









转载:http://blog.csdn.net/lux_veritas/article/details/9345781
有关进程的创建,详细的机制书本上与在线资源中有很多说明,这篇文章有比较详细的介绍,可以先仔细阅读里面的内容。
本篇文章简要介绍linux可执行文件的进程创建与加载的过程。linux在创建进程时,采用写时复制(copy on write)技术,在加载进程时,采用按需加载机制。
写时复制技术
父进程通过fork()系统调用创建子进程,子进程复制父进程的页目录和页表结构,同时将对应的物理页设为只读。当其中的一个进程在自己的虚拟地址范围内进行写操作的时候,就会产生异常,引起中断,中断处理函数就会在物理内存中再分配一个空闲页,并将引起异常的这个页的内容copy进去,并修改对应的页表项,同时将这两个页修改为可读写,这样这两个进程就各自拥有了一个物理页了。这就是写时复制机制。
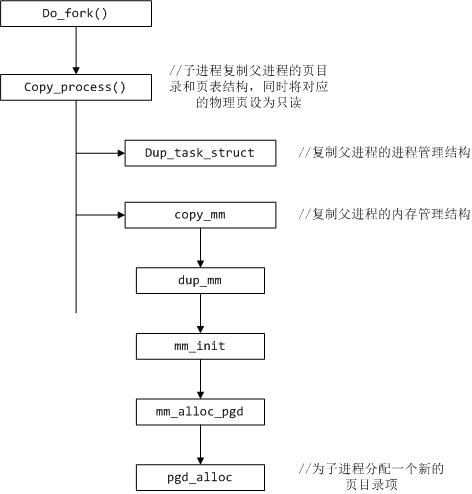
按需加载机制
在fork出一个新进程后,通常会伴随着execve系统调用,为这个进程加载内容。这个时候,execve会删除这个进程原有的数据段和代码段占用的页表项,随后系统会为加载进来的环境参数和命令行参数分配一定物理页和对应的页表。除此之外,这个进程的代码和数据没有占用物理内存的任何空间,它门还在磁盘上。但一旦从程序的开始处执行的时候,访问代码和数据的时候,就会发现它们没在内存中,这个时候就会引起缺页中断,中断处理会将在内存中申请一页内存存放数据,并在设置页表中的对应的页表项,如果不存在页表的话,还要申请一页内存存放页表,最后将请求的代码或者数据以块为单位从磁盘上复制到内存中。这就是需求加载机制。
有了以上理论基础,简要分析一下linux可执行文件的加载过程:
在linux下执行某程序,通常采用如下方式:
- Linux> ./a.out
操作系统首先判断此命令并非shell命令,于是以linux可执行文件视之。shell父进程调用fork,创建一个新进程,此新进程即为可执行文件的进程,fork调用完成后,新进程获得了新的页目录项,除此之外与shell父进程共享同一套页表结构。此时切换到新进程执行,执行execve系统调用,获取可执行文件的header信息,将其拷贝到主存中,并为之建立新的页表结构。通过header信息,建立新进程的进程地址空间与可执行文件的映射关系。此时新进程的进程地址空间视图中代码段、数据段仍为空,可执行文件相应的数据仍未拷贝到主存中,通过header中指定的执行程序入口,逐步将相应的段数据拷贝到主存中,并利用缺页中断位置建立相应的页表结构。除了一些header信息,在整个加载过程中没有任何从磁盘到主存的数据拷贝,直到CPU引用一个未被映射的虚拟页导致缺页中断的发生,才会进行拷贝。此时,操作系统利用它的页面调度机制自动将页面从磁盘拷贝到主存储器中。















 8622
8622

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









