










flink背压的两种场景
1.本地传输
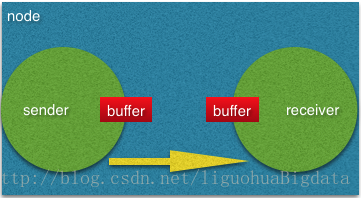
如果task1和task2都运行在同一个工作节点(TaskManager),缓冲区可以被直接共享给下一个task,一旦task 2消费了数据它会
被回收。如果task 2比task 1慢,buffer会以比task 1填充的速度更慢的速度进行回收从而迫使task 1降速。
2.网络传输
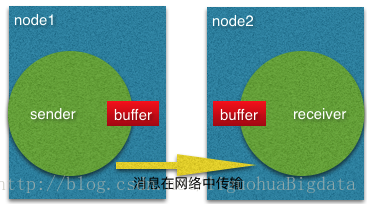
如果task 1和task 2运行在不同的工作节点上。一旦缓冲区内的数据被发送出去(TCP Channel),它就会被回收。在接收端,数据被
拷贝到输入缓冲池的缓冲区中,如果没有缓冲区可用,从TCP连接中的数据读取动作将会被中断。输出端通常以watermark机制来保证不
会有太多的数据在传输途中。如果有足够的数据已经进入可发送状态,会等到情况稳定到阈值以下才会进行发送。这可以保证没有太多的
数据在路上。如果新的数据在消费端没有被消费(因为没有可用的缓冲区),这种情况会降低发送者发送数据的速度。
flink背压的性能测试
下面这张图显示了:随着时间的改变,生产者(黄色线)和消费者(绿色线)基于所达到的最大吞吐(在单一JVM中每秒达到8百万条记录)
的平均吞吐百分比。我们通过衡量task每5秒钟处理的记录数来衡量平均吞吐。
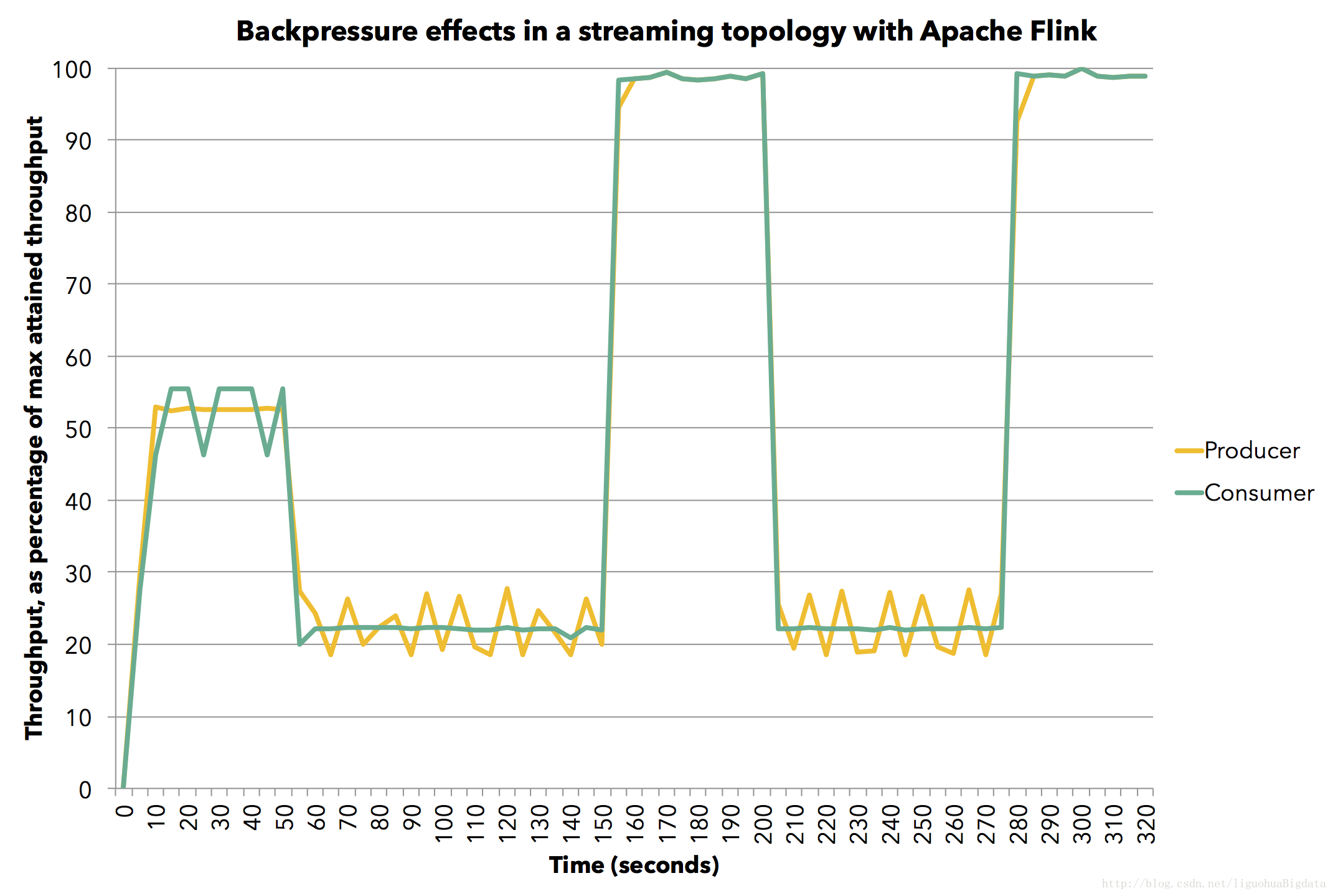
首先,我们运行生产者task到它最大生产速度的60%(我们通过Thread.sleep()来模拟降速)。消费者以同样的速度处理数据。
然后,我们将消费task的速度降至其最高速度的30%。你就会看到背压问题产生了,正如我们所见,生产者的速度也自然降至其最高速度的30%。
接着,我们对消费者停止人为降速,之后生产者和消费者task都达到了其最大的吞吐。接下来,我们再次将消费者的速度降至30%,pipeline给出了立即响应:生产者的速度也被自动降至30%。
最后,我们再次停止限速,两个task也再次恢复100%的速度。这所有的迹象表明:生产者和消费者在pipeline中的处理都在跟随彼此的吞吐而进行适当的调整,这就是我们在流pipeline中描述的行为。
flink背压的总结
Flink与持久化的source(例如kafka),能够为你提供即时的背压处理,而无需担心数据丢失。Flink不需要一个特殊的机制来处理背压,
因为Flink中的数据传输相当于已经提供了应对背压的机制。因此,Flink所获得的最大吞吐量由其pipeline中最慢的部件决定。















 250
250

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









