







Hadoop Architecture
用下图描述 hadoop 的四元素
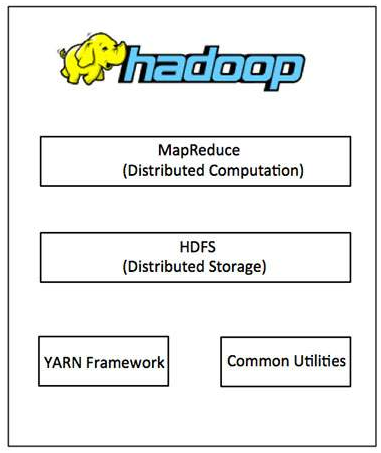
- hadoop commom: 其他hadoop modules 所需要的 java 库和工具;
- hadoop YARN: 用与做 job scheduling 和 cluster resource management 的 框架;
- Hadoop Distributed File System (HDFSTM): 一个基于谷歌文件系统(GFS)的分布式文件系统,可以提供对应用数据高吞吐量的访问。
- Hadoop MapReduce: 一个用于并行处理大数据集的系统, YARN-based。
HDFS
hadoop 上最常用的文件系统。
HDFS 用的是 master/slave architecture,包括一个master (NameNode) 管理文件系统的大量数据,和数个slaves(DataNodes)用于真正的存储数据.
HDFS里的一个文件被分成若干个块(Blocks)分别存储在若干个DataNodes里。
NameNode
- 管理 Blocks 和DataNodes 的映射关系
- 管理 client 对文件袋额访问权限。
- 执行 renaming, closing 和 opening 对文件或文件夹的操作。
DataNode
- 执行文件系统的读、写操作
- 以及按 NameNode 发出的指示对Blocks进行Creation, deletion 和 replication。
HDFS 提供了shell 和一系列的指令用于文件系统的交互。
MapReduce
以一种可靠地、高容错性的方式在集群上并行化的处理大规模数据。
- The Map Task
- The Reduce Task
MapReduce Framework 的每个 Cluster-node 上包含一个 JobTracker(master) 和一个 TaskTracker(slave):
- JobTracker: 负责
- 资源管理,resource management,tracking resource consumption/availability
- 分配并监督slaves 的任务,scheduling the jobs component tasks on the slaves, monitoring them
- 重新执行失败的任务,re-executing the failed tasks
- TaskTracker: 负责
- 执行任务,execute the tasks as directed by the master
- 定时向master汇报状态,provide task-status information to the master periodically
Work Stages
- Stage 1: 一个应用程序向 Hadoop 提交一项工作(job)的时候需要指定一下几项:
- 分布式文件系统中输入输出文件的 location;
- 包含 Map 和 Reduce 函数的执行语句的 jar file;
- 此项工作需要单独配置的参数 job configuration.
- Stage 2: 应用程序向 Hadoop 提交工作和配置给 JobTracker。JobTracker 把配置参数发布给slaves, 然后分配任务(task)、监督Slave的工作,并且向应用程序提供运行状态和诊断信息。
- Stage 3: 每一次 MapReduce 操作,分布在不同节点上的 TaskTracker 执行一次任务,并且把Reduce 操作的输出保存在文件系统。















 247
247

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









