




分类:
lucene
2013-05-03 23:42
554人阅读
评论(1)
收藏
举报
Tika是Apache的Lucene项目下面的子项目,在lucene的应用中可以使用tika获取大批量文档中的内容来建立索引,非常方便,也很容易使用~
Tika的缺点就是都是依赖外部的jar包,导致jar包的重量太大,lucene的核心包只有1M,tika约20M,tika依赖的外部的jar包有多样的功能,比如PDFBox和Apache POI能获取文档的字体,布置和内置图片信息,而Tika只是获取文本信息。但是这些外部的jar包又没有把获取文本信息的抽离出一个单独的jar包。
1、Tika的作用
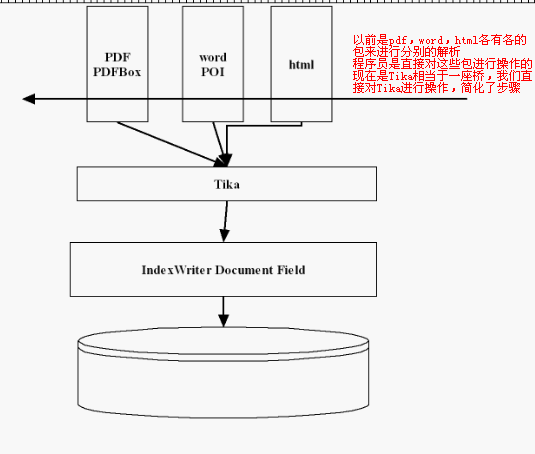
工程结构:
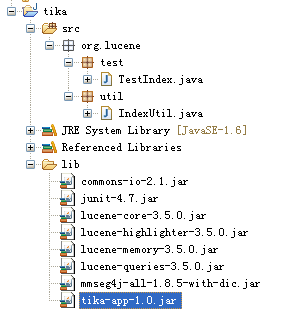
2、Tika的工具类
- package org.lucene.util;
- import java.io.File;
- import java.io.FileInputStream;
- import java.io.FileNotFoundException;
- import java.io.IOException;
- import java.io.InputStream;
- import org.apache.lucene.document.Document;
- import org.apache.lucene.document.Field;
- import org.apache.lucene.index.CorruptIndexException;
- import org.apache.lucene.index.IndexWriter;
- import org.apache.lucene.index.IndexWriterConfig;
- import org.apache.lucene.store.Directory;
- import org.apache.lucene.store.FSDirectory;
- import org.apache.lucene.store.LockObtainFailedException;
- import org.apache.lucene.util.Version;
- import org.apache.tika.Tika;
- import org.apache.tika.exception.TikaException;
- import org.apache.tika.metadata.Metadata;
- import org.apache.tika.parser.AutoDetectParser;
- import org.apache.tika.parser.ParseContext;
- import org.apache.tika.parser.Parser;
- import org.apache.tika.sax.BodyContentHandler;
- import org.xml.sax.ContentHandler;
- import org.xml.sax.SAXException;
- import com.chenlb.mmseg4j.analysis.MMSegAnalyzer;
- public class IndexUtil {
- /**
- * 直接读取pdf建立索引,结果是索引建立成功了,但是索引存储的数据却是乱的
- */
- public void index() {
- try {
- File f = new File("F:\\文档资料\\lucene_in_action中文版.pdf");
- Directory dir = FSDirectory.open(new File("f:/lucene"));
- IndexWriter writer = new IndexWriter(dir,new IndexWriterConfig(Version.LUCENE_35, new MMSegAnalyzer()));
- writer.deleteAll();
- Document doc = new Document();
- doc.add(new Field("content",new Tika().parse(f)));
- writer.addDocument(doc);
- writer.close();
- } catch (CorruptIndexException e) {
- e.printStackTrace();
- } catch (LockObtainFailedException e) {
- e.printStackTrace();
- } catch (FileNotFoundException e) {
- e.printStackTrace();
- } catch (IOException e) {
- e.printStackTrace();
- }
- }
- /**
- * 根据Tika得到文档的内容,这种比下面那种获取的要简单很多,
- * 据tika的文档上说,效率没有下面的那种高,可能封装的比较多
- * @param f
- * @return
- * @throws IOException
- * @throws TikaException
- */
- public String tikaTool(File f) throws IOException, TikaException {
- Tika tika = new Tika();
- Metadata metadata = new Metadata();
- metadata.set(Metadata.AUTHOR, "空号");//重新设置文档的媒体内容
- metadata.set(Metadata.RESOURCE_NAME_KEY, f.getName());
- String str = tika.parseToString(new FileInputStream(f),metadata);
- for(String name:metadata.names()) {
- System.out.println(name+":"+metadata.get(name));
- }
- return str;
- }
- /**
- * 根据Parser得到文档的内容
- * @param f
- * @return
- */
- public String fileToTxt(File f) {
- Parser parser = new AutoDetectParser();//自动检测文档类型,自动创建相应的解析器
- InputStream is = null;
- try {
- Metadata metadata = new Metadata();
- metadata.set(Metadata.AUTHOR, "空号");//重新设置文档的媒体内容
- metadata.set(Metadata.RESOURCE_NAME_KEY, f.getName());
- is = new FileInputStream(f);
- ContentHandler handler = new BodyContentHandler();
- ParseContext context = new ParseContext();
- context.set(Parser.class,parser);
- parser.parse(is,handler, metadata,context);
- for(String name:metadata.names()) {
- System.out.println(name+":"+metadata.get(name));
- }
- return handler.toString();
- } catch (FileNotFoundException e) {
- e.printStackTrace();
- } catch (IOException e) {
- e.printStackTrace();
- } catch (SAXException e) {
- e.printStackTrace();
- } catch (TikaException e) {
- e.printStackTrace();
- } finally {
- try {
- if(is!=null) is.close();
- } catch (IOException e) {
- e.printStackTrace();
- }
- }
- return null;
- }
- }
package org.lucene.util;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.io.InputStream;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.index.CorruptIndexException;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.store.LockObtainFailedException;
import org.apache.lucene.util.Version;
import org.apache.tika.Tika;
import org.apache.tika.exception.TikaException;
import org.apache.tika.metadata.Metadata;
import org.apache.tika.parser.AutoDetectParser;
import org.apache.tika.parser.ParseContext;
import org.apache.tika.parser.Parser;
import org.apache.tika.sax.BodyContentHandler;
import org.xml.sax.ContentHandler;
import org.xml.sax.SAXException;
import com.chenlb.mmseg4j.analysis.MMSegAnalyzer;
public class IndexUtil {
/**
* 直接读取pdf建立索引,结果是索引建立成功了,但是索引存储的数据却是乱的
*/
public void index() {
try {
File f = new File("F:\\文档资料\\lucene_in_action中文版.pdf");
Directory dir = FSDirectory.open(new File("f:/lucene"));
IndexWriter writer = new IndexWriter(dir,new IndexWriterConfig(Version.LUCENE_35, new MMSegAnalyzer()));
writer.deleteAll();
Document doc = new Document();
doc.add(new Field("content",new Tika().parse(f)));
writer.addDocument(doc);
writer.close();
} catch (CorruptIndexException e) {
e.printStackTrace();
} catch (LockObtainFailedException e) {
e.printStackTrace();
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
/**
* 根据Tika得到文档的内容,这种比下面那种获取的要简单很多,
* 据tika的文档上说,效率没有下面的那种高,可能封装的比较多
* @param f
* @return
* @throws IOException
* @throws TikaException
*/
public String tikaTool(File f) throws IOException, TikaException {
Tika tika = new Tika();
Metadata metadata = new Metadata();
metadata.set(Metadata.AUTHOR, "空号");//重新设置文档的媒体内容
metadata.set(Metadata.RESOURCE_NAME_KEY, f.getName());
String str = tika.parseToString(new FileInputStream(f),metadata);
for(String name:metadata.names()) {
System.out.println(name+":"+metadata.get(name));
}
return str;
}
/**
* 根据Parser得到文档的内容
* @param f
* @return
*/
public String fileToTxt(File f) {
Parser parser = new AutoDetectParser();//自动检测文档类型,自动创建相应的解析器
InputStream is = null;
try {
Metadata metadata = new Metadata();
metadata.set(Metadata.AUTHOR, "空号");//重新设置文档的媒体内容
metadata.set(Metadata.RESOURCE_NAME_KEY, f.getName());
is = new FileInputStream(f);
ContentHandler handler = new BodyContentHandler();
ParseContext context = new ParseContext();
context.set(Parser.class,parser);
parser.parse(is,handler, metadata,context);
for(String name:metadata.names()) {
System.out.println(name+":"+metadata.get(name));
}
return handler.toString();
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} catch (SAXException e) {
e.printStackTrace();
} catch (TikaException e) {
e.printStackTrace();
} finally {
try {
if(is!=null) is.close();
} catch (IOException e) {
e.printStackTrace();
}
}
return null;
}
}
3、测试类
- package org.lucene.test;
- import java.io.File;
- import java.io.IOException;
- import org.apache.tika.exception.TikaException;
- import org.junit.Test;
- import org.lucene.util.IndexUtil;
- public class TestIndex {
- @Test
- public void testIndex() {
- IndexUtil iu = new IndexUtil();
- iu.index();
- }
- @Test
- public void testTika01() {
- IndexUtil iu = new IndexUtil();
- System.out.println(iu.fileToTxt(new File("F:\\文档资料\\lucene_in_action中文版.pdf")));
- }
- @Test
- public void testToka02() throws IOException, TikaException {
- IndexUtil iu = new IndexUtil();
- System.out.println(iu.tikaTool(new File("F:\\文档资料\\初级SQL开发指南.doc")));
- }
- }
package org.lucene.test;
import java.io.File;
import java.io.IOException;
import org.apache.tika.exception.TikaException;
import org.junit.Test;
import org.lucene.util.IndexUtil;
public class TestIndex {
@Test
public void testIndex() {
IndexUtil iu = new IndexUtil();
iu.index();
}
@Test
public void testTika01() {
IndexUtil iu = new IndexUtil();
System.out.println(iu.fileToTxt(new File("F:\\文档资料\\lucene_in_action中文版.pdf")));
}
@Test
public void testToka02() throws IOException, TikaException {
IndexUtil iu = new IndexUtil();
System.out.println(iu.tikaTool(new File("F:\\文档资料\\初级SQL开发指南.doc")));
}
}工程路径:http://download.csdn.net/detail/wxwzy738/5328383

















 2093
2093

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









