






丰色 发自 凹非寺 量子位 | 公众号 QbitAI
一句话生成3D模型,英伟达也来“秀肌肉”了~
来看它最新捣鼓出的Magic3D AI,效果是这样儿的。
输入“坐在睡莲上的蓝色箭毒蛙”,就能得到这样一个细节丰富的3D模型:

“摆满了水果的银盘”也难不倒它:

还有诸如“鸟瞰角度的城堡”、“用寿司做的汽车”、“装着蛋的鸟巢”、“用垃圾袋做的裙子”……

精准程度可见一斑。
除了这个主要本领,它还可以通过编辑文本完成模型的修改:

或者在输入中携带一些图片,最终成果就可以保留图中的风格或者主要“人物”。

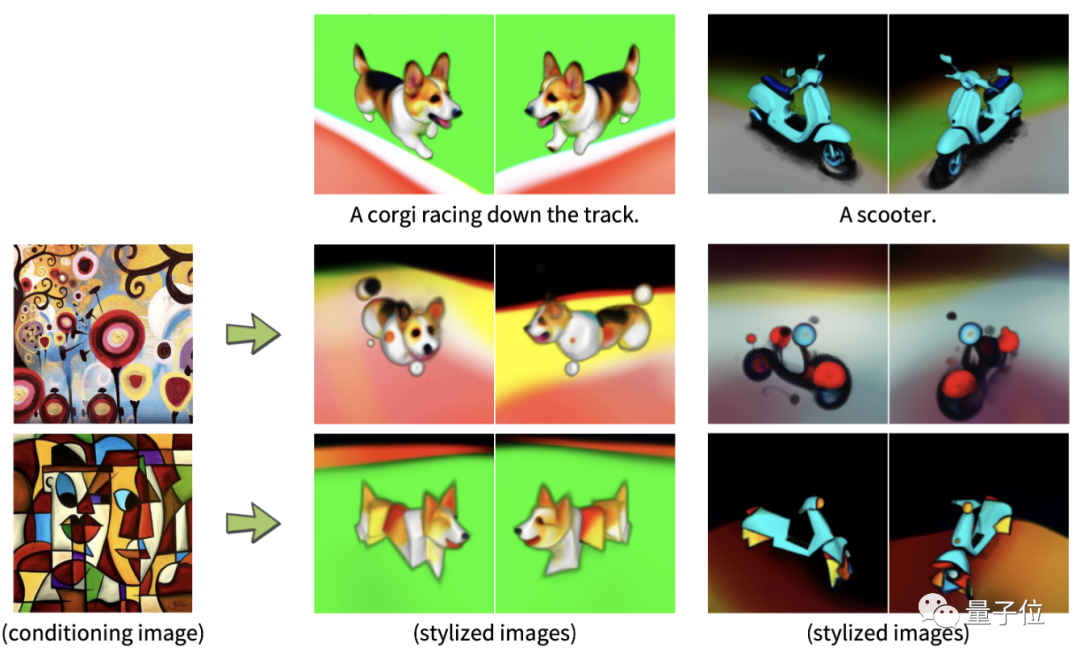
不知道这把有没有打到你的心巴上?
反正建模师看了都要喊失业了……

如何做到?
据介绍,Magic3D快速、高质量地得到结果所采用的策略是“从粗到细”,一共经过两阶段:
低分辨率优化和高分辨率优化。
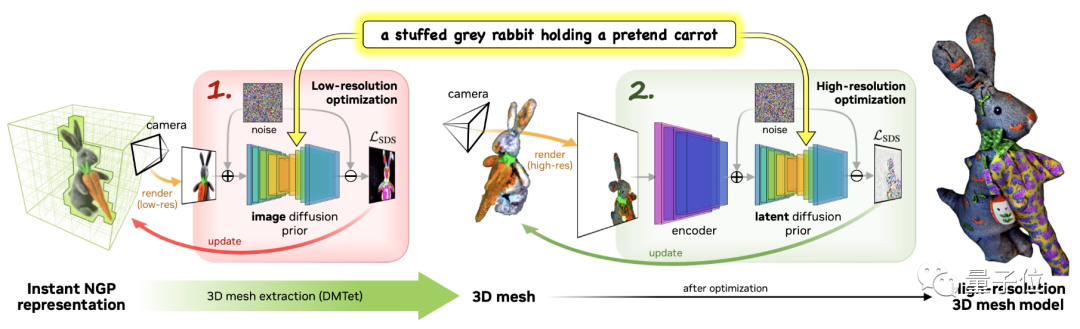
它使用eDiff-l作为模型的低分辨率文本到图像扩散先验(diffusion prior)。
首先,第一阶段,采用英伟达今年推出的3D重建模型Instant NGP,并对其优化,生成初始3D模型。
具体来说,就是通过重复采样和渲染低分辨率图像,计算出SDS损失,让Instant NGP给出结果。
注:SDS全称得分蒸馏采样(Score Distillation Sampling),是谷歌提出的一种新的采样方法,它无需对扩散模型进行反向传播更新。
这步完成后,就使用DMTet提取出初始3D mesh,作为第二阶段的输入。
第二阶段采用高分辨率文本到图像潜(latent)扩散先验。
还是使用同样的方法,对高分辨率图像进行采样和渲染,并使用相同的步骤进行更新,得到最终结果。
唯一的不同,就是本阶段的操作都是在第一阶段得出的初始“糙”模型上进行的。
比DreamFusion分辨率高8倍,速度快2倍
关注这一领域的朋友知道,一句话生成3D模型的AI中,目前最受关注的当属谷歌今年9月刚发布的DreamFusion。

它通过一个预先训练的二维文本到图像扩散模型来完成最终的文本到三维合成,效果惊艳。
那么,英伟达刚推出的这个Magic3D,与之相比如何?
经实验对比发现,后来者显然更胜一筹,主要表现在分辨率和速度上:
Magic3D的分辨率比DreamFusion高8倍,速度快2倍——只需在40分钟之内即可完成一次渲染。
而在具体效果上,Magic3D的生成结果也更细节一些,比如下面的“仙人掌”、“房子”和“草莓”等(左为Magic3D,右为DreamFusion)。


不过,遗憾的是,Magic3D还并未像DreamFusion一样已开源。
关于作者
一共有10位。

前5位都具有同等贡献,包括:
现英伟达研究科学家、博士毕业于CMU机器人专业的Lin Chen-Hsuan,他曾在Facebook人工智能研究部和Adobe实习;
正在多伦多大学读博士的Gao Jun,北大计算机本科毕业;
正在多伦多读博士的Zeng Xiaohui,香港科技大学毕业;
以及同样来自该大学的Towaki Takikawa;
最后是正在康奈尔大学读博士的唐路明,清华大学物理和数学专业本科毕业。
论文地址:
https://arxiv.org/abs/2211.10440
项目主页:
https://deepimagination.cc/Magic3D/
参考链接:
https://twitter.com/_akhaliq/status/1594505474774278147?s=46&t=Dc0f1ExmRsdk_PHz2JX-IA
猜您喜欢:
深入浅出stable diffusion:AI作画技术背后的潜在扩散模型论文解读

最新最全100篇汇总!生成扩散模型Diffusion Models
附下载 |《TensorFlow 2.0 深度学习算法实战》
《礼记·学记》有云:独学而无友,则孤陋而寡闻
欢迎加入 GAN/扩散模型 —交流微信群 !
扫描下面二维码,添加运营小妹好友,拉你进群。发送申请时,请备注,格式为:研究方向+地区+学校/公司+姓名。如 扩散模型+北京+北航+吴彦祖

请备注格式:研究方向+地区+学校/公司+姓名

点击 一顿午饭外卖,成为CV视觉的前沿弄潮儿!,领取优惠券,加入 AI生成创作与计算机视觉 知识星球!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









