






大数据-Storm基础(写给初次接触Storm的小白们)
(本人的一点小理解,希望批评指正)
Storm是一种实时处理的系统框架,可以实时的得到输入的结果,其中还包含了相应的流计算的处理过程
想要学习Storm相关的知识的话,那一定是对Hadoop的基础知识有了一定的了解(啰嗦一下,至少知道MapReduce的模型是什么概念,具体的处理过程是什么样的,不需要有多深的理解,至少不会出现相应的误解)
PS:顺便说一下本人的hadoop知识也不能说十分的熟练,都是在学习吗!!
废话不多说了,我们先说说Storm我们用来都能干什么吧,其实说白了,最简单的一个应用的场景就是可以实时的给用户推送相应的内容,而这些内容都是实时采集的内容,就是可以实时的统计出用户提交的信息,并展示用户的信息。
- spout
- bolts
- Topology
Storm的实时处理任务被打包成Topology发布,同hadoop的MapReduce任务相似(Job)但是不同的是一旦提交的话就不会停止处理完,直到手动的终止这个topology才会停止。
spout:storm的消息源,为topology提供数据;
bolts:storm的消息处理者,为topology进行消息处理;
toplolgy:处理的任务实体;
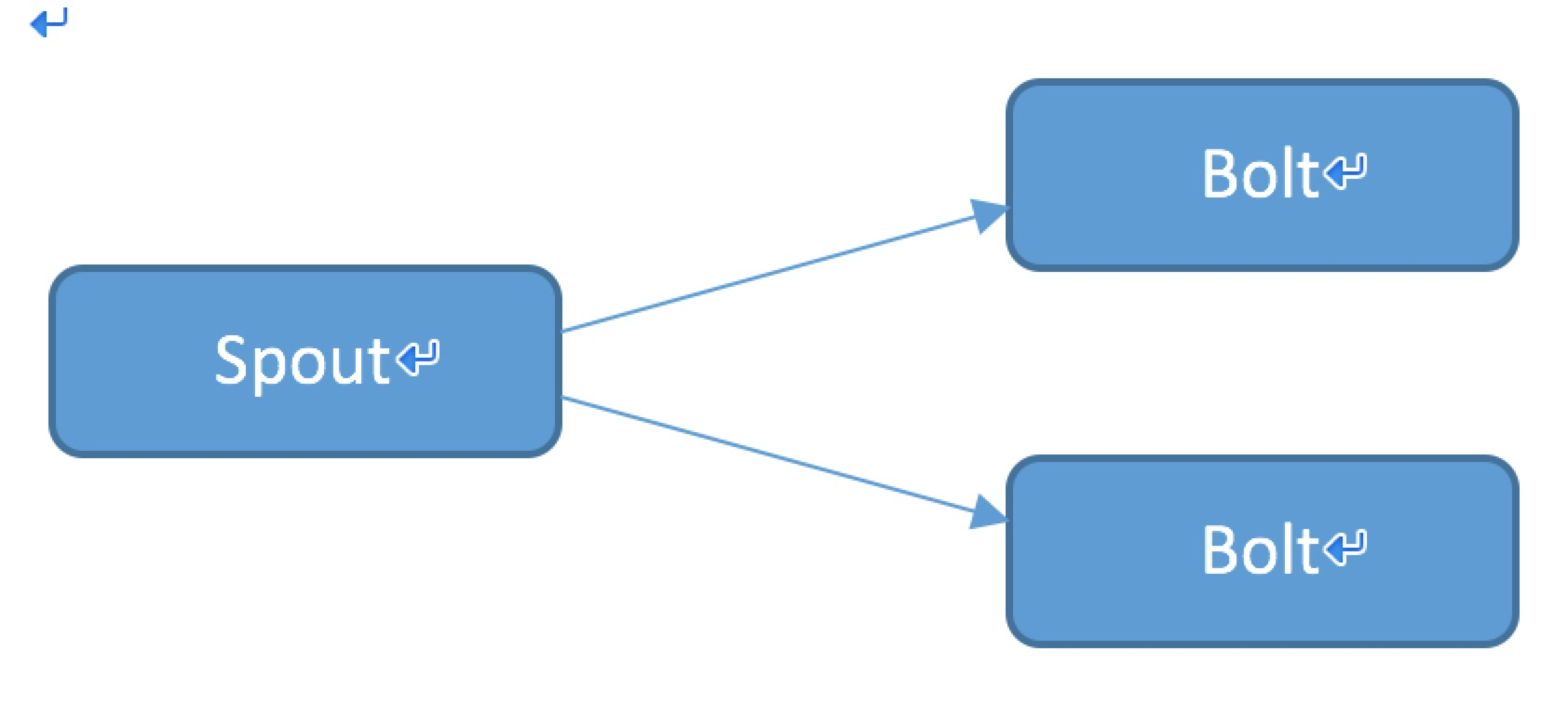
作为一个storm的门的小白,知道其组成都由什么构成对于后续的处理过程的理解是有好处的,那么接下来我们就从代码的角度理解Storm,我深知学习和了解一门新知识没有什么比代码更具有说服力的啦!!
实现一个简单的Storm(本地运行)的代码:
代码由四部分构成:
bolts,count,main和spout,只要完成一个实时的单词计数程序!
spouts文件的内容:
最主要的是nextTuple函数,open函数,和declareOutputFields函数,
在nextTuple函数中,向bolts中分发相应的文本行,nextTuple会在ack和fail中被周期性的调用;核心的是emit函数的提交,提交的是键值对,作为元祖发送出去;
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector)。它接收如下参数:配置对象,在定义topology对象是创建;TopologyContext对象,包含所有拓扑数据;还有SpoutOutputCollector对象,它能让我们发布交给bolts处理的数据
import backtype.storm.spout.SpoutOutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.IRichSpout;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.tuple.Values;
import java.io.BufferedReader;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.InterruptedIOException;
import java.util.Map;
/**
* spouts定义了输入的数据类型和处理过程,实现WordReader类实现了IRichSpout接口,负责从文件按行读取文件
* 并把文本行给bolts
*/
public class spouts implements IRichSpout{
private SpoutOutputCollector spoutOutputCollector;
private FileReader fileReader;
private boolean complateBoolean = false;
private TopologyContext topologyContext;
public void ack(Object msgID){
System.out.println("OK:"+msgID);
}
public void close(){}
public void fail(Object msgID){
System.out.println("FAIL:"+msgID);
}
/**
* 实现的过程作的唯一的过程,分发文件中的文本行,向bolts发送待处理的数据,逐行读取数据并进行处理
* nextTuple会在ack()和fall()的函数内被周期性的调用,没有任务的时候释放对该线程的控制,其他的方法采用机会被执行
* 因此程序的第一行执行的是检查其是否已经被处理完成,如果处理完成就降低处理器的负载,会在返回之前休眠1s,如果任务完成了,文件中的每一行都会被分发出来了
*
*/
public void nextTuple(){
/**
*一直调用的程序,直到整个程序执行完
*/
if(complateBoolean){
try{
Thread.sleep(1000);
}catch (Exception e){
throw new RuntimeException("Error! Time out!");
}
return;
}
String string;
BufferedReader bufferedReader = new BufferedReader(fileReader);
try{
while((string = bufferedReader.readLine())!= null){
this.spoutOutputCollector.emit(new Values(string),string);
}
}catch (Exception e){
throw new RuntimeException("Error reading tuple",e);
}finally {
complateBoolean = true;
}
}
/**
* 我们将创建一个文件,并维持collector对象
* open方法将会被第一个调用
* 接受的参数如下:
* conf:配置对象,在定义topology对象创建
* context:包含所有的拓扑数据
* spoutOutputCollector:发布交给bolts处理的数据
*/
public void open(Map conf,TopologyContext context,SpoutOutputCollector spoutOutputCollector){
try{
this.topologyContext = context;
this.fileReader = new FileReader(conf.get("wordsFile").toString());//用来读取文件
}catch(FileNotFoundException e){
throw new RuntimeException("Error reading file ["+conf.get("wordFile")+"]");
}
this.spoutOutputCollector= spoutOutputCollector;
}
@Override
public boolean isDistributed() {
return false;
}
@Override
public void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) {
}
}
bolts文件的内容:
declareOutputFields函数,定义一个域,声明bolt的输出模式;execute处理输入的单个元祖;
perpare在bolt开始处理元祖之前调用;
cleanup关闭时调用;
import backtype.storm.task.OutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.IRichBolt;
import backtype.storm.topology.IRichSpout;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Tuple;
import backtype.storm.tuple.Values;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
/**
* spouts读取数据,按行读取数据,每行发布一个元祖,还要创建bolts过程;
* bolts实现了接口IRichBolt接口
* bolts执行execute(Tuple input),每一次接收元祖都会调用一次,当执行nextTuple或execute方法时
*
* 整个bolt执行的是WordNormallzer:负责得到并标准化每行文本,把文件切分成单词,大写转成小写,去掉头尾的空白符
*/
public class bolts implements IRichBolt{
private OutputCollector outputCollector;
/**
* bolt发布一个名为"word"的域
* @param declarer
*/
public void declareOutputFields(OutputFieldsDeclarer declarer){
declarer.declare(new Fields("word"));
}
/**
* 处理传入的元祖
* @param input
*/
@Override
public void execute(Tuple input){
String sentence=input.getString(0);
String[] words=sentence.split(" ");
for(String word:words){
word.trim();
if(!word.isEmpty()){
word=word.toLowerCase();
List a=new ArrayList();
a.add(input);
//发布这个单词
outputCollector.emit(a,new Values(word));
}
}
outputCollector.ack(input);
}
@Override
public void cleanup() {
}
@Override
public void prepare(Map conf, TopologyContext context,OutputCollector outputCollector){
this.outputCollector = outputCollector;
}
}count文件:
import backtype.storm.task.OutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.IRichBolt;
import backtype.storm.topology.IRichSpout;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.tuple.Tuple;
import java.util.HashMap;
import java.util.Map;
/**
* 负责计数的bolts,结果显示
*/
public class count implements IRichBolt{
Integer id;
String name;
Map<String,Integer> counter;
private OutputCollector outputCollector;
@Override
public void cleanup(){
System.out.println("--单词数量:"+name+"-"+id+"--");
for(Map.Entry<String,Integer> entry:counter.entrySet()){
System.out.println(entry.getKey()+": "+entry.getValue());
}
}
/**
* 单词计数
*/
@Override
public void execute(Tuple tuple){
String string=tuple.getString(0);
if(!counter.containsKey(string)){
counter.put(string,1);
}else{
Integer c=counter.get(string)+1;
counter.put(string,c);
}
outputCollector.ack(tuple);
}
@Override
public void prepare(Map conf, TopologyContext context,OutputCollector outputCollector){
this.counter=new HashMap<String, Integer>();
this.outputCollector=outputCollector;
this.name=context.getThisComponentId();
this.id=context.getThisTaskId();
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer){}
}Main文件:
public class Main {
public static void main(String[] args) throws Exception{
TopologyBuilder topologyBuilder=new TopologyBuilder();
topologyBuilder.setSpout("word-reader",new spouts());
topologyBuilder.setBolt("word-normal",new bolts()).shuffleGrouping("word-reader");
topologyBuilder.setBolt("word-count",new count(),2).fieldsGrouping("word-normal",new Fields("word"));
Config config=new Config();
String path="../src/main/resources/words.txt";
config.put("wordFile",path);
config.setDebug(true);
//config.setNumWorkers(2);
config.put(Config.TOPOLOGY_MAX_SPOUT_PENDING,1);
LocalCluster localCluster=new LocalCluster();
//localCluster.shutdown();
localCluster.submitTopology("Get-start-topology",config,topologyBuilder.createTopology());//提示有错误
Thread.sleep(1000);
localCluster.killTopology("Get-start-topology");
localCluster.shutdown();
}
}














 964
964

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









