




 本文介绍了一种新的策略ThreadofThought(ThoT),它模仿人类认知过程,帮助大型语言模型在处理混乱上下文时提高推理性能。ThoT通过分段和分析上下文,增强了LLMs在复杂信息处理中的效率,可与多种模型和提示技术无缝集成。
本文介绍了一种新的策略ThreadofThought(ThoT),它模仿人类认知过程,帮助大型语言模型在处理混乱上下文时提高推理性能。ThoT通过分段和分析上下文,增强了LLMs在复杂信息处理中的效率,可与多种模型和提示技术无缝集成。
论文地址:Thread of Thought Unraveling Chaotic Contexts
摘要
大型语言模型(LLMs)在自然语言处理领域开启了一个变革的时代,在文本理解和生成任务上表现出色。然而,当面对混乱的上下文环境(例如,干扰项而不是长的无关上下文)时,它们会遇到困难,导致无意中忽略了混乱上下文中的某些细节。为了应对这些挑战,我们引入了“思维线索”(Thread of Thought,ThoT)策略,该策略受到人类认知过程的启发。ThoT策略能够系统地分段和分析扩展的上下文,同时巧妙地选择相关信息。这个策略作为一个多功能的“即插即用”模块,可以与各种LLMs和提示技术无缝集成。在实验中,我们使用了PopQA和EntityQ数据集,以及我们收集的多轮对话响应数据集(MTCR),来说明ThoT策略在推理性能上显著优于其他提示技术。
Introduction
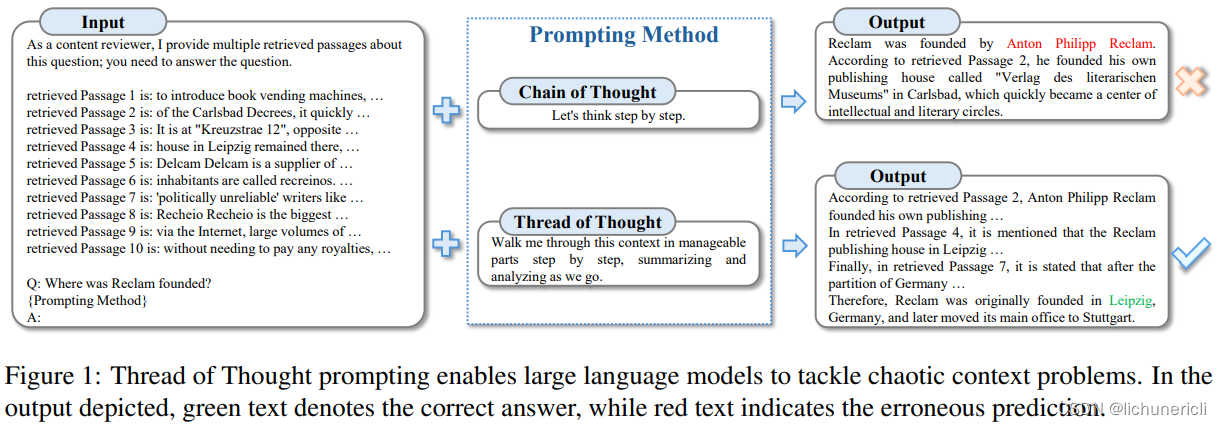
LLMs在人工智能领域,特别是在自然语言理解和生成方面取得的显著进展。这些模型在多项自然语言处理任务中展示了卓越的能力,如情感分析、机器翻译和摘要生成等,并在法律咨询和医疗诊断等行业中发挥着重要作用。
然而,尽管LLMs在处理长文本和复杂对话场景中表现出色,但它们在面对“混乱上下文”(Chaotic Contexts)时仍面临挑战。所谓的混乱上下文是指输入文本中包含大量来自不同来源的信息,这些信息可能是相互关联的,也可能是完全不相关的,且某些信息的重要性会根据上下文的不同而变化。这与“长上下文”(Long Context)不同,混乱上下文更强调信息的复杂性和数量,而不仅仅是文本的长度。
为
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









