






 本文深入探讨Mysql中B+树索引的工作原理,包括聚簇与非聚簇索引的区别,以及如何正确创建和使用索引。文章分析了索引的优缺点,如空间消耗和写操作的影响,指出在数据量适中且更新频繁的场景下应谨慎使用。此外,还讲解了复合索引的最左匹配原则和避免回表的方法。
本文深入探讨Mysql中B+树索引的工作原理,包括聚簇与非聚簇索引的区别,以及如何正确创建和使用索引。文章分析了索引的优缺点,如空间消耗和写操作的影响,指出在数据量适中且更新频繁的场景下应谨慎使用。此外,还讲解了复合索引的最左匹配原则和避免回表的方法。
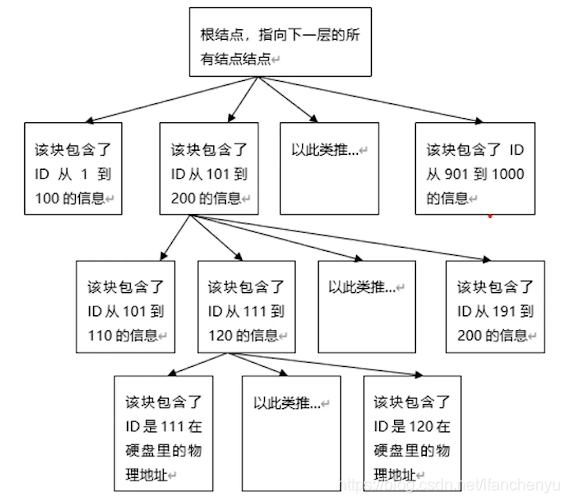
(Mysql)索引数据结构:B+树
Mysql使用B+树作为索引的原因:https://www.cnblogs.com/tiancai/p/9024351.html
红黑树: https://www.jianshu.com/p/e136ec79235c
https://www.jianshu.com/p/84416644c080
聚簇索引叶节点是数据,非聚簇索引叶节点是数据的地址,一个表职能有一个聚簇索引。
索引需要耗费空间,所以不是多多益善。
权衡因素:
1.建索引要空间,更改数据要重建索引
2.表里数据量不大,可以不建索引
3.数据量大,但是该字段需要大批量更新,慎重建索引,或者操作前关索引
4.数量大,该字段重复性不高,且频繁读,可建索引
索引的正确和错误用法:
select name, age, score from student where name = 'Tom',
where score > 80,用到索引,但是无法提升性能。首先通过索引找80数据,但是找>80的还是全表扫描。
where score + 20 = 100,有左值操作,无法走索引
where name like 'T%' 走索引(只要不在最前面,都走索引)
where name like '%T' 不走索引
复合索引:
最左匹配原则,比如有(a, b, c)这个复合索引,相当于建立了a, (a,b),(a,b,c)这三个索引。所以次序很重要。
select name. age, score from student where name = 'Tom'
在name上建立了索引,上述语句会回表,即从索引表里找到rowid,并到主表根据rowid找到其他字段(age,score没有索引),回表可能影响性能。
复合索引能避免回表,但是也要权衡。
总结:
1.索引结构是b+树,结合图说明聚簇索引和非聚簇索引
2.建立索引需要权衡的因素(利弊)(占空间,写操作重建索引)
3.哪些场景不能建立索引(数据少)
4.哪怕建立了索引,但是也要正确使用(左值操作)
5.复合索引的最左匹配和回表
6.通过查看sql的执行计划(后续有详细说明),能分析是否走索引,从而引出通过执行计划优化Sql的话题。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









