










消息在通过 send() 方法发往 broker 的过程中,有可能需要经过拦截(Interceptor)、序列化器(Serializer)和分区器(Partitioner)的一系列作用之后才能被真正地发往 broker。拦截器一般不是必需的,而序列化器是必需的。消息经过序列化之后就需要确定它发往的分区,如果消息 ProducerRecord 中指定了 partition 字段,那么就不需要分区器的作用,因为 partition 代表的就是所要发往的分区号。
如果消息 ProducerRecord 中没有指定 partition 字段,那么就需要依赖分区器,根据 key 这个字段来计算 partition 的值。分区器的作用就是为消息分配分区。
Kafka 中提供的默认分区器是 org.apache.kafka.clients.producer.internals.DefaultPartitioner,它实现了 org.apache.kafka.clients.producer.Partitioner 接口,这个接口中定义了2个方法,具体如下所示。
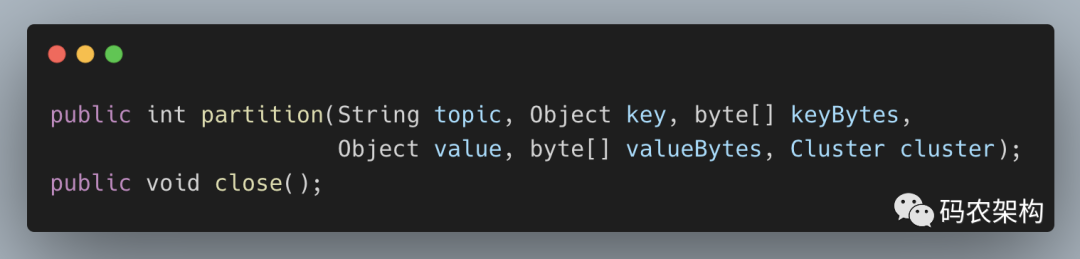
其中 partition() 方法用来计算分区号,返回值为 int 类型。partition() 方法中的参数分别表示主题、键、序列化后的键、值、序列化后的值,以及集群的元数据信息,通过这些信息可以实现功能丰富的分区器。close() 方法在关闭分区器的时候用来回收一些资源。
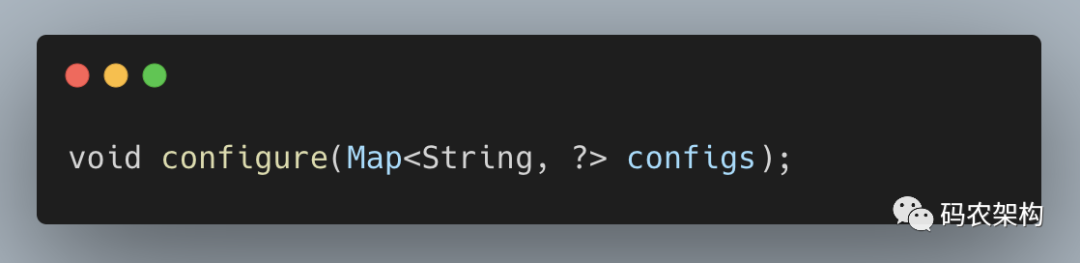
Partitioner 接口还有一个父接口 org.apache.kafka.common.Configurable,这个接口中只有一个方法:
注意:如果 key 不为 null,那么计算得到的分区号会是所有分区中的任意一个;如果key 为 null 并且有可用分区时,那么计算得到的分区号仅为可用分区中的任意一个,注意两者之间的差别。
在不改变主题分区数量的情况下,key 与分区之间的映射可以保持不变。不过,一旦主题中增加了分区,那么就难以保证 key 与分区之间的映射关系了。
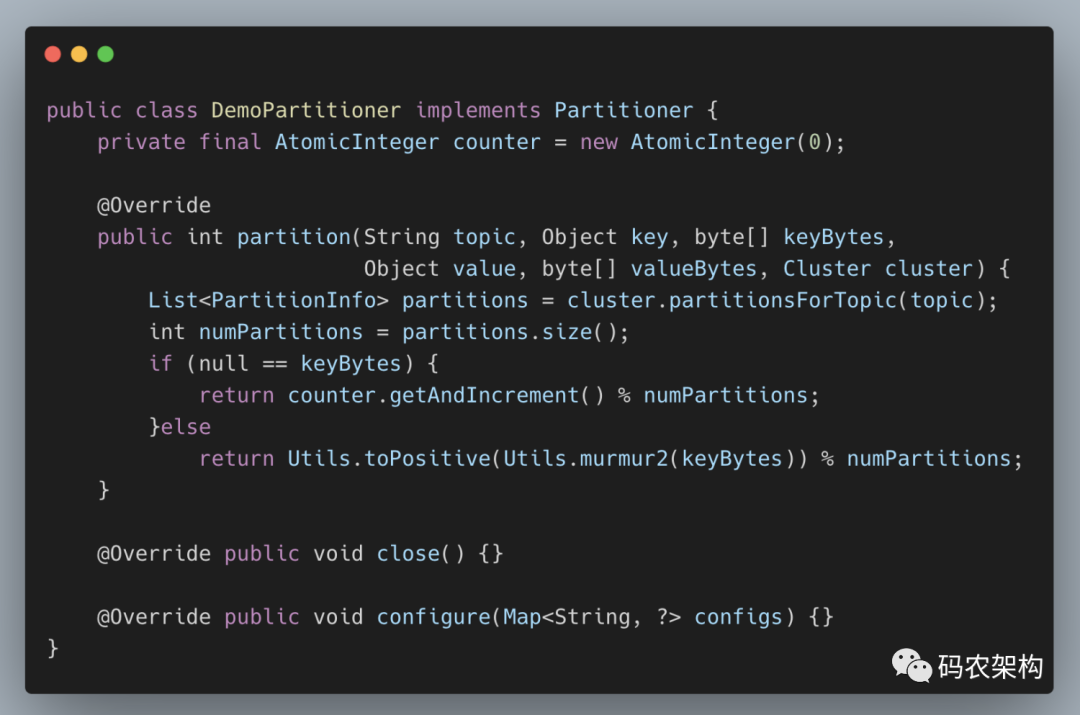
除了使用 Kafka 提供的默认分区器进行分区分配,还可以使用自定义的分区器,只需同 DefaultPartitioner 一样实现 Partitioner 接口即可。默认的分区器在 key 为 null 时不会选择非可用的分区,我们可以通过自定义的分区器 DemoPartitioner 来打破这一限制,具体的实现可以参考下面的示例代码
实现自定义的 DemoPartitioner 类之后,需要通过配置参数 partitioner.class 来显式指定这个分区器。示例如下:

这个自定义分区器的实现比较简单,读者也可以根据自身业务的需求来灵活实现分配分区的计算方式,比如一般大型电商都有多个仓库,可以将仓库的名称或 ID 作为 key 来灵活地记录商品信息。
















 1426
1426











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









