






思路分析:
(1)选定起始人(即选择关注数和粉丝数较多的人--大V)
(2)获取该大V的个人信息
(3)获取关注列表用户信息
(4)获取粉丝列表用户信息
(5)重复(2)(3)(4)步实现全知乎用户爬取
实战演练:
(1)、创建项目:scrapy startproject zhijutest
(2)、创建爬虫:cd zhihutest -----scrapy genspider zhihu www.zhihu.com
(3)、选取起始人(这里我选择了以下用户)
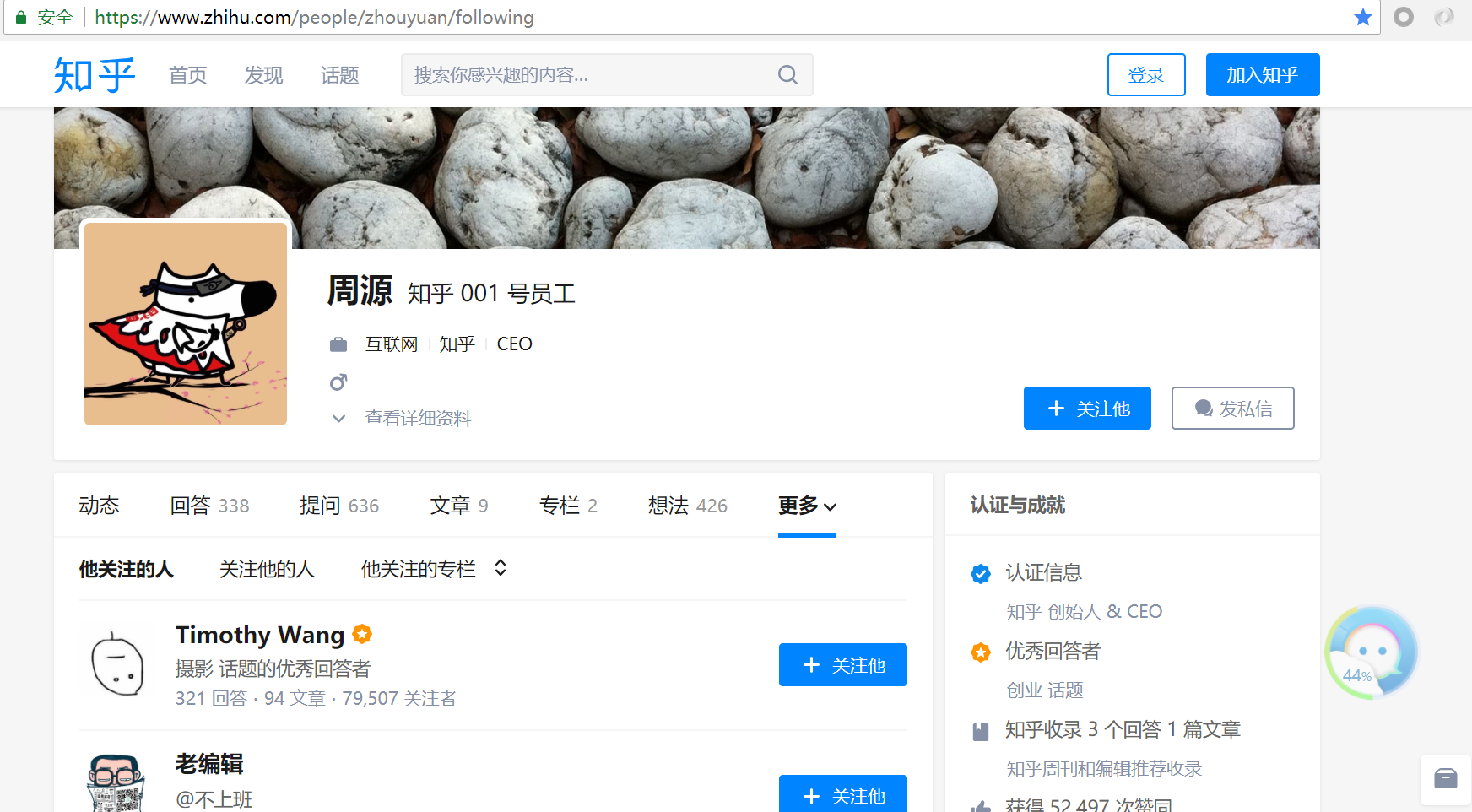
我们可以看到他关注的人和关注他的人,这些内容是我们(3)(4)步需要获取的
(3)、更改settings.py

代码分析:这里我们设置了不遵守robots协议
robots协议:网络爬虫协议,它用来告诉用户那些内容可以爬取,那些内容禁止爬取,一般我们运行爬虫项目,首先会访问网站的robots.txt页面,它告诉爬虫那些是你可以获取的内容,这里我们为了方便,即不遵守robots协议。

代码分析:这里我们设置了User-Agent和authorization字段(这是知乎对请求头的限制了,即反爬),而这里我们通过设置模拟了在没有登陆的前提下伪装成浏览器去请求知乎
(4)、页面初步分析
右击鼠标打开chrome开发者工具选项,并选中如下箭头所指,将鼠标放在黄色标记上,我们可以发现右侧加载出了一个ajax请求
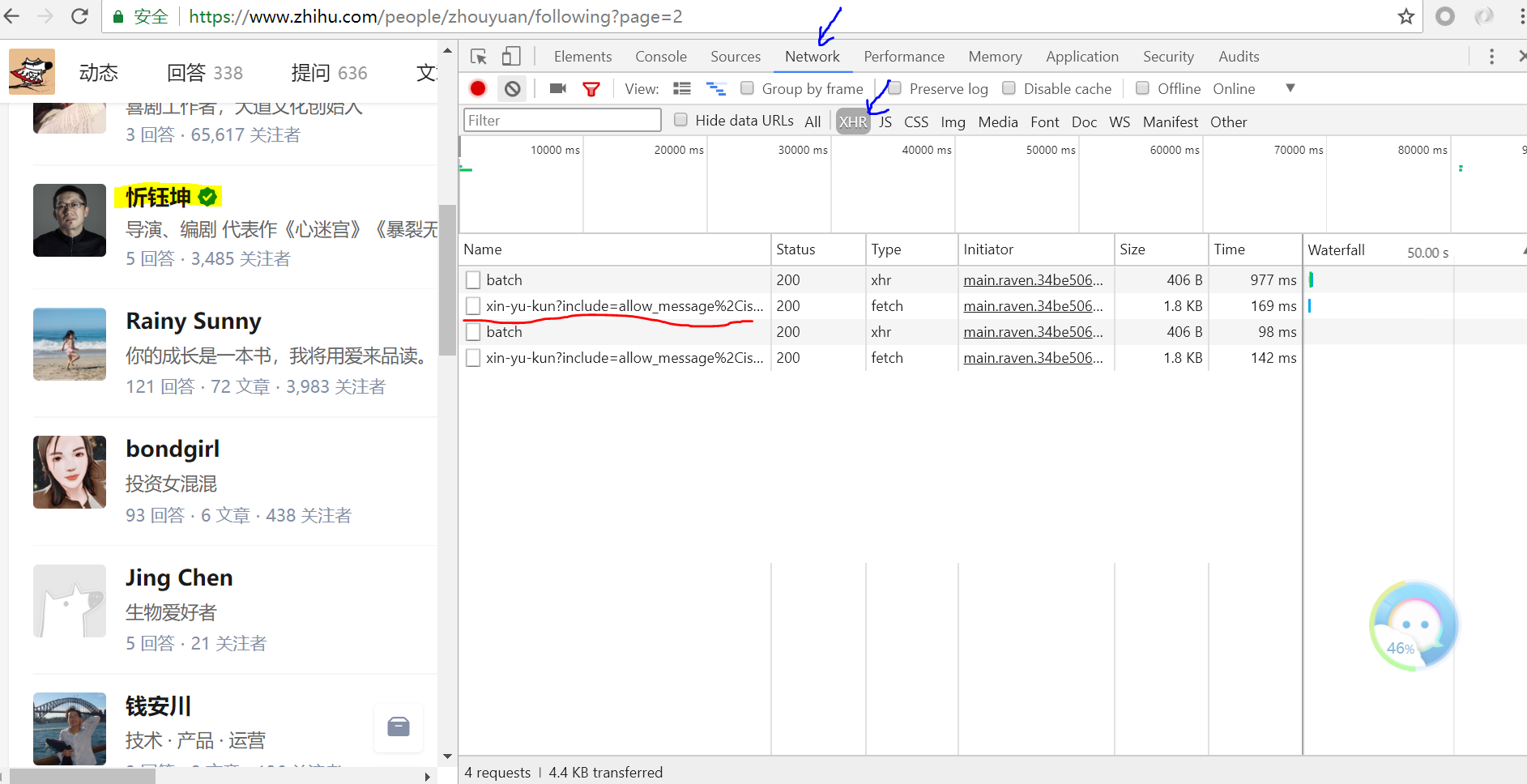
单击该ajax请求,得到如下页面:我们可以看见黄色部分为每位用户的详细信息的url,它包含多个参数用来存储信息
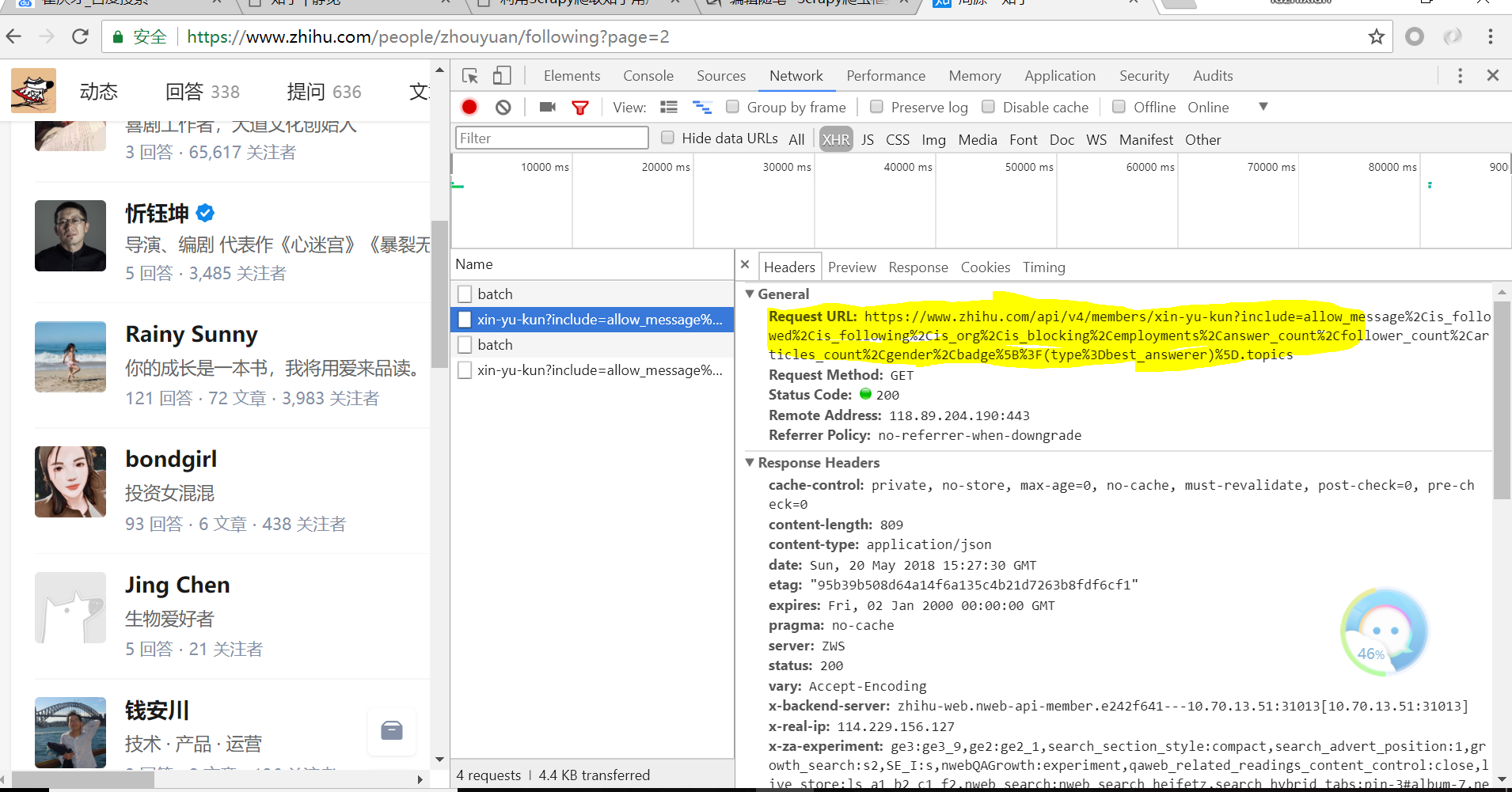
此时再将页面下滑可以看到如下信息:

该字段为上面参数的字段详情(Query String Parameters,英文好的小伙伴应该一眼发现)
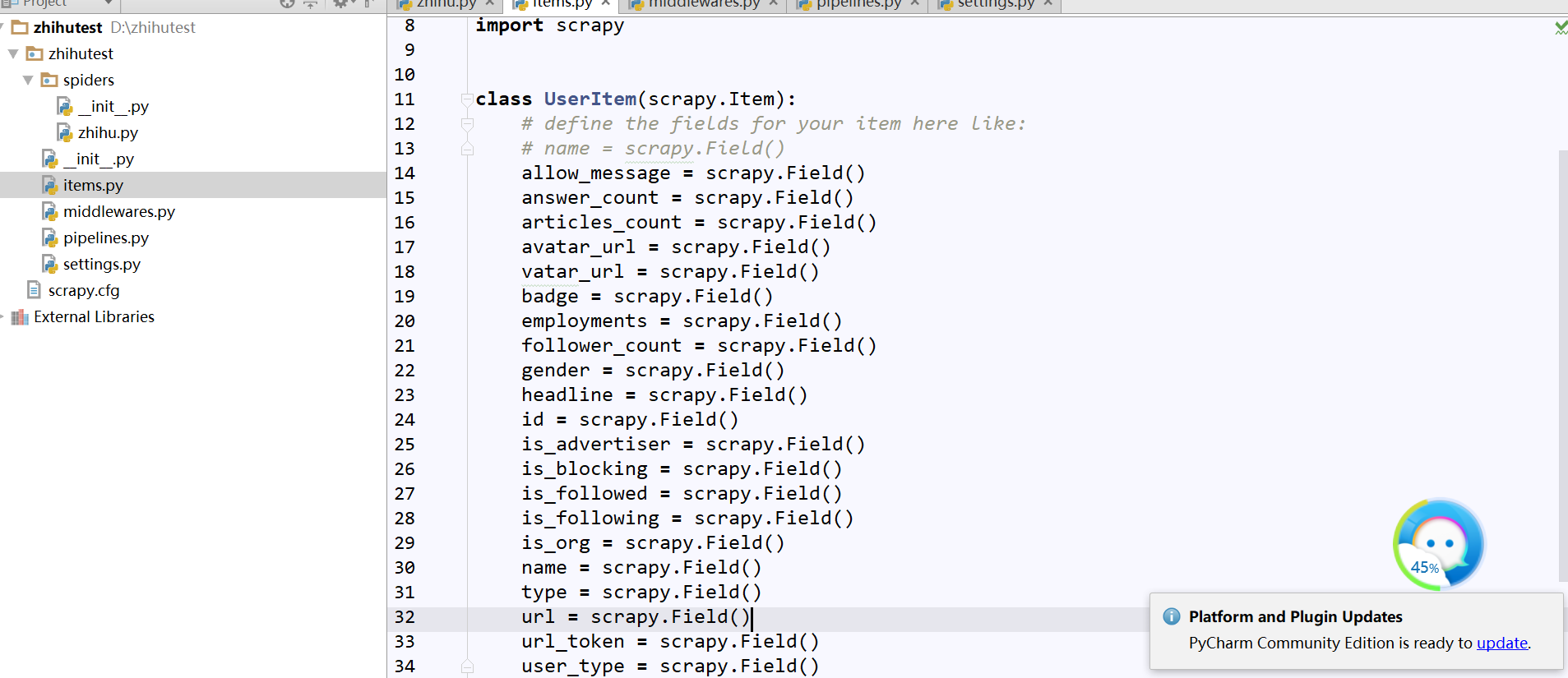
(5)、更改items.py
承接上面将页面点击左侧并翻页,可以看出右侧出现了新的Ajax请求:followees:......这就是他关注者信息,通过点击Preview我们获取了网页源代码,可以发现包含了每一页的用户信息,小伙伴们可以核对下,发现信息能匹配上,我们可以从中发现每页包含20条他的关注者信息,而黑框部分就是包含每一位用户详细信息的参数,我们通过它们来定义item.py(即爬什么???)
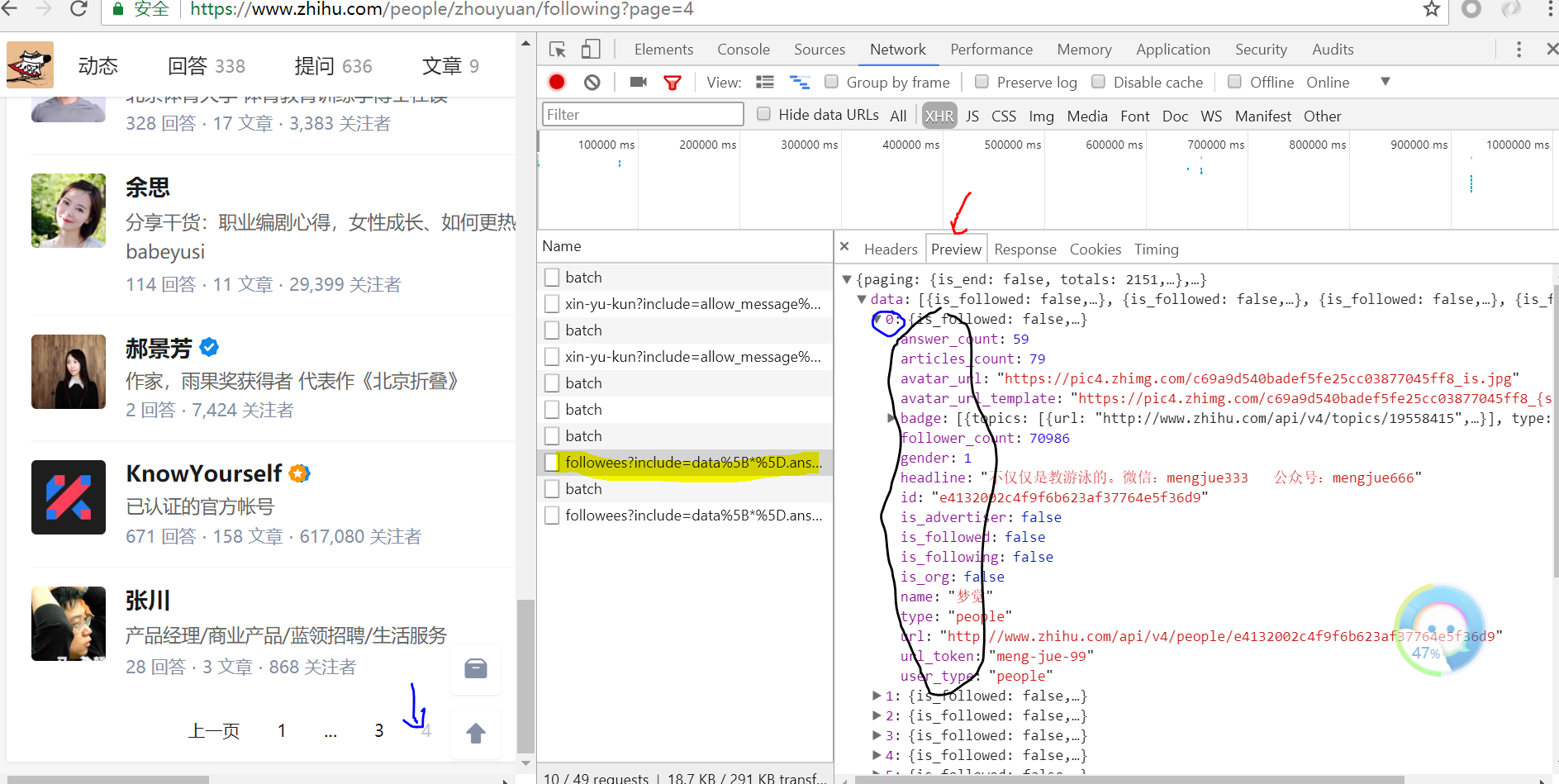
修改items.py如下:
(6)、更改zhihu.py
第一步:模块导入

1 # -*- coding: utf-8 -*- 2 import json 3 4 import scrapy 5 6 from ..items import UserItem 7 8 9 class ZhihuSpider(scrapy.Spider): 10 name = 'zhihu' 11 allowed_domains = ['zhihu.com'] 12 start_urls = ['http://zhihu.com/'] 13 14 #设定起始爬取人,这里我们通过观察发现与url_token字段有关 15 start_user = 'zhouyuan' 16 17 #选取起始爬取人的页面详情信息,这里我们传入了user和include参数方便对不同的用户进行爬取 18 user_url = 'https://www.zhihu.com/api/v4/members/{user}?include={include}' 19 #用户详情参数即包含在include后面的字段 20 user_query = 'allow_message,is_followed,is_following,is_org,is_blocking,employments,answer_count,follower_count,articles_count,gender,badge[?(type=best_answerer)].topics' 21 22 #这是他的关注者的url,这里包含了每位他的关注者的url,同样我们传入了user和include参数方便对不同用户进行爬取 23 follows_url = 'https://www.zhihu.com/api/v4/members/{user}/followees?include={include}&offset={offset}&limit={limit}' 24 #他的每位关注者详情参数,即包含在include后面的字段 25 follows_query = 'data[*].answer_count,articles_count,gender,follower_count,is_followed,is_following,badge[?(type=best_answerer)].topics' 26 27 #这是他的粉丝的url,这里包含了每位他的关注者的url,同样我们传入了user和include参数方便对不同用户进行爬取 28 followers_url = 'https://www.zhihu.com/api/v4/members/{user}/followees?include={include}&offset={offset}&limit={limit}' 29 #他的每位粉丝的详情参数,即包含在include后面的字段 30 followers_query = 'data[*].answer_count,articles_count,gender,follower_count,is_followed,is_following,badge[?(type=best_answerer)].topics' 31 32 #重新定义起始爬取点的url 33 def start_requests(self): 34 #这里我们传入了将选定的大V的详情页面的url,并指定了解析函数parseUser 35 yield scrapy.Request(self.user_url.format(user=self.start_user, include=self.user_query), callback=self.parseUser) 36 #这里我们传入了将选定的大V他的关注者的详情页面的url,并指定了解析函数parseFollows 37 yield scrapy.Request(self.follows_url.format(user=self.start_user, include=self.follows_query, offset=0, limit=20), callback=self.parseFollows) 38 #这里我们传入了将选定的大V的粉丝的详情页面的url,并指定了解析函数parseFollowers 39 yield scrapy.Request(self.followers_url.format(user=self.start_user, include=self.followers_query, offset=0, limit=20), callback=self.parseFollowers) 40 41 #爬取每一位用户详情的页面解析函数 42 def parseUser(self, response): 43 #这里页面上是json字符串类型我们使用json.loads()方法将其变为文本字符串格式 44 result = json.loads(response.text) 45 item = UserItem() 46 47 #这里我们遍历了items.py中定义的字段并判断每位用户的详情页中的keys是否包含该字段,如包含则获取 48 for field in item.fields: 49 if field in result.keys(): 50 item[field] = result.get(field) 51 yield item 52 #定义回调函数,爬取他的关注者与粉丝的详细信息,实现层层迭代 53 yield scrapy.Request(self.follows_url.format(user=result.get('url_token'), include=self.follows_query, offset=0, limit=20), callback=self.parseFollows) 54 yield scrapy.Request(self.followers_url.format(user=result.get('url_token'), include=self.followers_query, offset=0, limit=20), callback=self.parseFollowers) 55 56 #他的关注者的页面解析函数 57 def parseFollows(self, response): 58 results = json.loads(response.text) 59 #判断data标签下是否含有获取的文本字段的keys 60 if 'data' in results.keys(): 61 for result in results.get('data'): 62 yield scrapy.Request(self.user_url.format(user=result.get('url_token'), include=self.user_query), callback=self.parseUser) 63 #判断页面是否翻到了最后 64 if 'paging' in results.keys() and results.get('paging').get('is_end') == False: 65 next_page = results.get('paging').get('next') 66 yield scrapy.Request(next_page, callback=self.parseFollows) 67 68 #他的粉丝的页面解析函数 69 def parseFollowers(self, response): 70 results = json.loads(response.text) 71 72 if 'data' in results.keys(): 73 for result in results.get('data'): 74 yield scrapy.Request(self.user_url.format(user=result.get('url_token'), include=self.user_query), callback=self.parseUser) 75 76 if 'paging' in results.keys() and results.get('paging').get('is_end') == False: 77 next_page = results.get('paging').get('next') 78 yield scrapy.Request(next_page, callback=self.parseFollowers)
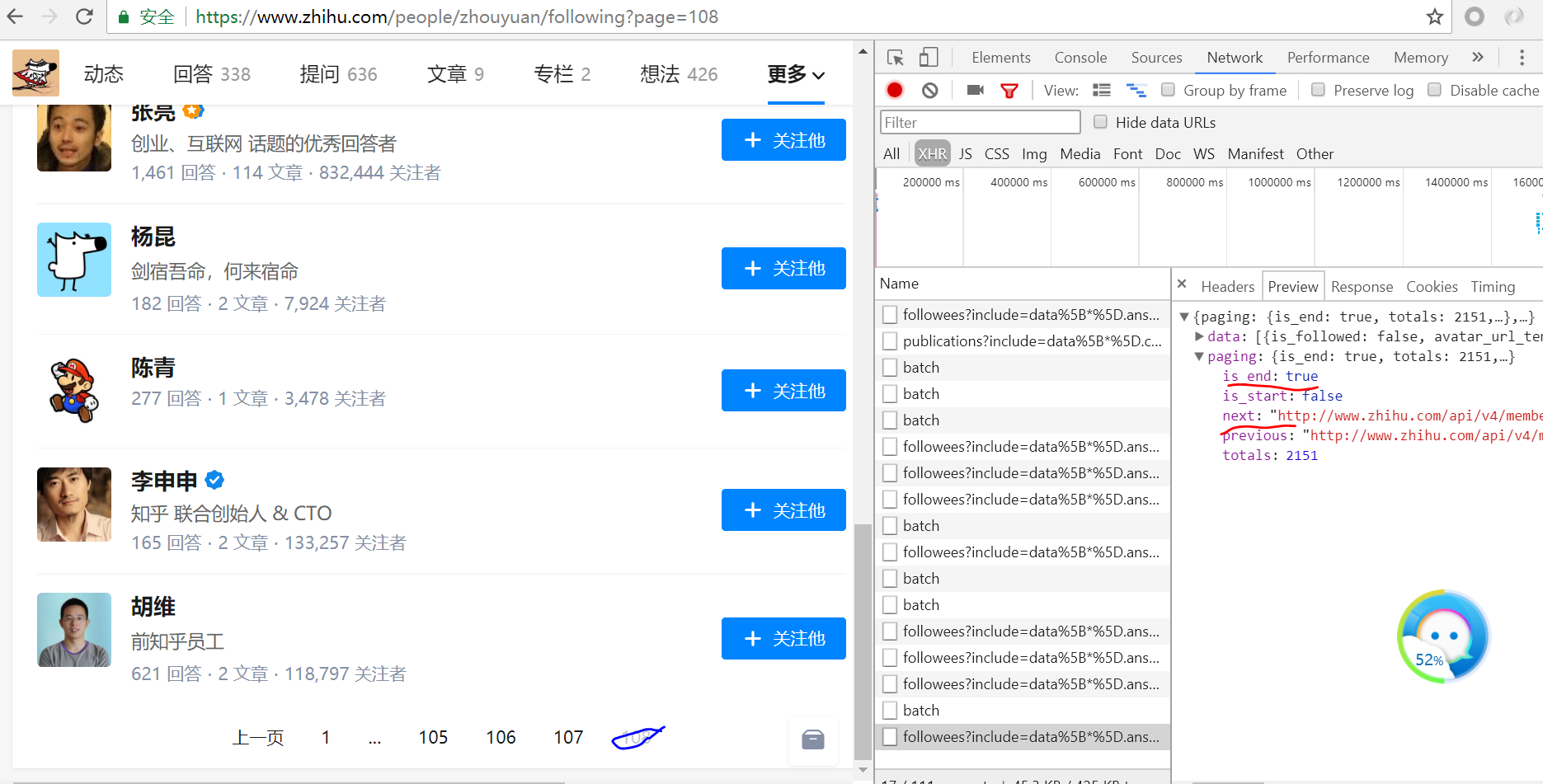
我们可以看到当我们翻到了最后is_end字段变为了True,而next字段就是下一个页面的url
(7)、运行下程序,可以看见已经在爬取了

(8)、将结果存入Mongodb数据库
重写pipelines.py
1 import pymongo 2 3 class MongoPipeline(object): 4 5 collection_name = 'user' 6 7 def __init__(self, www.yigouyule2.cn mongo_uri, mongo_db): 8 self.mongo_uri = mongo_uri 9 self.mongo_db = mongo_db 10 11 @classmethod 12 def from_crawler(cls, crawler): 13 return cls( 14 mongo_uri=crawler.www.089188.cn settings.get('MONGO_URI'), 15 mongo_db=crawler.settings.get('MONGO_DATABASE') 16 ) 17 18 def open_spider(self, spider): 19 self.client = pymongo.MongoClient(self.mongo_uri) 20 self.db = self.www.ruishengks.com client[self.mongo_db] 21 22 def close_spider(self, spider): 23 self.client.close(www.ruishengks.com) 24 25 def process_item(self, item, spider): 26 self.db[www.feifanyule.cn/'www.120xh.cn user'].update({'url_token www.taohuayuan178.com ' :item['url_token']},{'$set':item},True)
代码分析:
我们创建了名为user的集合
重写了__init__方法指定了数据库的链接地址和数据库名称
并修改了工厂类函数(具体参见上讲ITEM PIPLELIEN用法)
打开数据库并插入数据并以url_token字段对重复数据执行了更新操作
最后我们关闭了数据库
再配置下settings.py


再次运行程序,可以看见我们的数据就到了数据库了














 107
107











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









