







原论文:Training Very Deep Networks
作者:Rupesh Kumar Srivastava Klaus Greff Jurgen Schmidhuber
时间:22 Jul 2015
本文的大部分观点来自于这篇论文,并且加入了一些自己的理解。该博客纯属读书笔记。
假设一个简单的由L层隐层构成的网络,我们令它的参数去拟合函数H,为了推导方便,我们假设输入输出的维度相同。那么我们可以得到输出y:
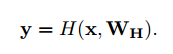
通过实验证明求解器很难优化这个函数,所以我们将这个函数做适当的变形。我们加了两个新的函数T和C:
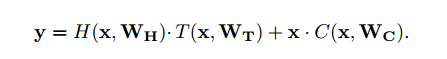
在这里我们可以简单的将函数T理解为实现了对原函数H,也就是输入输出的映射函数的一个放大或缩小的功能。函数C是对输入C的直接传送,使输入不经过函数H的映射直接加到输出y上。they express how much of the output is produced by transforming the input and carrying it 。
为了让式子更简洁,我们让C=1-T,得到:
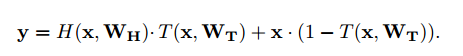
我们发现:
4
当T=0,输入和输出变成了恒等映射关系,当T=1,输入和输出变成了原来的y=H(x)。
而当T=0.5时我们发现,y=0.5*H(x)+0.5x,再用F(x)代替H(x)*2,我们发现y=x+F(x),所以残差函数实际上是函数3的一个特例。
文章除了实验以外,并没有给出足够的理论依据。















 9735
9735

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









