






为了让飞桨开发者们掌握第一手技术动态、让企业落地更加高效,飞桨官方在7月至10月特设《飞桨框架3.0全面解析》系列技术稿件及直播课程。技术解析加代码实战,带大家掌握包括核心框架、分布式计算、产业级大模型套件及低代码工具、前沿科学计算技术案例等多个方面的框架技术及大模型训推优化经验。
01 背景
大模型已经成为人工智能最重要的领域之一。随着模型规模持续快速增长和模型复杂性的增加,计算瓶颈、存储瓶颈、访存瓶颈以及通信瓶颈等问题逐渐凸显。同时新的网络结构如 RWKV、Mamba 等也在不断涌现,为 AI 技术的发展注入了新的活力。为了解决这些问题,大规模分布式训练和通用性能优化的需求日益迫切。
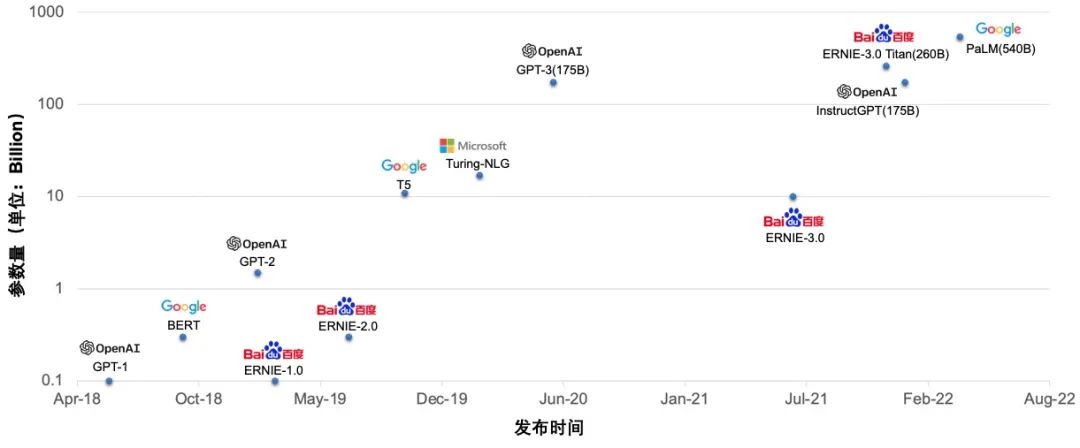
△大模型规模快速增长
大模型往往需要使用多维混合并行方式进行训练。飞桨率先提出了四维混合并行技术,实现了数据并行、张量模型并行、流水线并行、分组参数切片并行的高效协同训练,并扩展到包括序列分片并行在内的五维混合并行,有效提升长序列输入下大模型分布式训练效率。然而,多维混合并行的开发过程往往相当复杂,开发者必须精心处理计算、通信、调度等多种逻辑,才能编写出正确的混合并行代码,这无疑提高了分布式训练开发的难度。为了解决这一难题,我们提出了动静统一自动并行的技术方案。
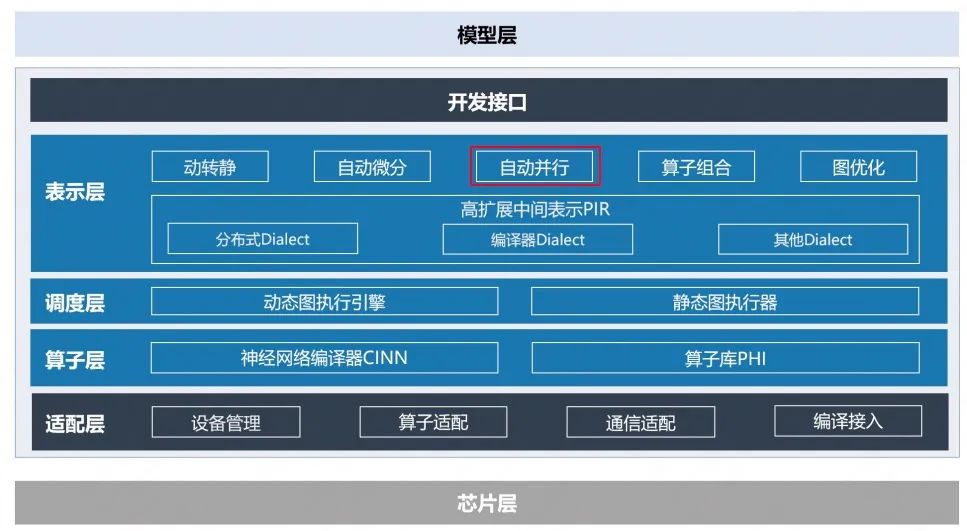
△飞桨框架3.0架构图
飞桨框架当前支持分布式训练当前主要有动态图手动并行和动静统一自动并行两种方式。
手动并行需要用户在开发训练代码时感知到分布式实现的细节,手动管理张量切分和通信,且不同并行策略都需要调用不同的接口,相对来说使用起来比较复杂。
自动并行为了降低用户开发分布式程序的门槛,提供了对不同分布式并行策略的统一抽象,让用户可以通过张量切分的语法标记即可实现不同并行策略。用户仅需使用少量的张量切分标注,框架便能自动推导出所有张量和算子的分布式切分状态,并添加合适的通信算子。同时自动并行还支持一键动转静分布式训练,开发者可以快速实现任意混合并行策略,大幅简化了混合并行训练代码的开发过程。
02 飞桨框架自动并行原理介绍
下文将主要介绍飞桨框架3.0自动并行框架中的主要概念和原理,让用户对这一全新的大模型分布式训练技术进行初步了解。
首先简要介绍一下自动并行架构的流程全貌。
用户按照单卡的逻辑视角进行模型组网,之后通过张量切分标记 API 对部分张量的切分进行语义标记 (详见下文2.1 章节),这是用户侧所需要做的所有代码开发,后续就进入框架的内部自动化流程。
框架的自动化流程主要有以下阶段:将用户标记的模型组网用分布式张量进行表示,然后进入切分推导流程为组网中的所有张量推导出一个合理高效的切分状态,接着框架的切分转换流程将为模型添加合适的通信算子 (详见下文2.2 章节),如果在静态图模式下还会基于静态图进行图优化提升训练性能 (详见下文4.1章节),最后用户可以保存或转换训练好的模型 checkpoint。
上述流程支持在动态图或静态图下执行,框架对外提供一套动静统一的接口 (详见下文2.3 章节)。下文中我们将更具体的介绍流程中的细节。

△飞桨框架3.0自动并行流程图
2.1 分布式张量表示
目前已有的分布式策略,数据并行,模型并行,都是通过(1)切分输入/输出(2)切分模型参数(3)切分计算 这三种方式,满足在多计算设备上加速训练大模型的需求。为了提供更易用的分布式接口,我们引入分布式张量这一概念,描述由多个计算设备上的局部物理张量通过既定计算共同组成的逻辑张量,用户可以通过以下接口来创建分布张量:
paddle.distributed.shard_tensor
为了描述分布张量和计算设备之间的映射关系,我们引入ProcessMesh和Placements两个分布概念。
-
ProcessMesh 是指用于大模型训练或推理的多个硬件设备拓扑结构。我们将一个设备(比如一块 GPU 卡)映射为一个进程,将多个设备映射为多个进程组成的一维或多维数组,下图展示了由4个设备构成的2*2 ProcessMesh 抽象表示。
-
Placements 是指表示张量在不同设备上的切分状态,分为 Replicate、Shard 和 Partial 这3种切分状态。如下图所示,Replicate 表示张量在不同设备上会以复制的形式存在;Shard 表示按照特定的维度在不同设备上进行切分;Partial 表示设备上的张量不完整,需要进行 Reduce Sum 或者 Reduce Mean 等不同方式的操作后,才能得到完整的状态。
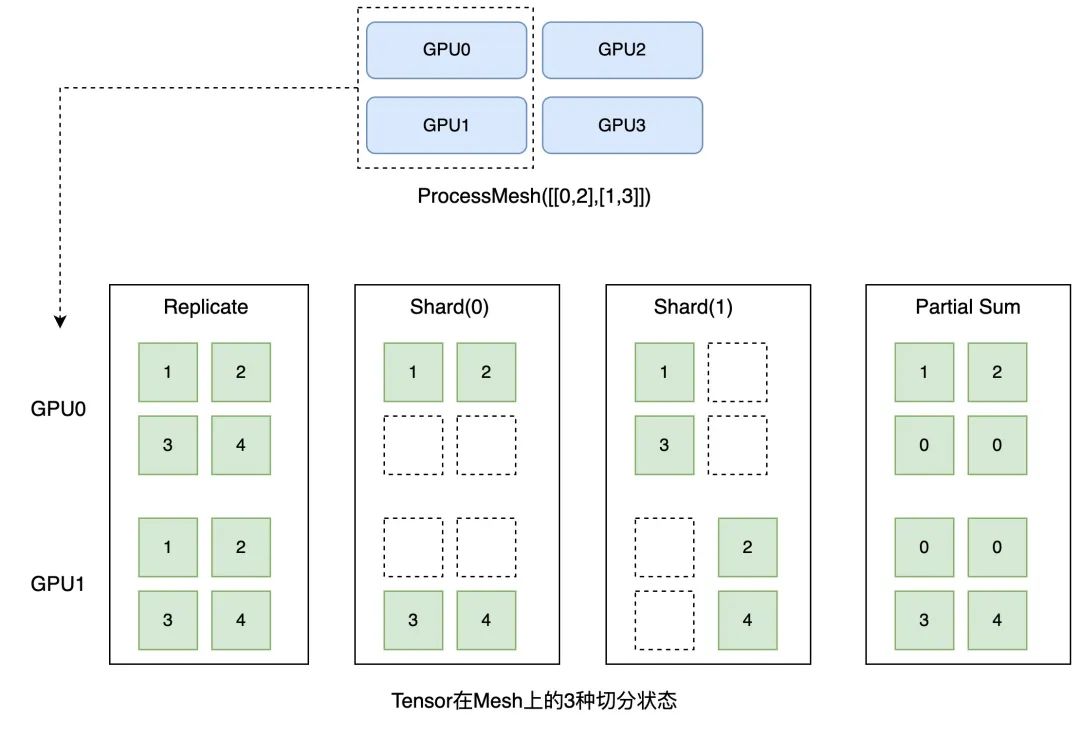
我们用一个例子来说明ProcessMesh和Placements的语义和用法
例如,我们希望在6个计算设备上,创建一个形状为(4, 3)的分布式张量,其中沿着计算设备的 x 维,切分张量的0维;沿着计算设备的 y 维上,切分张量的1维。最终,每个计算设备实际拥有大小为(2, 1)的实际张量,如图所示。
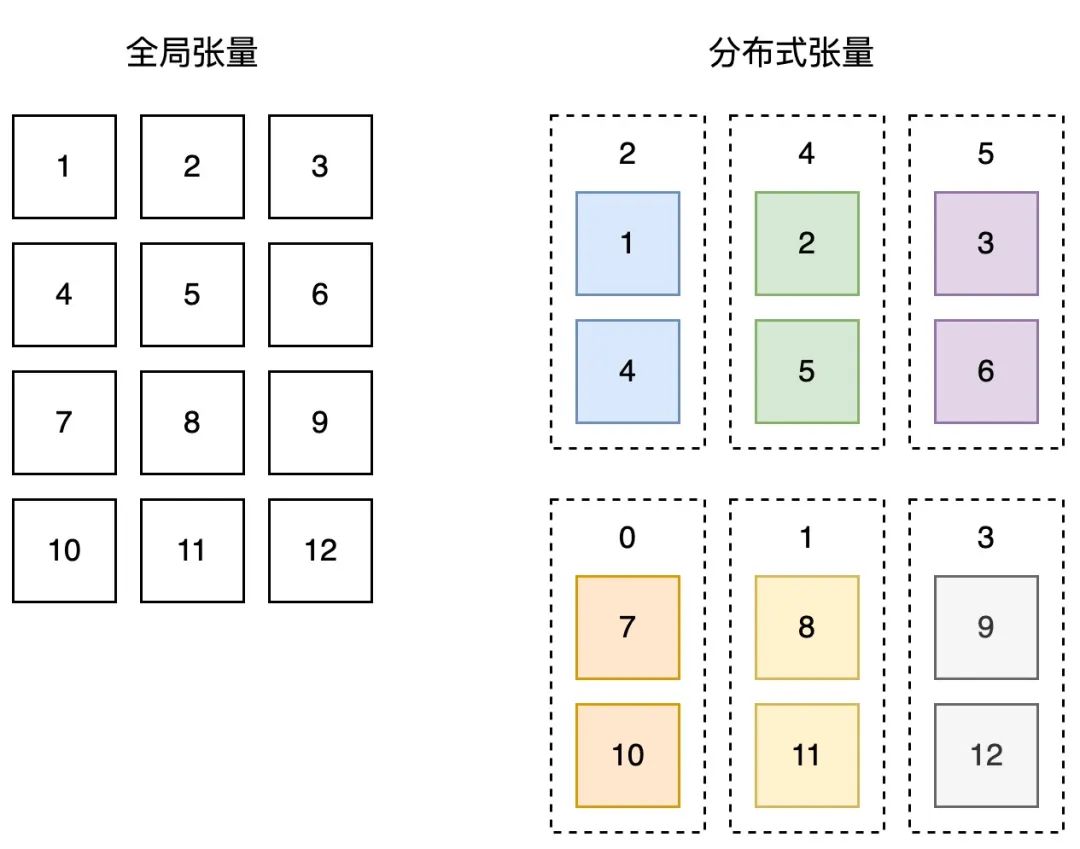
△全局张量和分布式张量
对应的代码如下:
import paddle
import paddle.distributed as dist
mesh = dist.ProcessMesh([[2, 4, 5], [0, 1, 3]], dim_names=['x', 'y'])
dense_tensor = paddle.to_tensor([[1,2,3],
[4,5,6],
[7,8,9],
[10,11,12]])
placements = [dist.Shard(0), dist.Shard(1)]
dist_tensor = dist.shard_tensor(dense_tensor, mesh, placements)
同时,为了提供重切分的能力,我们提供 paddle.distributed.reshard 接口,支持跨 ProcessMesh 的分布式张量转换。
例如,我们可以把在[0, 1] 两个设备上状态为 Replicate 的分布式张量,转换到 [2, 3] 这两个设备上,并变成状态为 Shard 的分布式张量。
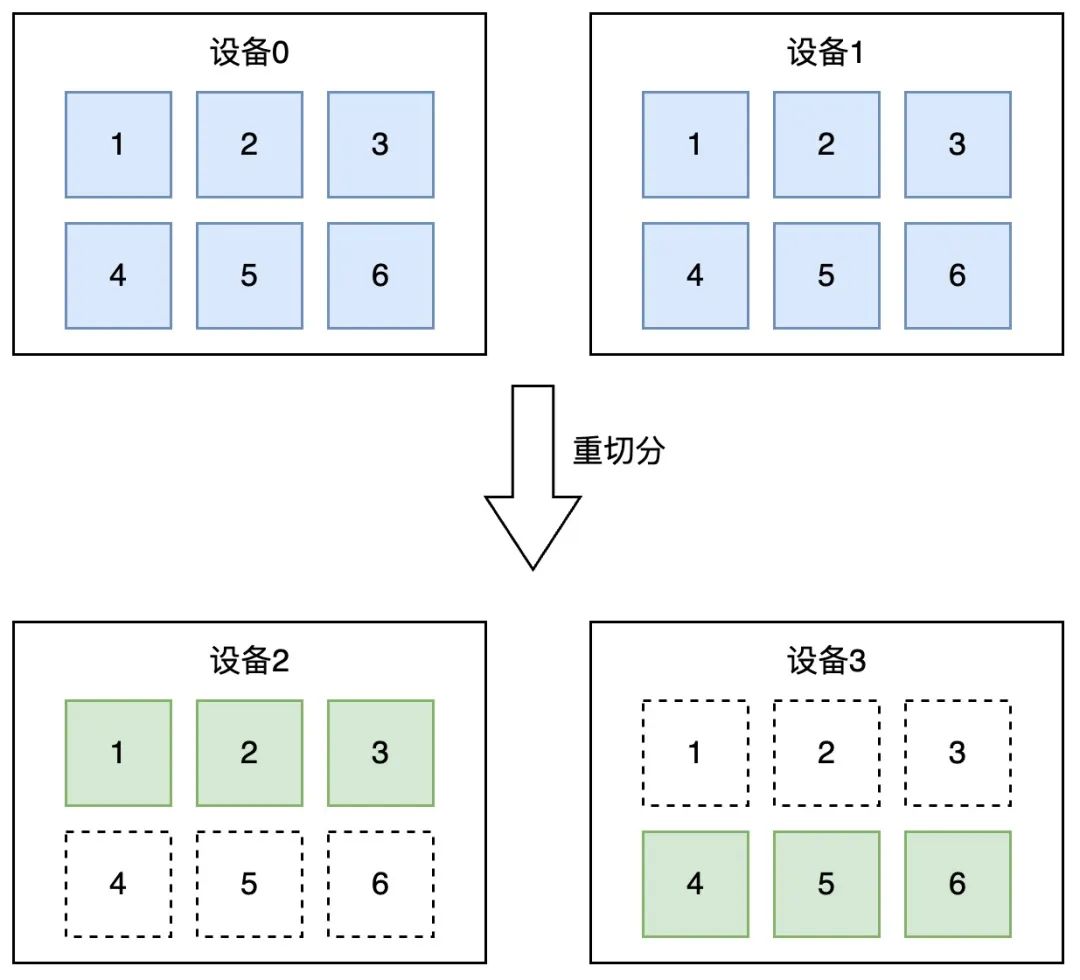
△张量重切分示意
其对应的代码如下:
import paddle
import paddle.distributed as dist
mesh0 = dist.ProcessMesh([0, 1], dim_names=['x'])
mesh1 = dist.ProcessMesh([2, 3], dim_names=['x'])
dense_tensor = paddle.to_tensor([[1,2,3],
[4,5,6]])
placements0 = [dist.Replicate()]
placements1 = [dist.Shard(0)]
dist_tensor = dist.shard_tensor(dense_tensor, mesh0, placements0)
dist_tensor_after_reshard = dist.reshard(dist_tensor, mesh1, placements1)
2.2 自动并行流程
下面我们用一个简单的列子介绍自动并行框架底层的执行流程和原理。
在单卡逻辑视角下我们希望完成计算 C = Matmul(A, B),D = Relu©。假设用户将 TensorB 标记成按列切分,表示在实际分布式集群中 TensorB 被按行切分到不同的 Devices 上。将 TensorA 标记成复制,表示所有 Devices 上都有完整 TensorA 副本。
import paddle
import paddle.distributed as dist
mesh = dist.ProcessMesh([0, 1], dim_names=['x'])
dense_tensorA = paddle.to_tensor([[1,2,], [3,4]])
dense_tensorB = paddle.to_tensor([[5,6], [7,8]])
placementsA = [dist.Replicate()]
placementsB = [dist.Shard(0)]
dist_tensorA = dist.shard_tensor(dense_tensorA, mesh, placementsA)
dist_tensorB = dist.shard_tensor(dense_tensorB, mesh, placementsB)
dist_tensorC = Matmul(dist_tensorA, dist_tensorB)
dist_tensorD = relu(dist_tensorC)
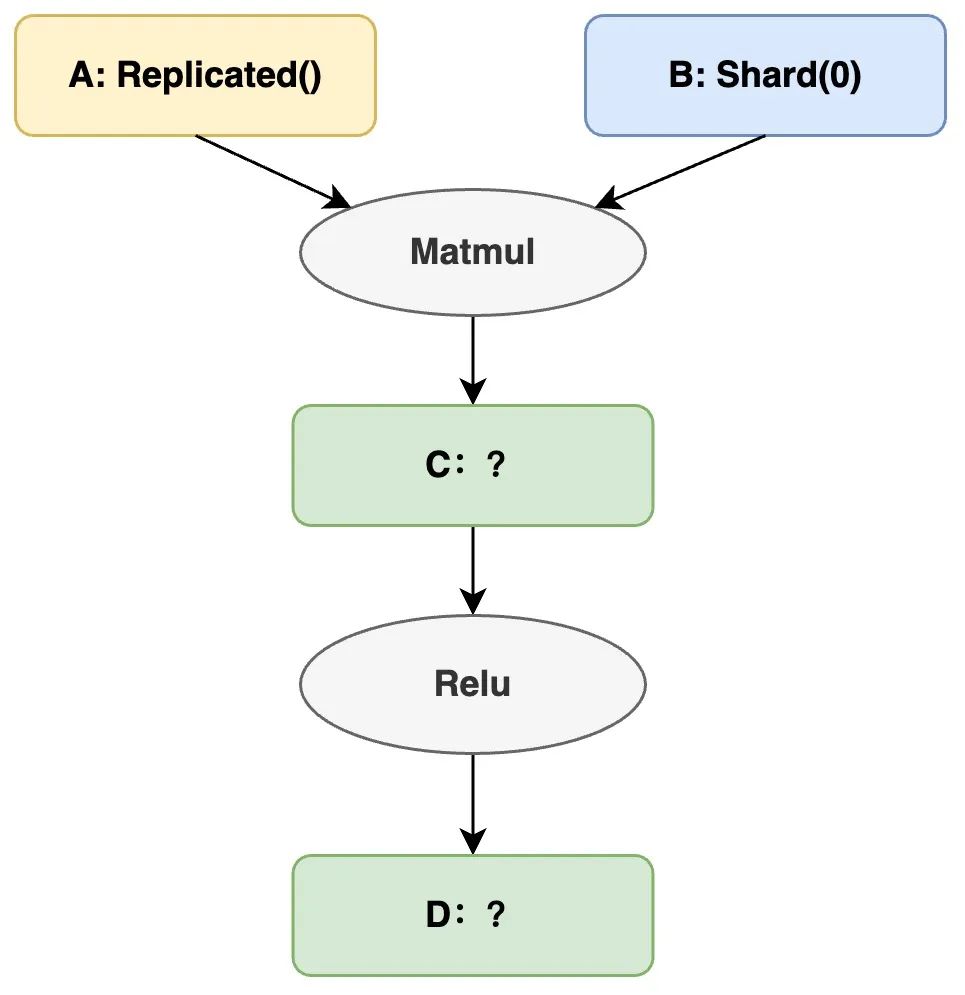
△切分推导之前:C 和 D 的切分状态未知
接下来就会进入自动并行的第一个核心逻辑 切分推导(InferSPMD)。当前用户标记的输入切分状态是无法被 Matmul 算子实际计算的(TensorA 的第0维和 TensorB 的第1维不匹配)。这时候自动并行框架会使用当前算子的切分推导规则(e.g. MatmulSPMD Rule),根据输入 tensors 的切分状态,推导出一套合法且性能较优的 输入-输出 张量的切分状态。
在上述输入的切分状态下,框架会推导出 TensorA 的需要按列切分,TensorB 保持切分状态不变,Matmul 的计算结果 TensorC 的切分状态是 Partial。因为后续的 Relu 算子是非线性的,输入不能是 Partial 状态,所以框架会根据 ReluSPMD Rule 将 TensorC 输入 Relu 前的的分布式状态推导成 Replicated。
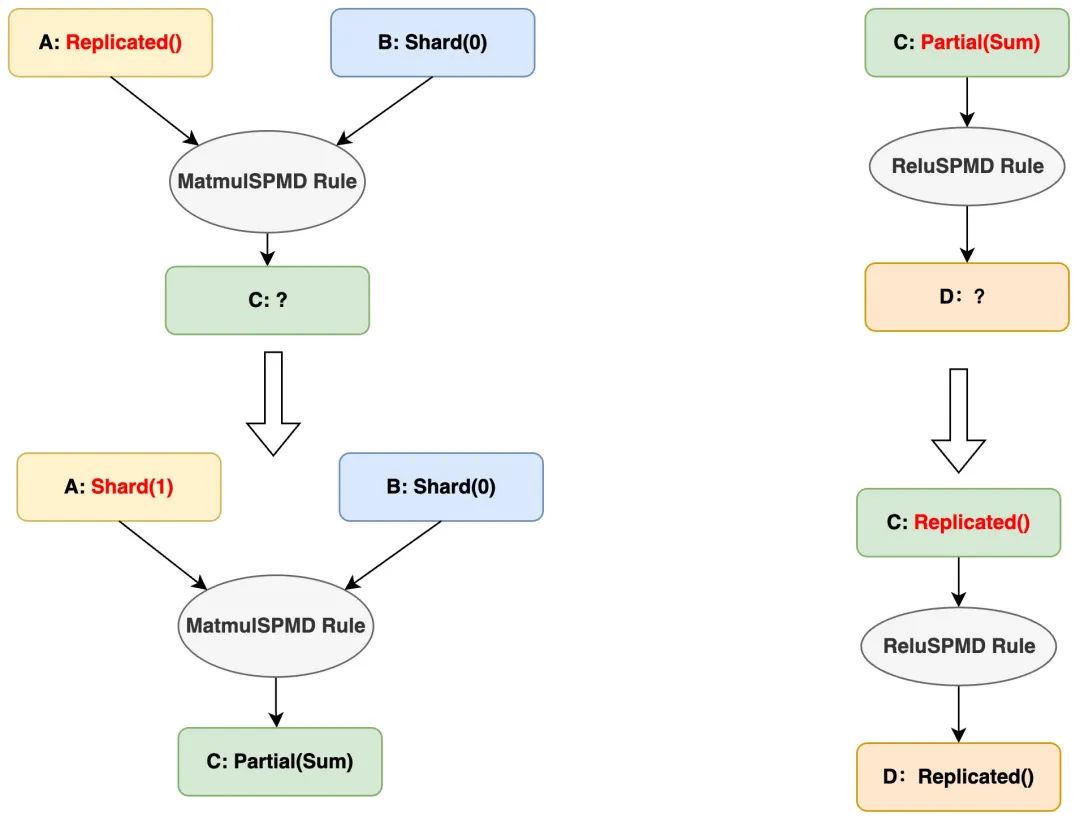
△切分推导之后:C 和 D 的切分状态已知
接下来将就会进入自动并行的第二个核心逻辑切分转换。框架会根据tensor当前的切分状态(src_placement),和切分推导规则推导出的算子计算需要的切分状态(src_placement),添加对应的通信/张量维度变换算子。根据上图的切分推导,在计算Matmul添加split算子,在计算Relu添加Allreduce,将输入tensor转换成需要的切分状态进行实际计算。
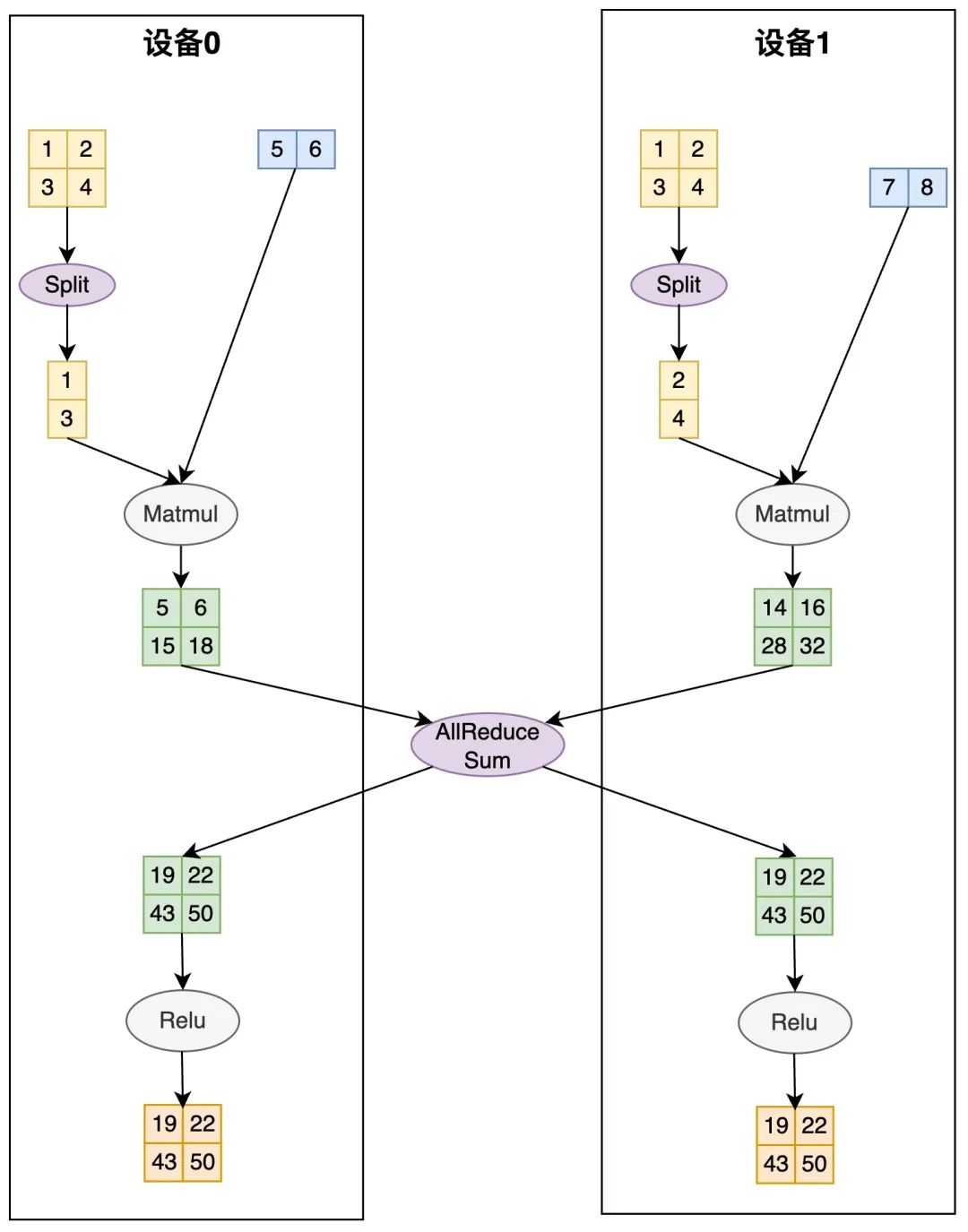
△切分转换:执行合适的通信操作
2.3 动静统一执行
动态图和静态图是框架的两种执行模式,动态图方便用户调试和开发,可以即时得到执行结果,静态图会做性能优化和调度编排,将硬件资源用到极致,为了兼备两者的优点,我们提供动转静机制,支持用户在动态图上开发调试后,转成静态图执行。
**自动并行的 API 在设计之初,就以实现统一的用户标记接口和逻辑为目标,保证动静半框架保证在相同的用户标记下,动静态图分布式执行逻辑一致。这样用户在全流程过程中只需要标记一套动态图组网,即可以实现动态图下的分布式训练 Debug 和 静态图下的分布式推理等逻辑。**整个动转静训练的逻辑如下:
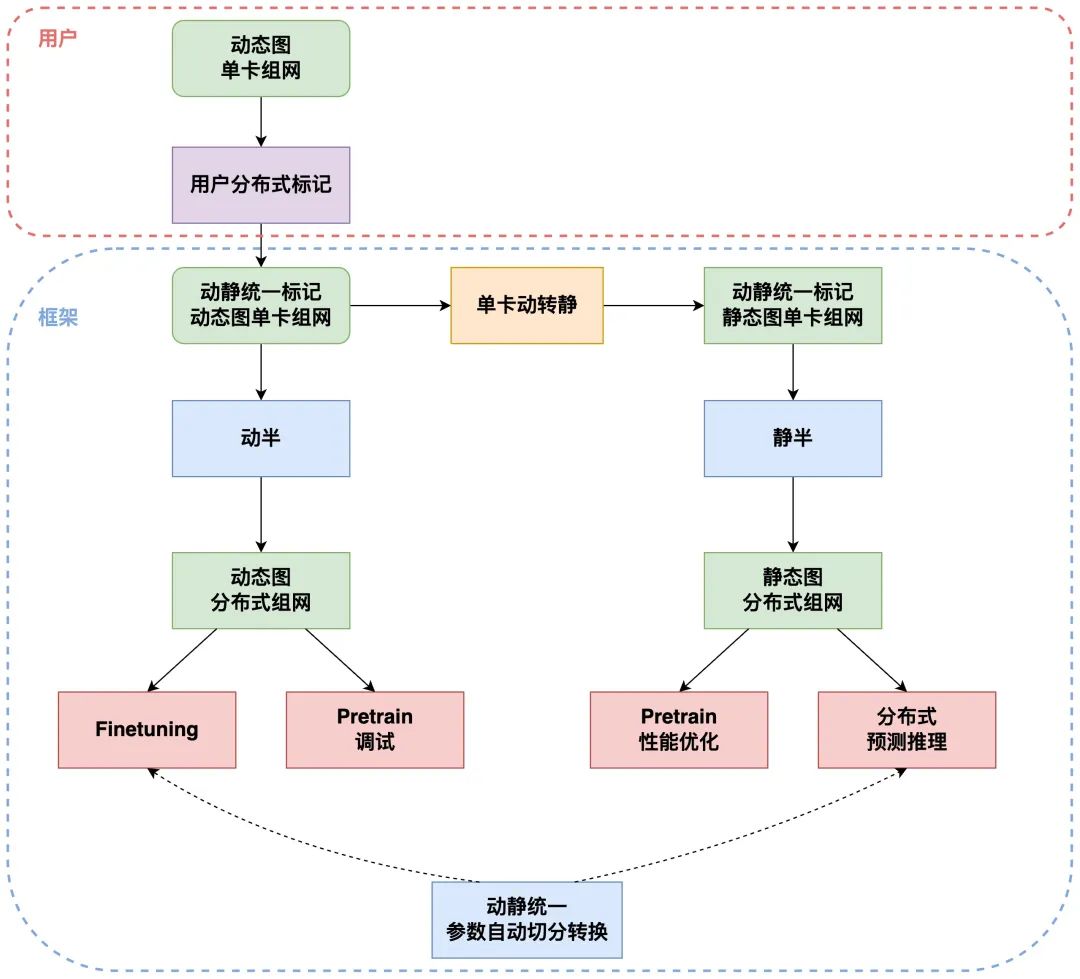
△动静统一
... # 动态图组网
# 动转静训练
dist_model = dist.to_static(
model, dataloader, paddle.mean, opt
)
dist_model.train()
for step, inputs in enumerate(dataloader()):
data = inputs
loss = dist_model(data)
print(step, loss)
03 混合并行实践
基于上述介绍的框架,飞桨框架3.0自动并行已经能够实现大模型训练过程中常用的并行策略。
下面是一个完整的包含数据并行、张量并行、流水并行三种策略的示例。计算设备一共有8张 GPU 卡,编号分别为0-7,他们组成两个 ProcessMesh,分布为[[0,1],[2,3]]和[[4,5],[6,7]]。模型由两个 matmul 算子组成,两个 matmul 分别在 两个不同的 mesh 上,中间结果需要跨 mesh 传输,做流水线并行;输入数据在 ProcessMesh 的0维被切分,做数据并行;两个 matmul 的参数在 ProcessMesh 的 1 维上分别被按列或按行切分,做张量模型并行。如下图所示:
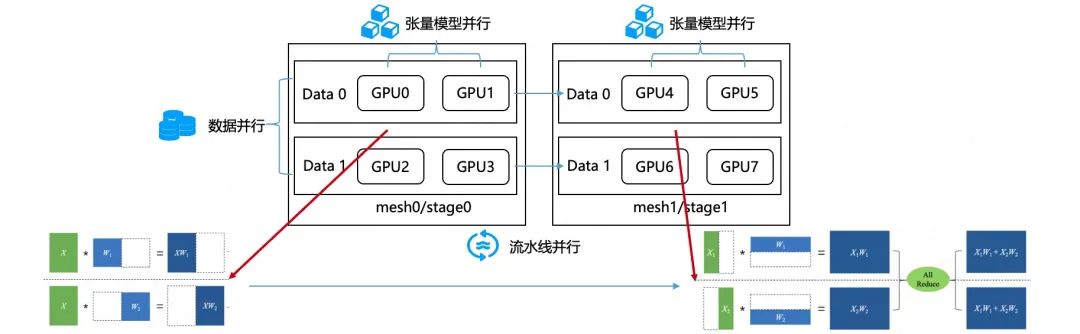
△8卡混合并行示例
按照上面的模型定义,对应的自动并行代码实现如下:
# 启动脚本:
# python3 -m paddle.distributed.launch --device=0,1,2,3,4,5,6,7 train.py
import paddle
import paddle.distributed as dist
from paddle.io import BatchSampler, DataLoader, Dataset
import numpy as np
mesh0 = dist.ProcessMesh([[0, 1], [2, 3]], dim_names=['x', 'y']) # 创建进程网格
mesh1 = dist.ProcessMesh([[4, 5], [6, 7]], dim_names=['x', 'y']) # 创建进程网格
class RandomDataset(Dataset):
def __init__(self, seq_len, hidden, num_samples=100):
super().__init__()
self.seq_len = seq_len
self.hidden = hidden
self.num_samples = num_samples
def __getitem__(self, index):
input = np.random.uniform(size=[self.seq_len, self.hidden]).astype("float32")
label = np.random.uniform(size=[self.seq_len, self.hidden]).astype("float32")
return input, label
def __len__(self):
return self.num_samples
class MlpModel(paddle.nn.Layer):
def __init__(self):
super(MlpModel, self).__init__()
self.w0 = dist.shard_tensor(
self.create_parameter(shape=[1024, 4096]),
mesh0, [dist.Replicate(), dist.Shard(1)]) # 模型并行,列切
self.w1 = dist.shard_tensor(
self.create_parameter(shape=[4096, 1024]),
mesh1, [dist.Replicate(), dist.Shard(0)]) # 模型并行,行切
def forward(self, x):
y = paddle.matmul(x, self.w0)
y = dist.reshard(y, mesh1, [dist.Shard(0), dist.Shard(2)]) #流水线并行
z = paddle.matmul(y, self.w1)
return z
model = MlpModel()
dataset = RandomDataset(128, 1024)
sampler = BatchSampler(
dataset,
batch_size=2,
)
dataloader = DataLoader(
dataset,
batch_sampler=sampler,
)
dataloader = dist.shard_dataloader(dataloader, meshes=[mesh0, mesh1], shard_dims='x')
opt = paddle.optimizer.AdamW(learning_rate=0.001, parameters=model.parameters())
opt = dist.shard_optimizer(opt)
for step, inputs in enumerate(dataloader()):
data = inputs[0]
logits = model(data)
loss = paddle.mean(logits)
loss.backward()
opt.step()
opt.clear_grad()
04 分布式性能优化
在实际的大模型业务训练中,训练吞吐是一个非常重要的指标。飞桨框架3.0支持在动态图自动并行转为静态图自动并行执行,并自动添加多种性能优化策略,支持计算图全局优化,这也是飞桨框架3.0动静统一自动并行的一大特色。自动并行内置实现了多种性能优化策略,包括:算子融合优化、流水线编排调度方式、高效-计算Overlap、通信融合优化等,用于来提升分布式训练吞吐。**用户在可以通过简单的以下接口中配置相关选项,即可开启静动态图自动并行性能优化策略:**paddle.distributed.Strategy。
4.1 算子融合优化
例如,在常见的大语言模型中,matmul 和 add 可以进行算子融合 fusion,减少中间变量的访存开销。在自动并行模式下,可以通过如下代码进行开启:
import paddle
import paddle.distributed as dist
strategy = dist.Strategy()
strategy.fused_passes.enable = True
strategy.fused_passes.gemm_epilogue = True
4.2 流水线并行优化
比如在流水线并行下,通过 strategy 设置1F1B 和 virtual-pipeline 的调度方式可以实现的 interleaved 流水线编排调度,减少流水线执行时的 bubble 开销。
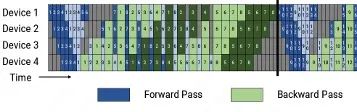
△Interleaved 流水线调度图
from paddle.distributed as dist
strategy = dist.Strategy()
pipeline = strategy.pipeline
pipeline.enable = True
pipeline.schedule_mode = "1F1B" # 1F1B or F-then-B
pipeline.vpp_degree = 2
05 总结
飞桨框架3.0版本下,通过采用自动并行的开发方式,开发者无需再考虑复杂的通信逻辑。开发者无需深入研究手动并行编程的复杂概念和 API,只需进行少量的张量切分标注,即可完成混合并行模型的构建。其分布式训练核心代码量减少了 50%,从而大大降低了开发的难度!
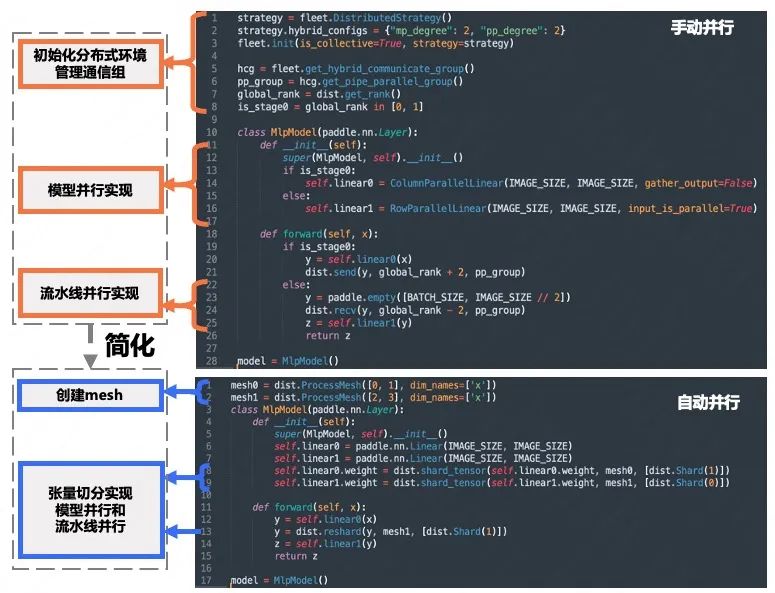
△手动并行和自动并行代码对比
飞桨框架3.0向用户提供了一种动静统一的大模型开发范式,在动态图自动并行上,用户可以方便的打印中间结果调试验证自己的算法模型;调试完成后,通过飞桨框架3.0动转静机制将模型转成静态图,静态图自动并行框架会应用各种分布式优化 Pass 策略,提升模型分布式训练吞吐。
未来,我们将进一步探索和开发无需用户进行张量切分标记的自动并行高阶 API 接口,让开发者可以像单卡训练一样只需要关心模型算法,并通过一个简单的接口自动实现大模型分布式训练,进一步提升大模型的开发体验。
————END————
推荐阅读
















 1320
1320

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









