







堆的定义
是n个元素的序列H={k1, k2 , … kn} ,满足:

由堆的定义知,堆是一棵以k1为根的完全二叉树。若对该二叉树的结点进行编号(从上到下,从左到右),得到的序列就是将二叉树的结点以
顺序结构存放,堆的结构正好和该序列结构完全一致。
堆的性质
① 堆是一棵采用顺序存储结构的完全二叉树, k1是根结点;
② 堆的根结点是关键字序列中的最小(或最大)值,分别称为小(或大)根堆;
③ 从根结点到每一叶子结点路径上的元素组成的序列都是按元素值(或关键字值)非递减(或非递增)的;
④堆中的任一子树也是堆。
利用堆顶记录的关键字值最小(或最大)的性质,从当前待排序的记录中依次选取关键字最小(或最大)的记录,就可以实现对数据记录的排序,这种排序方法称为
堆排序。
堆排序思想
① 对一组待排序的记录,按堆的定义建立堆;
② 将
堆顶记录和最后一个记录交换位置,则前n-1个记录是无序的,而最后一个记录是有序的;
③ 堆顶记录被交换后,前n-1个记录不再是堆,需将前n-1个待排序记录重新组织成为一个堆,然后将堆顶记录和倒数第二个记录交换位置,即将整个序列中次小关键字值的记录调整(排除)出无序区;
④ 重复上述步骤,直到全部记录排好序为止。
结论:排序过程中,若采用
小根堆,排序后得到的是
非递减序列;若采用
大根堆,排序后得到的是
非递增序列。
堆的调整——筛选
堆的调整思想
输出堆顶元素之后,以堆中最后一个元素替代之;然后将根结点值与左、右子树的根结点值进行比较,并
与其中小者
进行交换;重复上述操作,直到是叶子结点或其关键字值小于等于左、右子树的关键字的值,将得到新的堆。称这个从堆顶至叶子的调整过程为“筛选”,如图1所示。
注意:筛选过程中,根结点的左、右子树都是堆,因此,筛选是从根结点到某个叶子结点的一次调整过程。
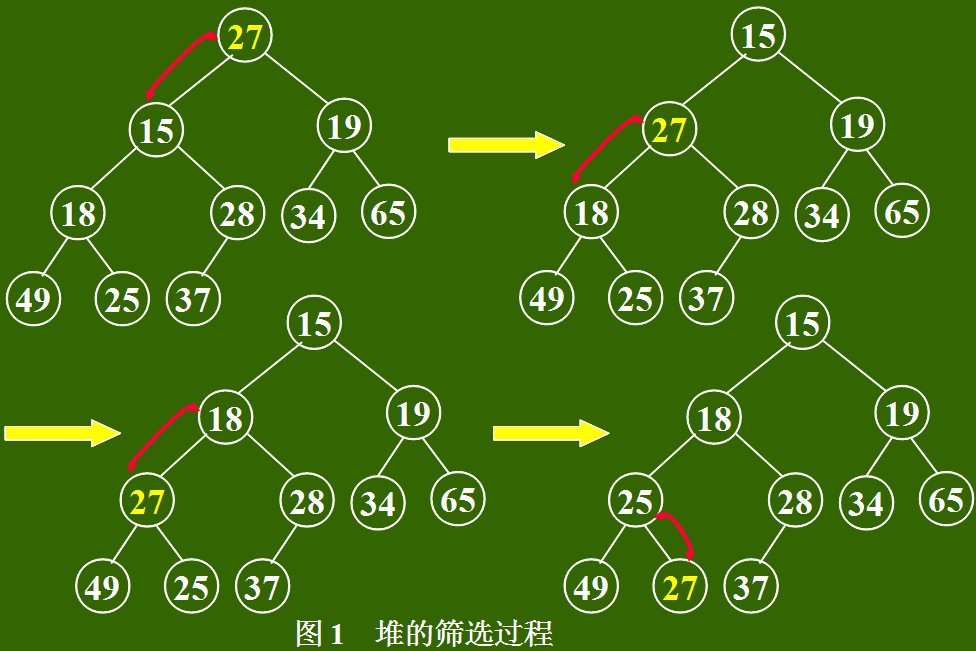
堆调整算法实现
/* H->R[s…m]中记录关键字除H->R[s].key均满足堆定义 */
/* 调整H->R[s]的位置使之成为小根堆 */
void Heap_adjust(Sqlist *H, int s, int m)
{
int j=s, k=2*j ; /* 计算H->R[j]的左孩子的位置 */
H->R[0]=H->R[j] ; /* 临时保存H->R[j] */
for (k=2*j; k<=m; k=2*k)
{
if((k<m)&&(LT(H->R[k+1].key, H->R[k].key))
k++ ; /* 选择左、右孩子中关键字的最小者 */
if( LT(H->R[k].key, H->R[0].key))
{
H->R[j]=H->R[k];
j=k;
k=2*j;
}
else
break;
}
H->R[j]=H->R[0];
}堆的建立
利用筛选算法,可以将任意无序的记录序列建成一个堆,设R[1],R[2], …,R[n]是待排序的记录序列。
将二叉树的每棵子树都筛选成为堆。只有根结点的树是堆。第⌊n/2⌋个结点之后的所有结点都没有子树,即以第⌊n/2⌋个结点之后的结点为根的子树都是堆。因此,以这些结点为左、右孩子的结点,其左、右子树都是堆,则进行一次筛选就可以成为堆。同理,只要将这些结点的直接父结点进行一次筛选就可以成为堆…。
只需从第⌊n/2⌋个记录到第1个记录依次进行筛选就可以建立堆。
可用下列语句实现:
for(j=n/2; j>=1; j--)
Heap_adjust(R, j, n);
堆排序算法实现
堆的根结点是关键字最小的记录,输出根结点后,是以序列的最后一个记录作为根结点,而原来堆的左、右子树都是堆,则进行一次筛选就可以成为堆。
void Heap_Sort(Sqlist *H)
{
int j;
for(j=H->length/2; j>0; j--)
Heap_adjust(H, j, H->length); /* 初始建堆 */
for(j=H->length; j>=1; j--)
{
H->R[0]=H->R[1];
H->R[1]=H->R[j];
H->R[j]=H->R[0]; /* 堆顶与最后一个交换 */
Heap_adjust(H, 1, j-1) ;
}
}
算法分析
主要过程:初始建堆和重新调整成堆。设记录数为n,所对应的完全二叉树深度为h 。
◆ 初始建堆:每个非叶子结点都要从上到下做“筛选”。第i层结点数≤2i-1,结点下移的最大深度是h-i,而每下移一层要比较2次,则比较次数C1(n)为:
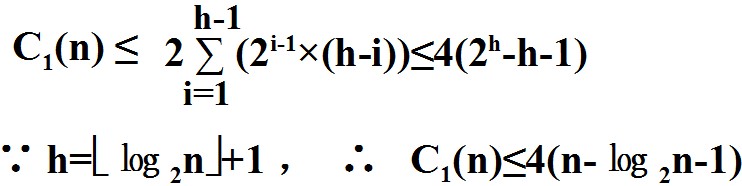
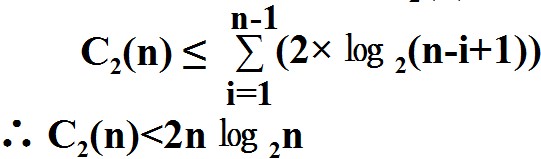
◆ 筛选调整:每次筛选要将根结点“下沉”到一个合适位置。第i次筛选时:堆中元素个数为n-i+1;堆的深度是ë㏒2(n-i+1)û+1,则进行n-1次“筛选”的比较次数C2(n)为:
∴堆排序的比较次数的数量级为:
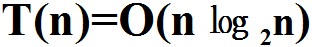 ;
;
而附加空间就是交换时所用的临时空间,故空间复杂度为:S(n)=O(1) 。















 23万+
23万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









