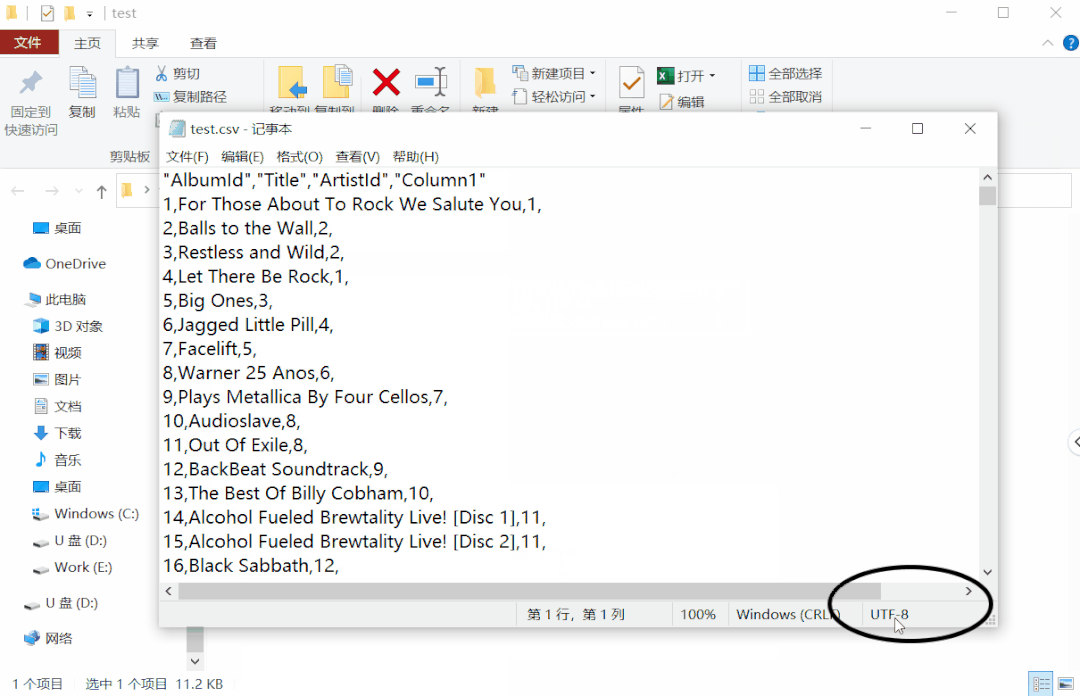
记事本是个强大的文本编辑软件,在少量文件或未知原始文件编码的情况下,使用记事本转换编码很是方便。
选中需要转换的原始文件,右击打开方式为记事本
文件 -> 另存为 -> 选择编码方式"utf-8" -> 保存
再次打开检查文件编码
各中文编码
各语言标准编码[6]
以下仅展示来中文编码,其他标准编码请见参考资料。
| Codec编码器 | Aliases别名 | 语言能力 |
|---|---|---|
| ascii | 646, us-ascii | 英语 |
| big5 | big5-tw, csbig5 | 繁体中文 |
| big5hkscs | big5-hkscs, hkscs | 繁体中文 |
| cp037 | IBM037, IBM039 | 英语 |
| cp437 | 437, IBM437 | 英语 |
| cp950 | 950, ms950 | 繁体中文 |
| gb2312 | chinese, csiso58gb231280, euc-cn, euccn, eucgb2312-cn, gb2312-1980, gb2312-80, iso-ir-58 | 简体中文 |
| gbk | 936, cp936, ms936 | 统一中文 |
| gb18030 | gb18030-2000 | 统一中文 |
| hz | hzgb, hz-gb, hz-gb-2312 | 简体中文 |
| iso2022_jp_2 | iso2022jp-2, iso-2022-jp-2 | 日文,韩文,简体中文,西欧,希腊文 |
| latin_1 | iso-8859-1, iso8859-1, 8859, cp819, latin, latin1, L1 | 西欧 |
| iso8859_2 | iso-8859-2, latin2, L2 | 中欧和东欧 |
| iso8859_3 | iso-8859-3, latin3, L3 | 世界语,马耳他语 |
| iso8859_4 | iso-8859-4, latin4, L4 | 波罗的海语言 |
| utf_32 | U32, utf32 | 所有语言 |
| utf_32_be | UTF-32BE | 所有语言 |
| utf_32_le | UTF-32LE | 所有语言 |
| utf_16 | U16, utf16 | 所有语言 |
| utf_16_be | UTF-16BE | 所有语言 |
| utf_16_le | UTF-16LE | 所有语言 |
| utf_7 | U7, unicode-1-1-utf-7 | 所有语言 |
| utf_8 | U8, UTF, utf8, cp65001 | 所有语言 |
| utf_8_sig | 所有语言 |
参考资料
[1]
codecs模块: https://docs.python.org/2/library/codecs.html
[2]
python中转换文件: https://stackoverflow.com/questions/191359/how-to-convert-a-file-to-utf-8-in-python
[3]
巧用notepad++: https://stackoverflow.com/questions/7256049/how-do-i-convert-an-ansi-encoded-file-to-utf-8-with-notepad
[4]
notepad++中使用python脚本: https://blog.csdn.net/tomato__/article/details/46915869
[5]
NotePad++下载地址: https://notepad-plus-plus.org/downloads/
各语言标准编码: https://docs.python.org/3/library/codecs.html#standard-encodings
---------End---------

后台回复「微信群」,将邀请加入读者交流群。

《Python知识手册》| 《Markdown速查表》|《Python时间使用指南》|《Python字符串速查表》|《SQL经典50题》|《Python可视化指南》|《Plotly可视化指南》|《Pandas使用指南》|《机器学习精选》

????分享、点赞、在看,给个三连击呗!????















 9050
9050











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









