






本文编辑来源 paperweekly
文生图在最近一年取得了显著的进步,DreamBooth 定制化生成工作,进一步证明了文生图的潜力,并且广泛引起了社区关注,相比于单概念生成,在一张图内定制多个概念是更加有趣且具有广泛应用场景(AI 影楼,AI 漫画生成....)。
相比于单概念定制生成取得的成功,阿里提出的 Cones 和 Adobe 提出的 Custom Diffusion 作为现有的多定制概念生成方法仍存在两个挑战:
首先,他们需要为每一种多个概念的组合都学习单独的模型,这可能会受到以下影响:1)无法利用已有的模型,比如一个新的需要定制的多概念组包含三种概念 {A,B,C},无法从已有的 {A,B} 的定制模型中获得知识,只能重新训练。2)当需要定制的概念数量增加时,计算资源的消耗指数上升。
不同的定制概念可能会互相干扰,导致最终生成时有些概念无法显示,或者概念间的属性存在混淆。当概念之间的语义相似度较高时,这种现象尤其明显(例如,同时定制一只猫和一只狗,可能生成的图片中,定制的猫混淆了狗的某些特征。)
基于此,阿里巴巴和蚂蚁集团的研究团队提出了组合式的多概念定制生成方法:Cones 2,能同时定制更多物体,且生成图片质量显著提升。

论文主页:Cone 2
https://arxiv.org/abs/2305.19327
项目主页:Cones-page
https://cones-page.github.io
该团队的前作 Cones 获得了 ICML 2023 的 oral,并且在推特获得了广泛关注。

Cones 2 优势主要体现在 3 个方面。(1)使用简单而有效的方法来表示概念,可以任意组合,复用各种训练好单概念,从而进行多定制概念生成,而无需为多概念进行任何重新训练。(2)使用空间布局作为指导,这在实践中非常容易获得,用户只需要提供一个 bounding box,即可以控制每个概念的特定位置,并同时减轻概念之间的属性混淆。(3)在一些具有挑战性的场景下也能取得令人满意的性能:进行语义相似的多定制概念的生成,如定制两只狗,并且可以交换眼镜;在概念数量上,也可以合成六个概念。


方法
1. 基于扩散模型的文本引导图像生成
扩散模型学习从正态分布噪声中逐步去噪来恢复真实的视觉内容,该过程实际上是在模拟可逆的长度为 T=1000 的马尔可夫链。在文本到图像任务中,条件扩散模型 的训练目标可以简化为重建损失:
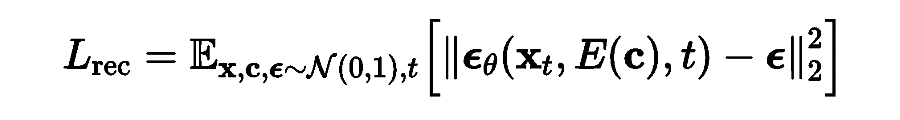
文本嵌入 通过交叉注意力机制注入到模型 中。在推理时,网络通过迭代去噪 进行采样。
2. 残差文本嵌入表示概念
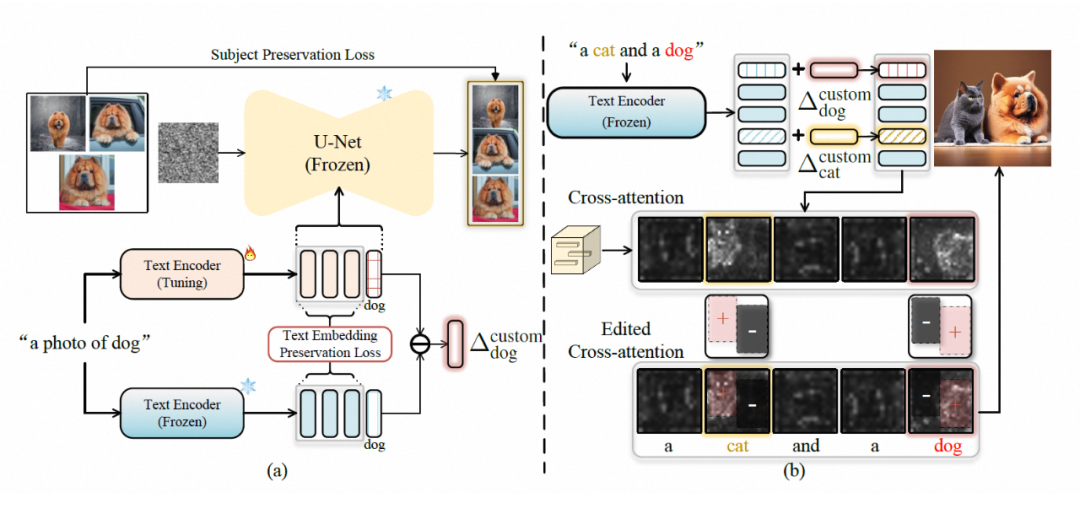
为了可以定制化生成用户需要的特定概念,模型首先需要“记住”这些概念的特征。由于改变预训练模型参数往往会导致模型的泛化性下降,Cones 2 选择针对每个特定概念学习一个合适的编辑方向。将这个方向作用于概念对应的基类的特征编码上,就可以得到定制化的结果,这个方向称为 residual token embedding。
举个例子,在使用 Stable Diffusion 生成图像“一只狗坐在海滩上”时,整个生成过程由文本经过文本编码模型得到的文本编码控制,那么只需要将“狗”对应的文本编码做合适的偏移,就可以让模型生成出定制化的“狗”。为了得到 residual token embedding,首先需要用给定的数据微调文本编码模型,在训练过程中 Cones 2 通过引入文本编码保持损失,限制微调后的文本编码器的输出和原始预训练的文本编码器的输出尽可能接近。
同样参考上面的例子,给定“一只狗坐在海滩上”作为输入,这两个文本编码器输出的文本编码,只在定制化概念对应的类别词(狗)这里差别较大,在其他词(海滩等。。。)的部分尽可能保持输出一致。结合原本的生成模型,微调后的文本编码器具有定制特定概念的能力,由于微调过程采用了文本编码保持损失的约束,这种能力可以通过计算微调过的文本编码器和原始文本编码器在类别词部分的平均差异,来得到需要的 residual token embedding:
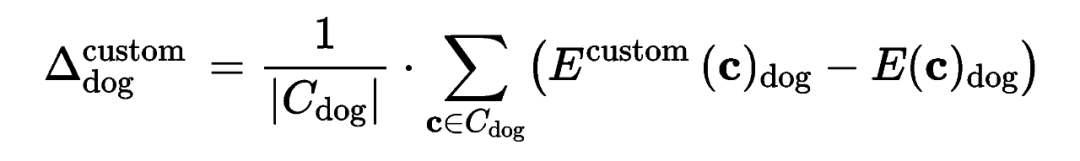
基于上述方法得到残差表示,是可以重复使用并且即插即用的。在做多概念定制化生成的时候,只需要将每个定制概念所对应类别词的文本编码加上对应的残差项即可。
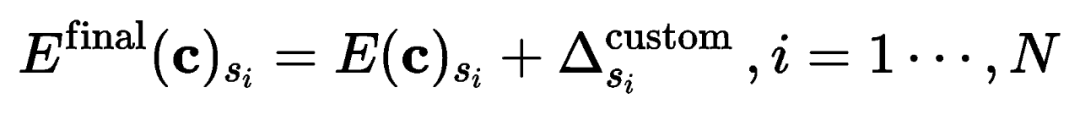
3. 通过空间布局引导多概念组合生成
交叉注意力层之间的注意力图如下 ,交叉注意力图直接影响最终生成的空间布局,多概念定制生成的图片中的一个问题是某些概念可能无法显示。为了避免这种情况,Cones 2 在希望其出现即用户通过 bounding box 指定的区域中增强目标概念的激活值。另一个问题是概念间的属性存在混淆,即生成图像中的概念可能包含其他概念的特征。
为了避免这种情况,则希望削弱每个对象出现在用户指定区域外的激活值。结合上述两种想法,Cones 2 提出了一种根据预定义布局 指导生成过程的方法。在实践中,将布局 定义为一组概念边界框,由每个概念的的指导布局 组成。在希望概念 出现的区域中将 的值设置为正值,并在与该概念无关区域中将 的值设置为负。对注意力图进行编辑。
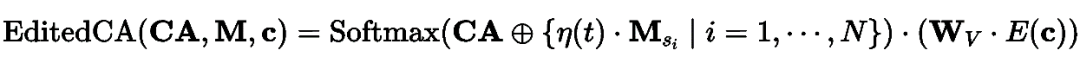

实验
将生成结果与现有方法进行对比,从训练的计算复杂度,以及生成效果,均有显著提升。



并且在处理更多概念的生成,以及处理语义相似物体的场景下,都有着优越表现。



应用前景
多定制概念生成除了能够生成更加高质量,内容丰富的图片外,同时具有广泛的应用前景,现在大火的 ControlNet 更多是控制生成图片中的结构,多概念定制生成可以对生成的内容进行控制,使文本到图像的生成更加可控,进一步提高了文生图模型的应用价值。比如,创作者通过输入文本,通过几个定制好的角色概念,进行多格漫画生成;通过组合用户定制的自身角色概念和商家提供的多个试戴试穿的定制概念(衣服,首饰,鞋帽等等),实现多款服装的试穿体验。
关注公众号【机器学习与AI生成创作】,更多精彩等你来读
卧剿,6万字!30个方向130篇!CVPR 2023 最全 AIGC 论文!一口气读完
深入浅出stable diffusion:AI作画技术背后的潜在扩散模型论文解读
深入浅出ControlNet,一种可控生成的AIGC绘画生成算法!

最新最全100篇汇总!生成扩散模型Diffusion Models
附下载 |《TensorFlow 2.0 深度学习算法实战》
《礼记·学记》有云:独学而无友,则孤陋而寡闻
点击一杯奶茶,成为AIGC+CV视觉的前沿弄潮儿!,加入 AI生成创作与计算机视觉 知识星球!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









