







强烈推荐:http://www.wildml.com/2015/11/understanding-convolutional-neural-networks-for-nlp
论文:《Convolutional Neural Networks for Sentence Classification》
Tensorflow 实现blog:http://www.wildml.com/2015/12/implementing-a-cnn-for-text-classification-in-tensorflow
代码:https://github.com/dennybritz/cnn-text-classification-tf
框架
首先,理解下卷积:
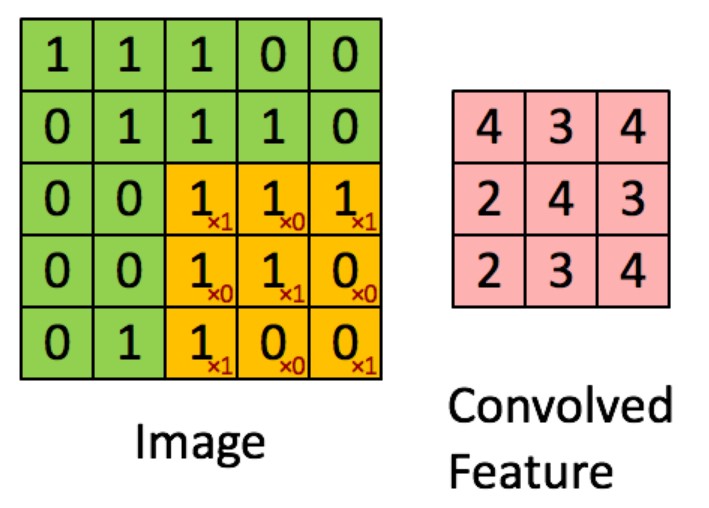
片段
- ReLU,可以实现稀疏。为什么?假设一个神经元的输出是付出,那ReLU后,就是0,上面的也无法向下传递梯度,这个就会保持在0,就稀疏了。而sigmoid这种,在情况不好的时候,还是有机会“翻身”的。
“ReLu的使用,使得网络可以自行引入稀疏性。这一做法,等效于无监督学习的预训练。更快的特征学习。”
“一句话概括:不用simgoid和tanh作为激活函数,而用ReLU作为激活函数的原因是:加速收敛。
因为sigmoid和tanh都是饱和(saturating)的。何为饱和?个人理解是把这两者的函数曲线和导数曲线plot出来就知道了:他们的导数都是倒过来的碗状,也就是,越接近目标,对应的导数越小。而ReLu的导数对于大于0的部分恒为1。于是ReLU确实可以在BP的时候能够将梯度很好地传到较前面的网络。”
http://blog.csdn.net/liulina603/article/details/44915905
http://www.cnblogs.com/xinchrome/p/4964930.html
http://www.cnblogs.com/neopenx/p/4453161.html
DropOut,理解为ensemble。在训练时有用,在预测时候不需要。每次都会随机选择一部分神经元失效,相当于用了不同的模型去做。防止过拟合。(感觉自己都说服不了–#)
adam,并不理解细节,“Adam 算法根据损失函数对每个参数的梯度的一阶矩估计和二阶矩估计动态调整针对于每个参数的学习速率”,就是学习速率不一致?
Batch_Size: https://www.zhihu.com/question/32673260,大数据集,全学习太慢不可行。如果极端,每次只训练一个样本,各个梯度不断修正,难以收敛。
更多资料:
2010-2016年被引用次数最多的深度学习论文: http://synchuman.baijia.baidu.com/article/495369
Tensorflow中文文档:http://wiki.jikexueyuan.com/project/tensorflow-zh/
深度学习博客:http://blog.csdn.net/zouxy09/article/details/8775518
Tensorflow博客,padding、strike这些:http://www.cnblogs.com/hellocwh/p/5564568.html















 2164
2164

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









