







1,虚拟机准备:
vmware基于CentOS Linux release 7.9.2009 (Core)搭建三台虚拟机 内核与操作系统版本号:

192.168.1.2/192.168.1.3/192.168.1.4
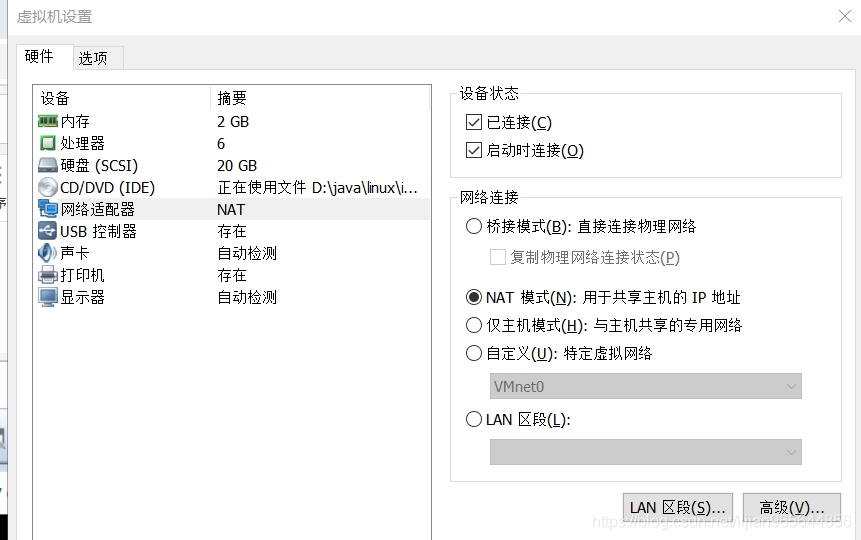
配置本地虚拟机可以上网:
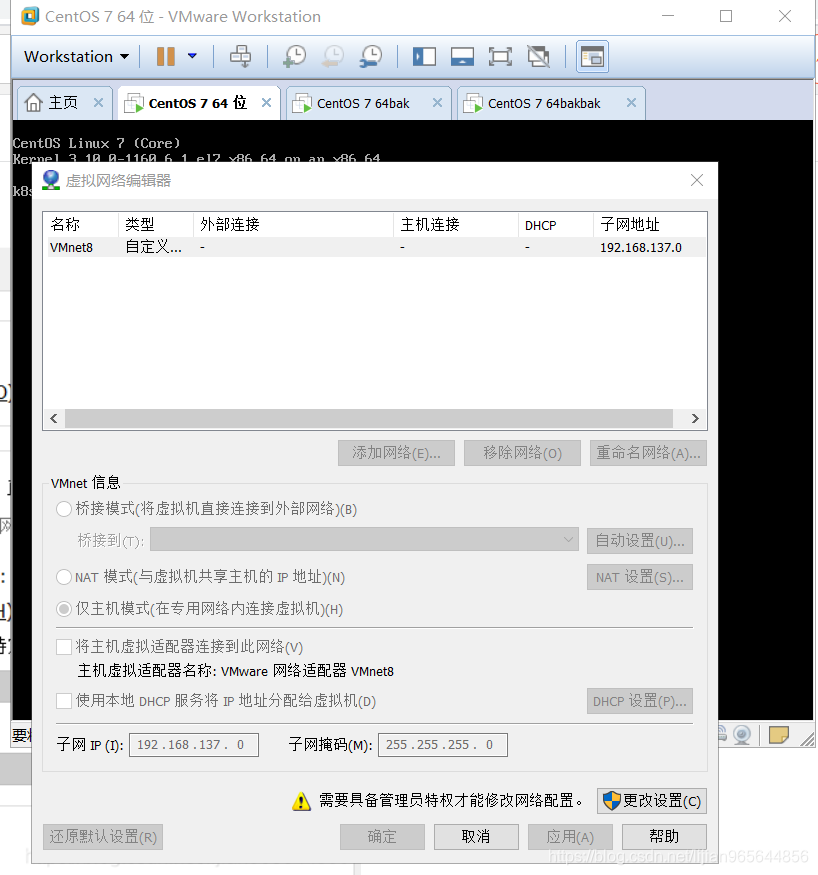
三台机器的网卡配置分别如下
| 192.168.1.2 | 192.168.1.3 | 192.168.1.4 |
 |  | 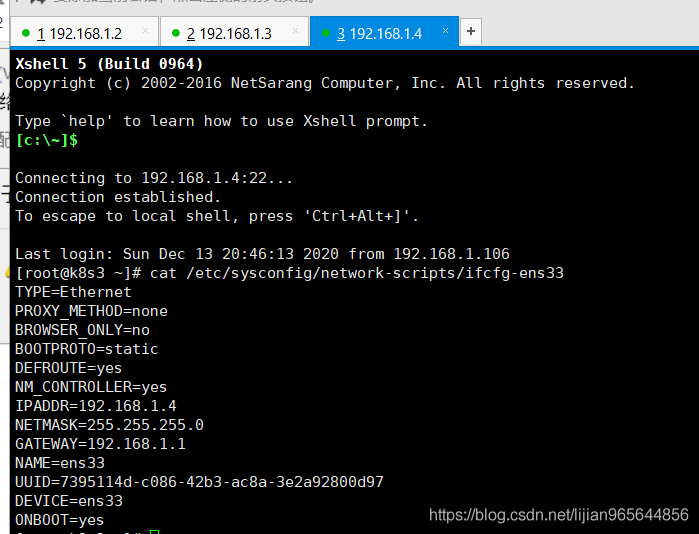 |
配置完后重启网络 systemctl restart network.service
dns解析:

网络配置好后 测试是否可以连上互联网,首先要保证物理机的网络是ok
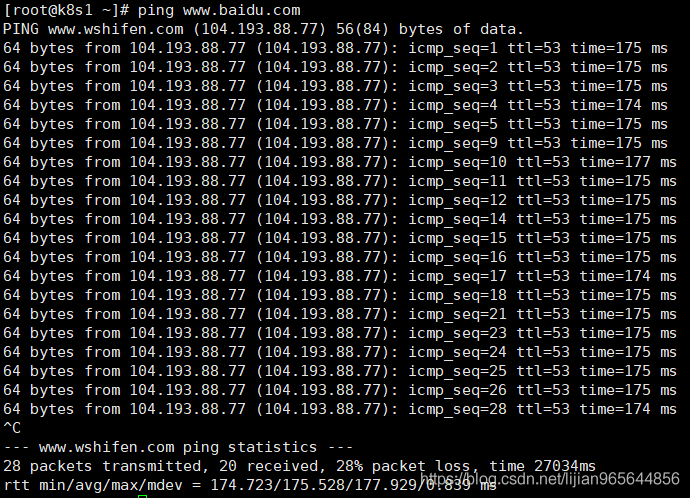
以上说明网络配置ok 剩下可以参考配置ssh免登陆等。 主要方便三台机器之间传文件,也可以不配置
配置hosts

1,配置免登陆192.168.1.2上可以免登陆到192.168.1.3/192.168.1.4
--192.168.1.2上执行以下命令生成公钥
mkdir -p ~/.ssh
cd /root/.ssh/
pwd
ssh-keygen -t rsa
vi /etc/ssh/ssh_config
scp id_rsa.pub root@192.168.1.3:/tmp/
ssh 192.168.1.3
systemctl restart sshd
2,关闭防火墙 --------三台节点都要执行
先查看防火墙是否关闭:
firewall-cmd --get-default-zone
--若未关闭 关闭防火墙执行以下命令
systemctl status firewalld
systemctl stop firewalld
3,永久关闭selunix--------三台节点都要执行
sed -i 's/enforcing/disabled/' /etc/selinux/config # 永久
setenforce 0 # 临时
sed -i '/^SELINUX=/c\SELINUX=disabled' /etc/selinux/config 永久
4, 永久关闭swap
第一步 关闭swap分区:
swapoff -a
第二步修改配置文件 vi /etc/fstab
删除swap相关行 /mnt/swap swap swap defaults 0 0 这一行或者注释掉这一行
第三步确认swap已经关闭
free -m![]()
若swap行都显示 0 则表示关闭成功
第四步调整 swappiness 参数
echo 0 > /proc/sys/vm/swappiness # 临时生效
vim /etc/sysctl.conf # 永久生效
#修改 vm.swappiness 的修改为 0
vm.swappiness=0
sysctl -p # 使配置生效
为了避免服务器使用swap功能而影响服务器性能,一般都会把vm.swappiness修改为0,在Centos 6上,直接修改: /etc/sysctl.conf ,添加一条: vm.swappiness = 0,即可保证开机后自动生效。使用命令:sysctl -p 可以立即生效。但在Centos 7.2上,通过修改/etc/sysctl.conf 文件,无法使该配置永久生效。查到造成该问题的原因是,存在其他配置文件晚于sysctl.conf读取并执行。貌似Centos 7.0不会有这个问题,以下是解决方法:
sed -i "s|vm.swappiness=10|vm.swappiness=0|" /usr/lib/tuned/latency-performance/tuned.conf
sed -i "s|vm.swappiness=10|vm.swappiness=0|" /usr/lib/tuned/throughput-performance/tuned.conf
sed -i "s|vm.swappiness=30|vm.swappiness=0|" /usr/lib/tuned/throughput-performance/tuned.conf
5,时间同步----------三台节点都要执行
yum install -y ntpdate
timedatectl set-timezone Asia/Shanghai
说明:
如果时间不同步 对节点加入集群有影响
向集群添加新节点,执行在kubeadm init输出的kubeadm join命令:
复制上面命令,在node节点上执行
| 1 2 |
|
如果一直卡在 “Running pre-flight checks” 上,则很可能是时间未同步,token失效导致
第一步,检查master、node时间是否同步?
$ date
执行如下命令同步时间
$ ntpdate time.nist.gov
6.将桥接的IPV4流量传递到iptables的链
cat > /etc/sysctl.d/k8s.conf << EOF
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
EOF
sysctl --system
2,基于yum源安装docker19.03---注意基于kubeadm安装k8s需要docker环境
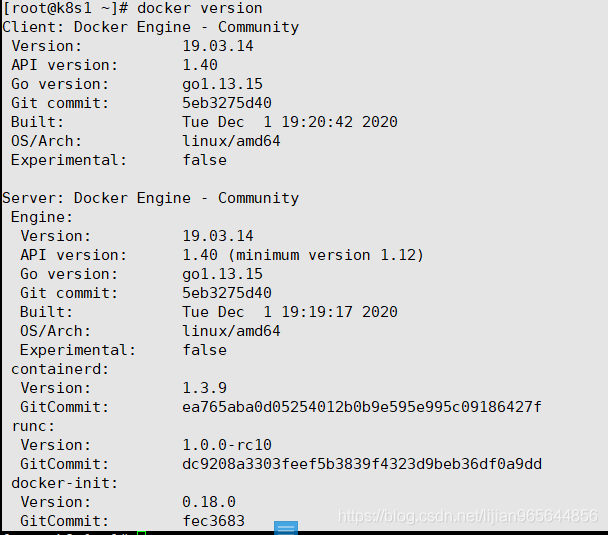
已安装docker的虚拟机 需要先卸载:
yum remove docker docker-common docker-selinux docker-engine
添加docker源
yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo
安装工具
yum install -y yum-utils device-mapper-persistent-data lvm2 ---这些跟docker有关 其它可以不用装 但是建议最好装上
yum install -y nc
yum install -y telnet
yum install -y epel-release
yum install -y pssh
配置自动补全功能:
yum install -y bash-completion
[root@k8s1 k8s]# source <(kubectl completion bash)
[root@k8s1 k8s]# echo "source <(kubectl completion bash)" >> ~/.bashrc
[root@k8s1 k8s]# source ~/.bashrc
查找可以安装的docker版本
yum list docker-ce --showduplicates | sort -r
执行安装命令
yum install -y docker-ce docker-ce-cli containerd.io
systemctl enable docker.service
systemctl start docker.service
docker ps
查看docker版本
docker version
--配置可用docker仓库 如阿里云仓库
cat > /etc/docker/daemon.json << EOF
{
"registry-mirrors": ["https://registry.aliyuncs.com"],
"exec-opts": ["native.cgroupdriver=systemd"]
}
EOF
执行以下命令使之生效
systemctl daemon-reload
systemctl restart docker
3,部署kubernates
添加阿里云yum源软件源
cd /etc/yum.repos.d/
ll
touch kubernetes.repo
vi kubernetes.repo
[root@k8s1 yum.repos.d]# cat kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=1
repo_gpgcheck=1
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
1,安装最新版本kubeadm
yum install -y kubeadm
systemctl enable kubelet
执行 kubectl version 出现以下问题 ---如果镜像
Client Version: version.Info{Major:"1", Minor:"19", GitVersion:"v1.19.4", GitCommit:"d360454c9bcd1634cf4cc52d1867af5491dc9c5f", GitTreeState:"clean", BuildDate:"2020-11-11T13:17:17Z", GoVersion:"go1.15.2", Compiler:"gc", Platform:"linux/amd64"}
The connection to the server localhost:8080 was refused - did you specify the right host or port?
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 11m default-scheduler Successfully assigned default/nginx-deployment-585449566-znzt2 to k8s2
Warning FailedCreatePodSandBox 16s (x17 over 11m) kubelet Failed to create pod sandbox: rpc error: code = Unknown desc = failed pulling image "k8s.gcr.io/pause:3.2": Error response from daemon: Get https://k8s.gcr.io/v2/: net/http: request canceled while waiting for connection (Client.Timeout exceeded while awaiting headers)
failed pulling image "k8s.gcr.io/pause:3.2解决:
下载pause镜像即可
docker pull registry.aliyuncs.com/google_containers/pause:3.2
docker tag registry.aliyuncs.com/google_containers/pause:3.2 k8s.gcr.io/pause:3.2
docker rmi registry.aliyuncs.com/google_containers/pause:3.2
在master节点装备镜像:
列出需要下载的镜像
[root@k8s1 yum.repos.d]# kubeadm config images list
I0117 23:37:45.235445 62344 version.go:252] remote version is much newer: v1.20.2; falling back to: stable-1.19
W0117 23:37:46.693466 62344 configset.go:348] WARNING: kubeadm cannot validate component configs for API groups [kubelet.config.k8s.io kubeproxy.config.k8s.io]
k8s.gcr.io/kube-apiserver:v1.19.7
k8s.gcr.io/kube-controller-manager:v1.19.7
k8s.gcr.io/kube-scheduler:v1.19.7
k8s.gcr.io/kube-proxy:v1.19.7
k8s.gcr.io/pause:3.2
k8s.gcr.io/etcd:3.4.13-0
k8s.gcr.io/coredns:1.7.0
以上镜像是安装集群需要的镜像
执行以下命令从阿里云拉取镜像然后重新tag
docker pull registry.aliyuncs.com/google_containers/kube-apiserver:v1.19.4
docker tag registry.aliyuncs.com/google_containers/kube-apiserver:v1.19.4 k8s.gcr.io/kube-apiserver:v1.19.4
docker rmi registry.aliyuncs.com/google_containers/kube-apiserver:v1.19.4
docker pull registry.aliyuncs.com/google_containers/kube-controller-manager:v1.19.4
docker tag registry.aliyuncs.com/google_containers/kube-controller-manager:v1.19.4 k8s.gcr.io/kube-controller-manager:v1.19.4
docker rmi registry.aliyuncs.com/google_containers/kube-controller-manager:v1.19.4
docker pull registry.aliyuncs.com/google_containers/kube-scheduler:v1.19.4
docker tag registry.aliyuncs.com/google_containers/kube-scheduler:v1.19.4 k8s.gcr.io/kube-scheduler:v1.19.4
docker rmi registry.aliyuncs.com/google_containers/kube-scheduler:v1.19.4
docker pull registry.aliyuncs.com/google_containers/kube-proxy:v1.19.4
docker tag registry.aliyuncs.com/google_containers/kube-proxy:v1.19.4 k8s.gcr.io/kube-proxy:v1.19.4
docker rmi registry.aliyuncs.com/google_containers/kube-proxy:v1.19.4
docker pull registry.aliyuncs.com/google_containers/etcd:3.4.13-0
docker tag registry.aliyuncs.com/google_containers/etcd:3.4.13-0 k8s.gcr.io/etcd:3.4.13-0
docker rmi registry.aliyuncs.com/google_containers/etcd:3.4.13-0
已安装 无需重复安装
docker pull registry.aliyuncs.com/google_containers/pause:3.2
docker tag registry.aliyuncs.com/google_containers/pause:3.2 k8s.gcr.io/pause:3.2
docker rmi registry.aliyuncs.com/google_containers/pause:3.2
docker pull coredns/coredns:1.7.0
docker tag coredns/coredns:1.7.0 k8s.gcr.io/coredns:1.7.0
docker rmi coredns/coredns:1.7.0
最终安装的镜像:
[root@k8s1 yum.repos.d]# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
quay.io/coreos/flannel v0.13.1-rc1 f03a23d55e57 8 weeks ago 64.6MB
k8s.gcr.io/kube-proxy v1.19.4 635b36f4d89f 2 months ago 118MB
k8s.gcr.io/kube-controller-manager v1.19.4 4830ab618586 2 months ago 111MB
k8s.gcr.io/kube-apiserver v1.19.4 b15c6247777d 2 months ago 119MB
k8s.gcr.io/kube-scheduler v1.19.4 14cd22f7abe7 2 months ago 45.7MB
k8s.gcr.io/etcd 3.4.13-0 0369cf4303ff 4 months ago 253MB
k8s.gcr.io/coredns 1.7.0 bfe3a36ebd25 7 months ago 45.2MB
k8s.gcr.io/pause 3.2 80d28bedfe5d 11 months ago 683kB
2,部署kubernates master 在192.168.1.2机器上
[root@k8s1 ~]# kubeadm init --kubernetes-version=1.19.4 \
--apiserver-advertise-address=192.168.1.2 \
--service-cidr=10.1.0.0/16 \
--pod-network-cidr=10.244.0.0/16
执行以以上命令即可,下面是输出的日志
W1211 07:07:37.291864 8493 configset.go:348] WARNING: kubeadm cannot validate component configs for API groups [kubelet.config.k8s.io kubeproxy.config.k8s.io]
[init] Using Kubernetes version: v1.19.4
[preflight] Running pre-flight checks
[WARNING Firewalld]: firewalld is active, please ensure ports [6443 10250] are open or your cluster may not function correctly
[preflight] Pulling images required for setting up a Kubernetes cluster
[preflight] This might take a minute or two, depending on the speed of your internet connection
[preflight] You can also perform this action in beforehand using 'kubeadm config images pull'
[certs] Using certificateDir folder "/etc/kubernetes/pki"
[certs] Generating "ca" certificate and key
[certs] Generating "apiserver" certificate and key
[certs] apiserver serving cert is signed for DNS names [k8s1 kubernetes kubernetes.default kubernetes.default.svc kubernetes.default.svc.cluster.local] and IPs [10.1.0.1 192.168.1.2]
[certs] Generating "apiserver-kubelet-client" certificate and key
[certs] Generating "front-proxy-ca" certificate and key
[certs] Generating "front-proxy-client" certificate and key
[certs] Generating "etcd/ca" certificate and key
[certs] Generating "etcd/server" certificate and key
[certs] etcd/server serving cert is signed for DNS names [k8s1 localhost] and IPs [192.168.1.2 127.0.0.1 ::1]
[certs] Generating "etcd/peer" certificate and key
[certs] etcd/peer serving cert is signed for DNS names [k8s1 localhost] and IPs [192.168.1.2 127.0.0.1 ::1]
[certs] Generating "etcd/healthcheck-client" certificate and key
[certs] Generating "apiserver-etcd-client" certificate and key
[certs] Generating "sa" key and public key
[kubeconfig] Using kubeconfig folder "/etc/kubernetes"
[kubeconfig] Writing "admin.conf" kubeconfig file
[kubeconfig] Writing "kubelet.conf" kubeconfig file
[kubeconfig] Writing "controller-manager.conf" kubeconfig file
[kubeconfig] Writing "scheduler.conf" kubeconfig file
[kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env"
[kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"
[kubelet-start] Starting the kubelet
[control-plane] Using manifest folder "/etc/kubernetes/manifests"
[control-plane] Creating static Pod manifest for "kube-apiserver"
[control-plane] Creating static Pod manifest for "kube-controller-manager"
[control-plane] Creating static Pod manifest for "kube-scheduler"
[etcd] Creating static Pod manifest for local etcd in "/etc/kubernetes/manifests"
[wait-control-plane] Waiting for the kubelet to boot up the control plane as static Pods from directory "/etc/kubernetes/manifests". This can take up to 4m0s
[apiclient] All control plane components are healthy after 23.003079 seconds
[upload-config] Storing the configuration used in ConfigMap "kubeadm-config" in the "kube-system" Namespace
[kubelet] Creating a ConfigMap "kubelet-config-1.19" in namespace kube-system with the configuration for the kubelets in the cluster
[upload-certs] Skipping phase. Please see --upload-certs
[mark-control-plane] Marking the node k8s1 as control-plane by adding the label "node-role.kubernetes.io/master=''"
[mark-control-plane] Marking the node k8s1 as control-plane by adding the taints [node-role.kubernetes.io/master:NoSchedule]
[bootstrap-token] Using token: h7w984.ue6pfb76adusr96w
[bootstrap-token] Configuring bootstrap tokens, cluster-info ConfigMap, RBAC Roles
[bootstrap-token] configured RBAC rules to allow Node Bootstrap tokens to get nodes
[bootstrap-token] configured RBAC rules to allow Node Bootstrap tokens to post CSRs in order for nodes to get long term certificate credentials
[bootstrap-token] configured RBAC rules to allow the csrapprover controller automatically approve CSRs from a Node Bootstrap Token
[bootstrap-token] configured RBAC rules to allow certificate rotation for all node client certificates in the cluster
[bootstrap-token] Creating the "cluster-info" ConfigMap in the "kube-public" namespace
[kubelet-finalize] Updating "/etc/kubernetes/kubelet.conf" to point to a rotatable kubelet client certificate and key
[addons] Applied essential addon: CoreDNS
[addons] Applied essential addon: kube-proxy
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 192.168.1.2:6443 --token h7w984.ue6pfb76adusr96w \
--discovery-token-ca-cert-hash sha256:7b9a74e9385c51d9fa668b9e2ee6366a4f889c28e77c66799077f71007a4c6b8
----这个打印的命令 即是告诉你如何向集群加入节点 需要记录保存下来 以便在192.168.1.3/4上执行
配置集群网络:
#配置flannel网络
#mkdir -p /root/k8s/
#cd /root/k8s
#wget https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
查看需要下载的镜像 # cat kube-flannel.yml |grep image|uniq image: quay.io/coreos/flannel:v0.13.1-rc1
下载镜像 # docker pull quay.io/coreos/flannel:v0.13.1-rc1
部署插件 # kubectl apply -f kube-flannel.yml
注意:如果 https://raw.githubusercontent.com 不能访问请使用: # 打开https://site.ip138.com/raw.Githubusercontent.com/ 输入raw.githubusercontent.com 查询IP地址
[root@k8s1 k8s]# docker pull quay.io/coreos/flannel:v0.13.1-rc1
v0.13.1-rc1: Pulling from coreos/flannel
188c0c94c7c5: Pull complete
4d430ab921ef: Pull complete
4cdde2013a57: Pull complete
49c449f64b3d: Pull complete
e430ae3379b9: Pull complete
08c896b13a43: Pull complete
c6ceff7c139b: Pull complete
Digest: sha256:51223d328b2f85d8fe9ad35db82d564b45b03fd1002728efcf14011aff02de78
Status: Downloaded newer image for quay.io/coreos/flannel:v0.13.1-rc1
quay.io/coreos/flannel:v0.13.1-rc1
[root@k8s1 k8s]# kubectl apply -f kube-flannel.yml
podsecuritypolicy.policy/psp.flannel.unprivileged created
clusterrole.rbac.authorization.k8s.io/flannel created
clusterrolebinding.rbac.authorization.k8s.io/flannel created
serviceaccount/flannel created
configmap/kube-flannel-cfg created
daemonset.apps/kube-flannel-ds created
在master节点配置kubectl生效
echo “export KUBECONFIG=/etc/kubernetes/admin.conf” >> ~/.bash_profile
source ~/.bash_profile
在worker节点配置kubectl生效
k8s集群在节点运行kubectl出现的错误:The connection to the server localhost:8080 was refused - did you specify the right host or port?
将主节点(master节点)中的【/etc/kubernetes/admin.conf】文件拷贝到从节点相同目录下:
scp -r /etc/kubernetes/admin.conf ${node1}:/etc/kubernetes/admin.conf
配置环境变量:
export KUBECONFIG=/etc/kubernetes/admin.conf
查看mater节点各组件状态:kubectl get cs
出现以下即为ok
[root@k8s1 yum.repos.d]# kubectl get cs
Warning: v1 ComponentStatus is deprecated in v1.19+
NAME STATUS MESSAGE ERROR
scheduler Healthy ok
controller-manager Healthy ok
etcd-0 Healthy {"health":"true"}
但是在实际执行过程中出现如下:
[root@k8s1 ~]# kubectl get cs
Warning: v1 ComponentStatus is deprecated in v1.19+
NAME STATUS MESSAGE ERROR
controller-manager Unhealthy Get "http://127.0.0.1:10252/healthz": dial tcp 127.0.0.1:10252: connect: connection refused
scheduler Unhealthy Get "http://127.0.0.1:10251/healthz": dial tcp 127.0.0.1:10251: connect: connection refused
etcd-0 Healthy {"health":"true"}
[root@k8s1 ~]# kubectl get pod -n kube-system
NAME READY STATUS RESTARTS AGE
coredns-f9fd979d6-7h8t7 0/1 Running 0 87m
coredns-f9fd979d6-qh7cr 0/1 Running 0 87m
etcd-k8s1 1/1 Running 0 87m
kube-apiserver-k8s1 1/1 Running 0 87m
kube-controller-manager-k8s1 1/1 Running 0 87m
kube-flannel-ds-ml644 1/1 Running 0 14m
kube-proxy-xmb4z 1/1 Running 0 87m
kube-scheduler-k8s1 1/1 Running 0 87m
排查出现以下问题的原因:
检查kube-scheduler和kube-controller-manager组件配置是否禁用了非安全端口
[root@k8s1 ~]# vi /etc/kubernetes/manifests/kube-controller-manager.yaml
[root@k8s1 ~]# vi /etc/kubernetes/manifests/kube-scheduler.yaml
[root@k8s1 ~]# cat /etc/kubernetes/manifests/kube-controller-manager.yaml
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: null
labels:
component: kube-controller-manager
tier: control-plane
name: kube-controller-manager
namespace: kube-system
spec:
containers:
- command:
- kube-controller-manager
- --allocate-node-cidrs=true
- --authentication-kubeconfig=/etc/kubernetes/controller-manager.conf
- --authorization-kubeconfig=/etc/kubernetes/controller-manager.conf
- --bind-address=127.0.0.1
- --client-ca-file=/etc/kubernetes/pki/ca.crt
- --cluster-cidr=10.244.0.0/16
- --cluster-name=kubernetes
- --cluster-signing-cert-file=/etc/kubernetes/pki/ca.crt
- --cluster-signing-key-file=/etc/kubernetes/pki/ca.key
- --controllers=*,bootstrapsigner,tokencleaner
- --kubeconfig=/etc/kubernetes/controller-manager.conf
- --leader-elect=true
- --node-cidr-mask-size=24
- --port=0
- --requestheader-client-ca-file=/etc/kubernetes/pki/front-proxy-ca.crt
- --root-ca-file=/etc/kubernetes/pki/ca.crt
- --service-account-private-key-file=/etc/kubernetes/pki/sa.key
- --service-cluster-ip-range=10.1.0.0/16
- --use-service-account-credentials=true
image: k8s.gcr.io/kube-controller-manager:v1.19.4
imagePullPolicy: IfNotPresent
livenessProbe:
failureThreshold: 8
httpGet:
host: 127.0.0.1
path: /healthz
port: 10257
scheme: HTTPS
initialDelaySeconds: 10
periodSeconds: 10
timeoutSeconds: 15
name: kube-controller-manager
resources:
requests:
cpu: 200m
startupProbe:
failureThreshold: 24
httpGet:
host: 127.0.0.1
path: /healthz
port: 10257
scheme: HTTPS
initialDelaySeconds: 10
periodSeconds: 10
timeoutSeconds: 15
volumeMounts:
- mountPath: /etc/ssl/certs
name: ca-certs
readOnly: true
- mountPath: /etc/pki
name: etc-pki
readOnly: true
- mountPath: /usr/libexec/kubernetes/kubelet-plugins/volume/exec
name: flexvolume-dir
- mountPath: /etc/kubernetes/pki
name: k8s-certs
readOnly: true
- mountPath: /etc/kubernetes/controller-manager.conf
name: kubeconfig
readOnly: true
hostNetwork: true
priorityClassName: system-node-critical
volumes:
- hostPath:
path: /etc/ssl/certs
type: DirectoryOrCreate
name: ca-certs
- hostPath:
path: /etc/pki
type: DirectoryOrCreate
name: etc-pki
- hostPath:
path: /usr/libexec/kubernetes/kubelet-plugins/volume/exec
type: DirectoryOrCreate
name: flexvolume-dir
- hostPath:
path: /etc/kubernetes/pki
type: DirectoryOrCreate
name: k8s-certs
- hostPath:
path: /etc/kubernetes/controller-manager.conf
type: FileOrCreate
name: kubeconfig
status: {}
分别修改controller scheduler的配置文件将port=0去掉
然后重启kubelet
[root@k8s1 ~]# systemctl restart kubelet
多次执行查看组件状态kubectl get cs命令 上面的修改,集群组件需要时间才能恢复
[root@k8s1 ~]# kubectl get cs
Warning: v1 ComponentStatus is deprecated in v1.19+
NAME STATUS MESSAGE ERROR
scheduler Unhealthy Get "http://127.0.0.1:10251/healthz": dial tcp 127.0.0.1:10251: connect: connection refused
controller-manager Healthy ok
etcd-0 Healthy {"health":"true"}
[root@k8s1 ~]# kubectl get cs
Warning: v1 ComponentStatus is deprecated in v1.19+
NAME STATUS MESSAGE ERROR
controller-manager Healthy ok
scheduler Healthy ok
etcd-0 Healthy {"health":"true"}
[root@k8s1 ~]# kubectl get cs
Warning: v1 ComponentStatus is deprecated in v1.19+
NAME STATUS MESSAGE ERROR
scheduler Healthy ok
controller-manager Healthy ok
etcd-0 Healthy {"health":"true"}
---说明此时master状态已ok
部署worker节点192.168.1.3机器加入集群
[root@k8s2 ~]# kubeadm join 192.168.1.2:6443 --token h7w984.ue6pfb76adusr96w --discovery-token-ca-cert-hash sha256:7b9a74e9385c51d9fa668b9e2ee6366a4f889c28e77c66799077f71007a4c6b8
[preflight] Running pre-flight checks
error execution phase preflight: couldn't validate the identity of the API Server: Get "https://192.168.1.2:6443/api/v1/namespaces/kube-public/configmaps/cluster-info?timeout=10s": dial tcp 192.168.1.2:6443: connect: no route to host
To see the stack trace of this error execute with --v=5 or higher
[root@k8s2 ~]# kubeadm join 192.168.1.2:6443 --token h7w984.ue6pfb76adusr96w --discovery-token-ca-cert-hash sha256:7b9a74e9385c51d9fa668b9e2ee6366a4f889c28e77c66799077f71007a4c6b8
[preflight] Running pre-flight checks
发现节点加入集群卡住了 重新执行还是一样
[root@k8s2 ~]# kubeadm join 192.168.1.2:6443 --token 414bb6.5tgf7dow6g1i1jwm --discovery-token-ca-cert-hash sha256:7b9a74e9385c51d9fa668b9e2ee6366a4f889c28e77c66799077f71007a4c6b8
在master节点重新创建token
[root@k8s1 ~]# kubeadm token create
W1211 08:43:24.571819 37672 configset.go:348] WARNING: kubeadm cannot validate component configs for API groups [kubelet.config.k8s.io kubeproxy.config.k8s.io]
414bb6.5tgf7dow6g1i1jwm
[root@k8s1 ~]# openssl x509 -pubkey -in /etc/kubernetes/pki/ca.crt | openssl rsa -pubin -outform der 2>/dev/null | openssl dgst -sha256 -hex | sed 's/^.* //'
7b9a74e9385c51d9fa668b9e2ee6366a4f889c28e77c66799077f71007a4c6b8
获取token后继续加入
[root@k8s2 ~]# kubeadm join 192.168.1.2:6443 --token 414bb6.5tgf7dow6g1i1jwm --discovery-token-ca-cert-hash sha256:7b9a74e9385c51d9fa668b9e2ee6366a4f889c28e77c66799077f71007a4c6b8
[preflight] Running pre-flight checks
如果一直卡在 “Running pre-flight checks” 上,则很可能是时间未同步,token失效导致
kubeadm alpha phase certs apiserver --apiserver-advertise-address 192.168.1.2
kubeadm alpha phase certs apiserver-kubelet-client
kubeadm alpha phase certs front-proxy-client
如果还不行 就在master节点执行以下命令kubeadm reset
[root@k8s1 ~]# kubeadm reset
[reset] WARNING: Changes made to this host by 'kubeadm init' or 'kubeadm join' will be reverted.
[reset] Are you sure you want to proceed? [y/N]: y
[preflight] Running pre-flight checks
W1213 20:33:07.624671 6352 removeetcdmember.go:79] [reset] No kubeadm config, using etcd pod spec to get data directory
[reset] No etcd config found. Assuming external etcd
[reset] Please, manually reset etcd to prevent further issues
[reset] Stopping the kubelet service
[reset] Unmounting mounted directories in "/var/lib/kubelet"
[reset] Deleting contents of config directories: [/etc/kubernetes/manifests /etc/kubernetes/pki]
[reset] Deleting files: [/etc/kubernetes/admin.conf /etc/kubernetes/kubelet.conf /etc/kubernetes/bootstrap-kubelet.conf /etc/kubernetes/controller-manager.conf /etc/kubernetes/scheduler.conf]
[reset] Deleting contents of stateful directories: [/var/lib/kubelet /var/lib/dockershim /var/run/kubernetes /var/lib/cni]
The reset process does not clean CNI configuration. To do so, you must remove /etc/cni/net.d
The reset process does not reset or clean up iptables rules or IPVS tables.
If you wish to reset iptables, you must do so manually by using the "iptables" command.
If your cluster was setup to utilize IPVS, run ipvsadm --clear (or similar)
to reset your system's IPVS tables.
The reset process does not clean your kubeconfig files and you must remove them manually.
Please, check the contents of the $HOME/.kube/config file.
iptables -F && iptables -t nat -F && iptables -t mangle -F && iptables -X
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 192.168.1.2:6443 --token q7t2wu.3md2ikxbz0s6wesi \
--discovery-token-ca-cert-hash sha256:5b0069d43707d7c65953abc9805dac5011ffc8b800b4d76077ab07e56578f483
[root@k8s2 kubernetes]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s1 Ready master 43m v1.19.4
k8s2 NotReady <none> 6m12s v1.19.4
用新的token 重新加入机器
[root@k8s2 kubernetes]# kubeadm join 192.168.1.2:6443 --token q7t2wu.3md2ikxbz0s6wesi --discovery-token-ca-cert-hash sha256:5b0069d43707d7c65953abc9805dac5011ffc8b800b4d76077ab07e56578f483
[preflight] Running pre-flight checks
error execution phase preflight: [preflight] Some fatal errors occurred:
[ERROR FileAvailable--etc-kubernetes-kubelet.conf]: /etc/kubernetes/kubelet.conf already exists
[ERROR Port-10250]: Port 10250 is in use
[ERROR FileAvailable--etc-kubernetes-pki-ca.crt]: /etc/kubernetes/pki/ca.crt already exists
[preflight] If you know what you are doing, you can make a check non-fatal with `--ignore-preflight-errors=...`
To see the stack trace of this error execute with --v=5 or higher
[root@k8s2 kubernetes]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s1 Ready master 44m v1.19.4
k8s2 NotReady <none> 6m59s v1.19.4
[root@k8s2 kubernetes]#
[root@k8s2 kubernetes]# journalctl -f -u kubelet
-- Logs begin at 五 2020-12-11 21:06:07 CST. --
12月 13 21:33:57 k8s2 kubelet[16297]: For verbose messaging see aws.Config.CredentialsChainVerboseErrors
12月 13 21:33:59 k8s2 kubelet[16297]: E1213 21:33:59.713939 16297 kubelet.go:2103] Container runtime network not ready: NetworkReady=false reason:NetworkPluginNotReady message:docker: network plugin is not ready: cni config uninitialized
12月 13 21:34:01 k8s2 kubelet[16297]: W1213 21:34:01.398131 16297 cni.go:239] Unable to update cni config: no networks found in /etc/cni/net.d
12月 13 21:34:04 k8s2 kubelet[16297]: E1213 21:34:04.548362 16297 aws_credentials.go:77] while getting AWS credentials NoCredentialProviders: no valid providers in chain. Deprecated.
12月 13 21:34:04 k8s2 kubelet[16297]: For verbose messaging see aws.Config.CredentialsChainVerboseErrors
12月 13 21:34:04 k8s2 kubelet[16297]: E1213 21:34:04.725353 16297 kubelet.go:2103] Container runtime network not ready: NetworkReady=false reason:NetworkPluginNotReady message:docker: network plugin is not ready: cni config uninitialized
12月 13 21:34:06 k8s2 kubelet[16297]: W1213 21:34:06.398649 16297 cni.go:239] Unable to update cni config: no networks found in /etc/cni/net.d
12月 13 21:34:09 k8s2 kubelet[16297]: E1213 21:34:09.733595 16297 kubelet.go:2103] Container runtime network not ready: NetworkReady=false reason:NetworkPluginNotReady message:docker: network plugin is not ready: cni config uninitialized
12月 13 21:34:11 k8s2 kubelet[16297]: W1213 21:34:11.398800 16297 cni.go:239] Unable to update cni config: no networks found in /etc/cni/net.d
12月 13 21:34:14 k8s2 kubelet[16297]: E1213 21:34:14.741903 16297 kubelet.go:2103] Container runtime network not ready: NetworkReady=false reason:NetworkPluginNotReady message:docker: network plugin is not ready: cni config uninitialized
12月 13 21:34:16 k8s2 kubelet[16297]: W1213 21:34:16.399079 16297 cni.go:239] Unable to update cni config: no networks found in /etc/cni/net.d
12月 13 21:34:19 k8s2 kubelet[16297]: E1213 21:34:19.752285 16297 kubelet.go:2103] Container runtime network not ready: NetworkReady=false reason:NetworkPluginNotReady message:docker: network plugin is not ready: cni config uninitialized
12月 13 21:34:21 k8s2 kubelet[16297]: W1213 21:34:21.399978 16297 cni.go:239] Unable to update cni config: no networks found in /etc/cni/net.d
12月 13 21:34:22 k8s2 kubelet[16297]: E1213 21:34:22.671102 16297 remote_runtime.go:113] RunPodSandbox from runtime service failed: rpc error: code = Unknown desc = failed pulling image "k8s.gcr.io/pause:3.2": Error response from daemon: Get https://k8s.gcr.io/v2/: net/http: request canceled while waiting for connection (Client.Timeout exceeded while awaiting headers)
12月 13 21:34:22 k8s2 kubelet[16297]: E1213 21:34:22.671148 16297 kuberuntime_sandbox.go:69] CreatePodSandbox for pod "kube-proxy-n64lp_kube-system(1acf1fdb-49d4-4bb9-b5b9-41e5546fd991)" failed: rpc error: code = Unknown desc = failed pulling image "k8s.gcr.io/pause:3.2": Error response from daemon: Get https://k8s.gcr.io/v2/: net/http: request canceled while waiting for connection (Client.Timeout exceeded while awaiting headers)
12月 13 21:34:22 k8s2 kubelet[16297]: E1213 21:34:22.671173 16297 kuberuntime_manager.go:741] createPodSandbox for pod "kube-proxy-n64lp_kube-system(1acf1fdb-49d4-4bb9-b5b9-41e5546fd991)" failed: rpc error: code = Unknown desc = failed pulling image "k8s.gcr.io/pause:3.2": Error response from daemon: Get https://k8s.gcr.io/v2/: net/http: request canceled while waiting for connection (Client.Timeout exceeded while awaiting headers)
12月 13 21:34:22 k8s2 kubelet[16297]: E1213 21:34:22.671247 16297 pod_workers.go:191] Error syncing pod 1acf1fdb-49d4-4bb9-b5b9-41e5546fd991 ("kube-proxy-n64lp_kube-system(1acf1fdb-49d4-4bb9-b5b9-41e5546fd991)"), skipping: failed to "CreatePodSandbox" for "kube-proxy-n64lp_kube-system(1acf1fdb-49d4-4bb9-b5b9-41e5546fd991)" with CreatePodSandboxError: "CreatePodSandbox for pod \"kube-proxy-n64lp_kube-system(1acf1fdb-49d4-4bb9-b5b9-41e5546fd991)\" failed: rpc error: code = Unknown desc = failed pulling image \"k8s.gcr.io/pause:3.2\": Error response from daemon: Get https://k8s.gcr.io/v2/: net/http: request canceled while waiting for connection (Client.Timeout exceeded while awaiting headers)"
12月 13 21:34:22 k8s2 kubelet[16297]: E1213 21:34:22.782423 16297 remote_runtime.go:113] RunPodSandbox from runtime service failed: rpc error: code = Unknown desc = failed pulling image "k8s.gcr.io/pause:3.2": Error response from daemon: Get https://k8s.gcr.io/v2/: net/http: request canceled while waiting for connection (Client.Timeout exceeded while awaiting headers)
12月 13 21:34:22 k8s2 kubelet[16297]: E1213 21:34:22.782469 16297 kuberuntime_sandbox.go:69] CreatePodSandbox for pod "kube-flannel-ds-756np_kube-system(5b8adc19-4a6c-445c-9d4c-505a63e2030d)" failed: rpc error: code = Unknown desc = failed pulling image "k8s.gcr.io/pause:3.2": Error response from daemon: Get https://k8s.gcr.io/v2/: net/http: request canceled while waiting for connection (Client.Timeout exceeded while awaiting headers)
12月 13 21:34:22 k8s2 kubelet[16297]: E1213 21:34:22.782493 16297 kuberuntime_manager.go:741] createPodSandbox for pod "kube-flannel-ds-756np_kube-system(5b8adc19-4a6c-445c-9d4c-505a63e2030d)" failed: rpc error: code = Unknown desc = failed pulling image "k8s.gcr.io/pause:3.2": Error response from daemon: Get https://k8s.gcr.io/v2/: net/http: request canceled while waiting for connection (Client.Timeout exceeded while awaiting headers)
12月 13 21:34:22 k8s2 kubelet[16297]: E1213 21:34:22.782566 16297 pod_workers.go:191] Error syncing pod 5b8adc19-4a6c-445c-9d4c-505a63e2030d ("kube-flannel-ds-756np_kube-system(5b8adc19-4a6c-445c-9d4c-505a63e2030d)"), skipping: failed to "CreatePodSandbox" for "kube-flannel-ds-756np_kube-system(5b8adc19-4a6c-445c-9d4c-505a63e2030d)" with CreatePodSandboxError: "CreatePodSandbox for pod \"kube-flannel-ds-756np_kube-system(5b8adc19-4a6c-445c-9d4c-505a63e2030d)\" failed: rpc error: code = Unknown desc = failed pulling image \"k8s.gcr.io/pause:3.2\": Error response from daemon: Get https://k8s.gcr.io/v2/: net/http: request canceled while waiting for connection (Client.Timeout exceeded while awaiting headers)"
12月 13 21:34:24 k8s2 kubelet[16297]: E1213 21:34:24.764133 16297 kubelet.go:2103] Container runtime network not ready: NetworkReady=false reason:NetworkPluginNotReady message:docker: network plugin is not ready: cni config uninitialized
12月 13 21:34:26 k8s2 kubelet[16297]: W1213 21:34:26.400564 16297 cni.go:239] Unable to update cni config: no networks found in /etc/cni/net.d
通过研究发现 /etc/没有cni这个目录 其他node节点都有
使用scp 把master节点的cni 下 复制过来
scp -r master1:/etc/cni /etc/cni
重启kubelet
systemctl restart kubelet
[root@k8s1 ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s1 Ready master 52m v1.19.4
k8s2 Ready <none> 15m v1.19.4
可以看到192.168.1.3机器已正确加入集群
执行以下命令将其设置为work节点
[root@k8s1 ~]# kubectl label nodes k8s2 node-role.kubernetes.io/worker=worker
再次查看
[root@k8s1 yum.repos.d]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s1 Ready master 35d v1.19.4
k8s2 Ready worker 33d v1.19.4
小贴士:移除NODE节点的方法
第一步:先将节点设置为维护模式(host1是节点名称)
[root@k8s1 ~]# kubectl drain k8s2 --delete-local-data --force --ignore-daemonsets
node/k8s2 cordoned
WARNING: ignoring DaemonSet-managed Pods: kube-system/kube-flannel-ds-756np, kube-system/kube-proxy-n64lp
node/k8s2 drained
第二步:然后删除节点
[root@k8s1 ~]# kubectl delete node k8s2
node "host1" deleted
第三步:查看节点
发现k8s2节点已经被删除了
[root@k8s1~]# kubectl get nodes
如果这个时候再想添加进来这个node,需要执行两步操作
第一步:停掉kubelet(需要添加进来的节点操作)
[root@host1 ~]# systemctl stop kubelet
第二步:删除相关文件
[root@host1 ~]# rm -rf /etc/kubernetes/*
第三步:添加节点
[root@k8s2 ~]# kubeadm join 192.168.1.2:6443 --token q7t2wu.3md2ikxbz0s6wesi --discovery-token-ca-cert-hash sha256:5b0069d43707d7c65953abc9805dac5011ffc8b800b4d76077ab07e56578f483
过了二十四小时 token失效
[root@k8s2 ~]# kubeadm join 192.168.1.2:6443 --token q7t2wu.3md2ikxbz0s6wesi --discovery-token-ca-cert-hash sha256:5b0069d43707d7c65953abc9805dac5011ffc8b800b4d76077ab07e56578f483
[preflight] Running pre-flight checks
一直停留检查
用kubeadm搭建的K8s集群,kubeadm创建的Token的默认有效期为24小时,因此24小时后会失效
去matser节点查看token 发现果然失效
[root@k8s1 ~]# kubeadm token list
[root@k8s1 ~]#
需要重新创建永久的token
kubeadm token create --ttl 0
[root@k8s1 ~]# kubeadm token create --ttl 0
W1215 06:35:01.095491 30097 configset.go:348] WARNING: kubeadm cannot validate component configs for API groups [kubelet.config.k8s.io kubeproxy.config.k8s.io]
gv1swg.nv29kxndfjprydjc
[root@k8s1 ~]# kubeadm token list
TOKEN TTL EXPIRES USAGES DESCRIPTION EXTRA GROUPS
gv1swg.nv29kxndfjprydjc <forever> <never> authentication,signing <none> system:bootstrappers:kubeadm:default-node-token
[root@k8s1 ~]# openssl x509 -pubkey -in /etc/kubernetes/pki/ca.crt | openssl rsa -pubin -outform der 2>/dev/null | openssl dgst -sha256 -hex | sed 's/^.* //'
5b0069d43707d7c65953abc9805dac5011ffc8b800b4d76077ab07e56578f483
因此node加入k8s集群的命令是
kubeadm reset
kubeadm join 192.168.1.2:6443 --token gv1swg.nv29kxndfjprydjc --discovery-token-ca-cert-hash sha256:5b0069d43707d7c65953abc9805dac5011ffc8b800b4d76077ab07e56578f483
[root@k8s2 ~]# kubeadm reset
[reset] WARNING: Changes made to this host by 'kubeadm init' or 'kubeadm join' will be reverted.
[reset] Are you sure you want to proceed? [y/N]: y
[preflight] Running pre-flight checks
W1215 06:38:16.467661 1948 removeetcdmember.go:79] [reset] No kubeadm config, using etcd pod spec to get data directory
[reset] No etcd config found. Assuming external etcd
[reset] Please, manually reset etcd to prevent further issues
[reset] Stopping the kubelet service
[reset] Unmounting mounted directories in "/var/lib/kubelet"
[reset] Deleting contents of config directories: [/etc/kubernetes/manifests /etc/kubernetes/pki]
[reset] Deleting files: [/etc/kubernetes/admin.conf /etc/kubernetes/kubelet.conf /etc/kubernetes/bootstrap-kubelet.conf /etc/kubernetes/controller-manager.conf /etc/kubernetes/scheduler.conf]
[reset] Deleting contents of stateful directories: [/var/lib/kubelet /var/lib/dockershim /var/run/kubernetes /var/lib/cni]
The reset process does not clean CNI configuration. To do so, you must remove /etc/cni/net.d
The reset process does not reset or clean up iptables rules or IPVS tables.
If you wish to reset iptables, you must do so manually by using the "iptables" command.
If your cluster was setup to utilize IPVS, run ipvsadm --clear (or similar)
to reset your system's IPVS tables.
The reset process does not clean your kubeconfig files and you must remove them manually.
Please, check the contents of the $HOME/.kube/config file.
[root@k8s2 ~]# kubeadm join 192.168.1.2:6443 --token gv1swg.nv29kxndfjprydjc --discovery-token-ca-cert-hash sha256:5b0069d43707d7c65953abc9805dac5011ffc8b800b4d76077ab07e56578f483
[preflight] Running pre-flight checks
[preflight] Reading configuration from the cluster...
[preflight] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -oyaml'
[kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"
[kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env"
[kubelet-start] Starting the kubelet
[kubelet-start] Waiting for the kubelet to perform the TLS Bootstrap...
This node has joined the cluster:
去主节点查看nodes
[root@k8s1 ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s1 Ready master 33h v1.19.4
k8s2 Ready <none> 70s v1.19.4
将其设置为work节点
kubectl label nodes k8s2 node-role.kubernetes.io/worker=worker
-------------------------------------------------------------------------------------至此master worker节点创建成功----------------------------------------------------------------------------------------
以下操作为实践:
在work节点创建一个nginx
docker pull nginx
[root@k8s2 ~]# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
nginx latest 7baf28ea91eb 3 days ago 133MB
[root@k8s2 ~]# cat nginx-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:latest
ports:
- containerPort: 80
[root@k8s2 ~]# kubectl apply -f nginx-deployment.yaml
deployment.apps/nginx-deployment created
[root@k8s2 ~]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
[root@k8s2 ~]# docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
[root@k8s2 ~]# docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
[root@k8s2 ~]# kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx-deployment-585449566-rwlkn 0/1 ContainerCreating 0 77s
nginx-deployment-585449566-vqd75 0/1 ContainerCreating 0 77s
nginx-deployment-585449566-znzt2 0/1 ContainerCreating 0 77s
[root@k8s2 ~]# kubectl get pod,svc -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
pod/nginx-deployment-585449566-rwlkn 0/1 ContainerCreating 0 118s <none> k8s2 <none> <none>
pod/nginx-deployment-585449566-vqd75 0/1 ContainerCreating 0 118s <none> k8s2 <none> <none>
pod/nginx-deployment-585449566-znzt2 0/1 ContainerCreating 0 118s <none> k8s2 <none> <none>
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
service/kubernetes ClusterIP 10.1.0.1 <none> 443/TCP 34h <none>
ContainerCreating 原因
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 11m default-scheduler Successfully assigned default/nginx-deployment-585449566-znzt2 to k8s2
Warning FailedCreatePodSandBox 16s (x17 over 11m) kubelet Failed to create pod sandbox: rpc error: code = Unknown desc = failed pulling image "k8s.gcr.io/pause:3.2": Error response from daemon: Get https://k8s.gcr.io/v2/: net/http: request canceled while waiting for connection (Client.Timeout exceeded while awaiting headers)
failed pulling image "k8s.gcr.io/pause:3.2解决:
failed pulling image "k8s.gcr.io/pause:3.2解决:
下载pause镜像即可
docker pull registry.aliyuncs.com/google_containers/pause:3.2
docker tag registry.aliyuncs.com/google_containers/pause:3.2 k8s.gcr.io/pause:3.2
docker rmi registry.aliyuncs.com/google_containers/pause:3.2
[root@k8s2 ~]# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
nginx latest 7baf28ea91eb 3 days ago 133MB
k8s.gcr.io/pause 3.2 80d28bedfe5d 10 months ago 683kB
[root@k8s2 ~]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
8c8c3a295764 k8s.gcr.io/pause:3.2 "/pause" 1 second ago Up Less than a second k8s_POD_nginx-deployment-585449566-rwlkn_default_1f824ed4-13d7-47b2-9220-0677e15f3402_14
180fc51ffb4c k8s.gcr.io/pause:3.2 "/pause" 1 second ago Up Less than a second k8s_POD_nginx-deployment-585449566-vqd75_default_ce8fa63c-18cc-4038-97cc-76e01137faaa_6
3acf2be4de3e k8s.gcr.io/pause:3.2 "/pause" 16 seconds ago Up 15 seconds k8s_POD_kube-proxy-xx47s_kube-system_b1959a88-66cf-4534-b53f-f59304c1ed51_0
5ae9d3b7ff29 k8s.gcr.io/pause:3.2 "/pause" 36 seconds ago Up 35 seconds k8s_POD_kube-flannel-ds-49zng_kube-system_d318c6f7-1c6b-45f6-a4dd-a6e9cc31750f_0
查看pod启动的事件 kubectl describe pod nginx-deployment
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 22m default-scheduler Successfully assigned default/nginx-deployment-585449566-znzt2 to k8s2
Warning FailedCreatePodSandBox 3m29s (x28 over 22m) kubelet Failed to create pod sandbox: rpc error: code = Unknown desc = failed pulling image "k8s.gcr.io/pause:3.2": Error response from daemon: Get https://k8s.gcr.io/v2/: net/http: request canceled while waiting for connection (Client.Timeout exceeded while awaiting headers)
Normal SandboxChanged 2m9s (x30 over 3m14s) kubelet Pod sandbox changed, it will be killed and re-created.
解决办法: 准备两个镜像
12月 15 08:08:12 k8s2 kubelet[2082]: E1215 08:08:12.947800 2082 cni.go:366] Error adding default_nginx-deployment-585449566-vqd75/1313691a4432b6f7635ae4e9a026c7a556222680cea167bfd4461f50ade05ea2 to network
12月 15 08:08:12 k8s2 kubelet[2082]: W1215 08:08:12.956552 2082 pod_container_deletor.go:79] Container "bea96ec9d609e93d8276bc5d0608b9705737cb56a94653981960d3c9d8f60714" not found in pod's containers
12月 15 08:08:13 k8s2 kubelet[2082]: W1215 08:08:13.012928 2082 pod_container_deletor.go:79] Container "1313691a4432b6f7635ae4e9a026c7a556222680cea167bfd4461f50ade05ea2" not found in pod's containers
[root@k8s2 ~]# ^C
[root@k8s2 ~]# docker pull registry.aliyuncs.com/google_containers/kube-proxy:1.19.4
Error response from daemon: manifest for registry.aliyuncs.com/google_containers/kube-proxy:1.19.4 not found: manifest unknown: manifest unknown
[root@k8s2 ~]# docker pull registry.aliyuncs.com/google_containers/kube-proxy:v1.19.4
v1.19.4: Pulling from google_containers/kube-proxy
4ba180b702c8: Pull complete
85b604bcc41a: Pull complete
fafe7e2b354a: Pull complete
b2c4667c1ca7: Pull complete
c93c6a0c3ea5: Pull complete
beea6d17d8e9: Pull complete
ad9d8b1b0a71: Pull complete
Digest: sha256:2b06800c87f9f12ee470dd4d458659f70b6ab47a19543e9d1a024aab0007ee6b
Status: Downloaded newer image for registry.aliyuncs.com/google_containers/kube-proxy:v1.19.4
registry.aliyuncs.com/google_containers/kube-proxy:v1.19.4
[root@k8s2 ~]# cd /tmp/
[root@k8s2 tmp]# docker load -i flannel.tar
ace0eda3e3be: Loading layer [==================================================>] 5.843MB/5.843MB
0a790f51c8dd: Loading layer [==================================================>] 11.42MB/11.42MB
db93500c64e6: Loading layer [==================================================>] 2.595MB/2.595MB
70351a035194: Loading layer [==================================================>] 45.68MB/45.68MB
cd38981c5610: Loading layer [==================================================>] 5.12kB/5.12kB
dce2fcdf3a87: Loading layer [==================================================>] 9.216kB/9.216kB
be155d1c86b7: Loading layer [==================================================>] 7.68kB/7.68kB
Loaded image: quay.io/coreos/flannel:v0.13.1-rc1
[root@k8s2 tmp]# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
nginx latest 7baf28ea91eb 3 days ago 133MB
quay.io/coreos/flannel v0.13.1-rc1 f03a23d55e57 3 weeks ago 64.6MB
registry.aliyuncs.com/google_containers/kube-proxy v1.19.4 635b36f4d89f 4 weeks ago 118MB
k8s.gcr.io/pause 3.2 80d28bedfe5d 10 months ago 683kB
没找到原因 删除 然后明天重新创建
[root@k8s2 tmp]# kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx-deployment-585449566-rwlkn 0/1 ContainerCreating 0 43m
nginx-deployment-585449566-vqd75 0/1 ContainerCreating 0 43m
nginx-deployment-585449566-znzt2 0/1 ContainerCreating 0 43m
[root@k8s2 tmp]# kubectl get deployment
NAME READY UP-TO-DATE AVAILABLE AGE
nginx-deployment 0/3 3 0 44m
[root@k8s2 tmp]# kubectl delete pods nginx-deployment-585449566-rwlkn nginx-deployment-585449566-vqd75 nginx-deployment-585449566-znzt2
pod "nginx-deployment-585449566-rwlkn" deleted
pod "nginx-deployment-585449566-vqd75" deleted
pod "nginx-deployment-585449566-znzt2" deleted
[root@k8s2 tmp]# kubectl delete nginx-deployment nginx-deployment
error: the server doesn't have a resource type "nginx-deployment"
[root@k8s2 tmp]# kubectl delete deployment nginx-deployment
deployment.apps "nginx-deployment" deleted
[root@k8s2 tmp]# kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx-deployment-585449566-24cxg 0/1 Terminating 0 39s
nginx-deployment-585449566-r2t7t 0/1 Terminating 0 39s
nginx-deployment-585449566-wbgf2 0/1 Terminating 0 39s
[root@k8s2 tmp]# kubectl get pods
No resources found in default namespace.
重新创建pod后还是没有可用的pod

利用以下命令查找到原因:
kubectl describe pod nginx-deployment
[root@k8s1 ~]# kubectl describe pod nginx-deployment
Name: nginx-deployment-585449566-592bx
Namespace: default
Priority: 0
Node: k8s3/192.168.1.4
Start Time: Sat, 30 Jan 2021 23:13:57 +0800
Labels: app=nginx
pod-template-hash=585449566
Annotations: <none>
Status: Running
IP:
IPs: <none>
Controlled By: ReplicaSet/nginx-deployment-585449566
Containers:
nginx:
Container ID: docker://47db42222b61bfcd8e4da102e115f42b3e3bb1294d5db7128af644585fb85c57
Image: nginx:latest
Image ID: docker-pullable://nginx@sha256:10b8cc432d56da8b61b070f4c7d2543a9ed17c2b23010b43af434fd40e2ca4aa
Port: 80/TCP
Host Port: 0/TCP
State: Terminated
Reason: Completed
Exit Code: 0
Started: Sat, 30 Jan 2021 23:44:37 +0800
Finished: Sun, 31 Jan 2021 02:05:20 +0800
Ready: False
Restart Count: 0
Environment: <none>
Mounts:
/var/run/secrets/kubernetes.io/serviceaccount from default-token-cbqsr (ro)
Conditions:
Type Status
Initialized True
Ready False
ContainersReady False
PodScheduled True
Volumes:
default-token-cbqsr:
Type: Secret (a volume populated by a Secret)
SecretName: default-token-cbqsr
Optional: false
QoS Class: BestEffort
Node-Selectors: <none>
Tolerations: node.kubernetes.io/not-ready:NoExecute op=Exists for 300s
node.kubernetes.io/unreachable:NoExecute op=Exists for 300s
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedCreatePodSandBox 6m10s kubelet Failed to create pod sandbox: rpc error: code = Unknown desc = failed to set up sandbox container "399e44b9ad8483831d009592be4e920931855484e7582cf98efb8beddbb81bcd" network for pod "nginx-deployment-585449566-592bx": networkPlugin cni failed to set up pod "nginx-deployment-585449566-592bx_default" network: open /run/flannel/subnet.env: no such file or directory
Warning FailedCreatePodSandBox 6m8s kubelet Failed to create pod sandbox: rpc error: code = Unknown desc = failed to set up sandbox container "ab51ec7c3a9b8d6508c20ee5b1b11195760fda87218a430768fd6db87236b112" network for pod "nginx-deployment-585449566-592bx": networkPlugin cni failed to set up pod "nginx-deployment-585449566-592bx_default" network: open /run/flannel/subnet.env: no such file or directory
以上报错是说192.168.1.3/4两个work节点上没有/run/flannel/subnet.env这个文件
于是从192.168.1.2master上拷贝过去:
[root@k8s1 ~]# cd /run/flannel/
[root@k8s1 flannel]# pwd
/run/flannel
[root@k8s1 flannel]# ll
总用量 4
-rw-r--r-- 1 root root 96 2月 1 03:10 subnet.env
[root@k8s1 flannel]# scp subnet.env k8s2:/run/flannel/
root@k8s2's password:
subnet.env 100% 96 147.3KB/s 00:00
[root@k8s1 flannel]# scp subnet.env k8s3:/run/flannel/
root@k8s3's password:
subnet.env 100% 96 22.3KB/s 00:00
[root@k8s1 flannel]# kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx-deployment-585449566-592bx 1/1 Running 1 28h
nginx-deployment-585449566-67b89 1/1 Running 1 28h
nginx-deployment-585449566-wmtcn 1/1 Running 1 28h
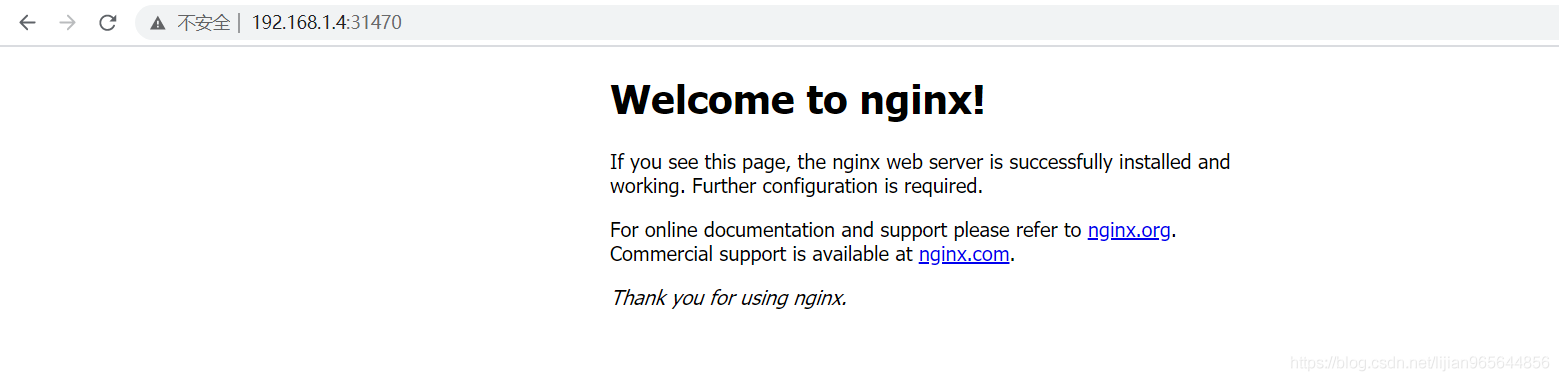
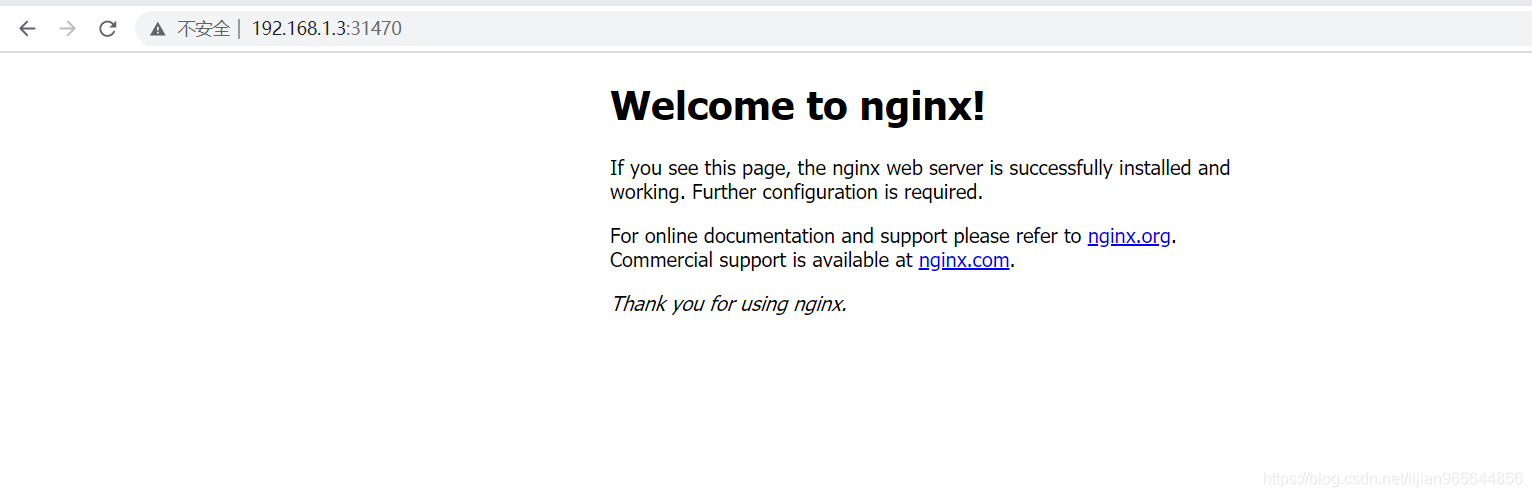
如上图可以看到拷贝完后:三个pod是正常的。
浏览器不能访问nginx首页:
1,查看flannel网络组件有没有启动好
结果发现192.168.1.3/4上缺少flannel相关的镜像
必须保证有以下两个组件的镜像:
quay.io/coreos/flannel v0.13.1-rc1 f03a23d55e57 2 months ago 64.6MB
k8s.gcr.io/kube-proxy v1.19.4 635b36f4d89f 2 months ago 118MB
没有的节点 执行以下操作
docker pull registry.aliyuncs.com/google_containers/kube-proxy:v1.19.4
docker tag 635b36f4d89f k8s.gcr.io/kube-proxy:v1.19.4
docker rmi registry.aliyuncs.com/google_containers/kube-proxy:v1.19.4
查看nginx启动是否报错 报错的原因:
kubectl describe pod nginx-deployment-585449566-592bx
kubelet (combined from similar events): Failed to create pod sandbox: rpc error: code = Unknown desc = failed to set up sandbox container "4865419e49aee72b0799070518ab0cf6b26dcd336c60bf19a7982c36cbd77eb3" network for pod "nginx-deployment-585449566-592bx": networkPlugin cni failed to set up pod "nginx-deployment-585449566-592bx_default" network: failed to set bridge addr: "cni0" already has an IP address different from 10.244.2.1/24
2,查看网卡
ifconfig -- 如果没有 执行yum -y install net-tools
发现cni0的网卡ip确实跟上面报错的不一致,卸载掉网卡 重启网络即可,在3/4节点上分别执行
ifconfig cni0 down
ip link delete cni0
systemctl restart network
最后通过浏览器验证:
部署dashboard
在k8s2node节点部署
配置192.168.1.3的kubectl补全命令:
#yum install -y bash-completion
#source <(kubectl completion bash)
#echo "source <(kubectl completion bash)" >> ~/.bashrc
#source ~/.bashrc
如果配置完按tab键报如下错:
[root@k8s2 ~]# kubectl create cku-bash: _get_comp_words_by_ref: 未找到命令
可以重新配置:
[root@k8s2 ~]# source /usr/share/bash-completion/bash_completion
[root@k8s2 ~]# source <(kubectl completion bash)
准备镜像:
docker pull kubernetesui/dashboard:v2.0.0
docker pull kubernetesui/metrics-scraper:v1.0.4
安装:
cd /root/
wget https://raw.githubusercontent.com/kubernetes/dashboard/v2.0.0/aio/deploy/recommended.yaml
kubectl create -f recommended.yaml
[root@k8s2 ~]# kubectl create clusterrolebinding dashboard-admin --clusterrole=cluster-admin --serviceaccount=kunernetes-dashboard:dashboard-admin
clusterrolebinding.rbac.authorization.k8s.io/dashboard-admin created
[root@k8s2 ~]# kubectl get secret -n kubernetes-dashboard
NAME TYPE DATA AGE
dashboard-admin-token-25hk7 kubernetes.io/service-account-token 3 9m41s
default-token-x8nfx kubernetes.io/service-account-token 3 10m
kubernetes-dashboard-certs Opaque 0 10m
kubernetes-dashboard-csrf Opaque 1 10m
kubernetes-dashboard-key-holder Opaque 2 10m
kubernetes-dashboard-token-lvqxk kubernetes.io/service-account-token 3 10m
[root@k8s2 ~]# kubectl describe secret dashboard-admin-token-25hk7 -n kubernetes-dashboard
Name: dashboard-admin-token-25hk7
Namespace: kubernetes-dashboard
Labels: <none>
Annotations: kubernetes.io/service-account.name: dashboard-admin
kubernetes.io/service-account.uid: ac69e55f-377c-4481-8ed7-16f6294cad03
Type: kubernetes.io/service-account-token
Data
====
ca.crt: 1066 bytes
namespace: 20 bytes
token: eyJhbGciOiJSUzI1NiIsImtpZCI6IjlUZlFaMVB5Vm04VktTUWE5OHlsWlMyUVNmOWROM1lsX0NxOC1nSEREUXMifQ.eyJpc3MiOiJrdWJlcm5ldGVzL3NlcnZpY2VhY2NvdW50Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9uYW1lc3BhY2UiOiJrdWJlcm5ldGVzLWRhc2hib2FyZCIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VjcmV0Lm5hbWUiOiJkYXNoYm9hcmQtYWRtaW4tdG9rZW4tMjVoazciLCJrdWJlcm5ldGVzLmlvL3NlcnZpY2VhY2NvdW50L3NlcnZpY2UtYWNjb3VudC5uYW1lIjoiZGFzaGJvYXJkLWFkbWluIiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9zZXJ2aWNlLWFjY291bnQudWlkIjoiYWM2OWU1NWYtMzc3Yy00NDgxLThlZDctMTZmNjI5NGNhZDAzIiwic3ViIjoic3lzdGVtOnNlcnZpY2VhY2NvdW50Omt1YmVybmV0ZXMtZGFzaGJvYXJkOmRhc2hib2FyZC1hZG1pbiJ9.r90w90FGCamd5smW6T5PtwyutEFoSXEsWX53r-akULk6sMhj0du18sakwV_lArIPZfxl24D2nbKr2hHCazx4_2VRbgMF7OAjGk8je83fDAcYCzarLx33f-sQxYNp2anmB1HSyclJJeZalH4Q4PYF0TEk35dfN8haFUOiFygTHVfa82VJ-WM_w7-d4rIJfzqgDosL-icroyW68nbsWg6n4WUlMP_yY_VKYDRU6TXfidRuXAK-7ClG5MQD0Oen6D2lbgpcVs5Rug2CApd8Jqoh4krBAyoLulaGmM6yj1nmS2Tp41lRC5YxbY8ZRA5IJ53KG0hioRXGcEY_0bGdZj4wjw
kubectl -n kubernetes-dashboard edit service kubernetes-dashboard 修改service 将type:clusterIP 改成 NodePort
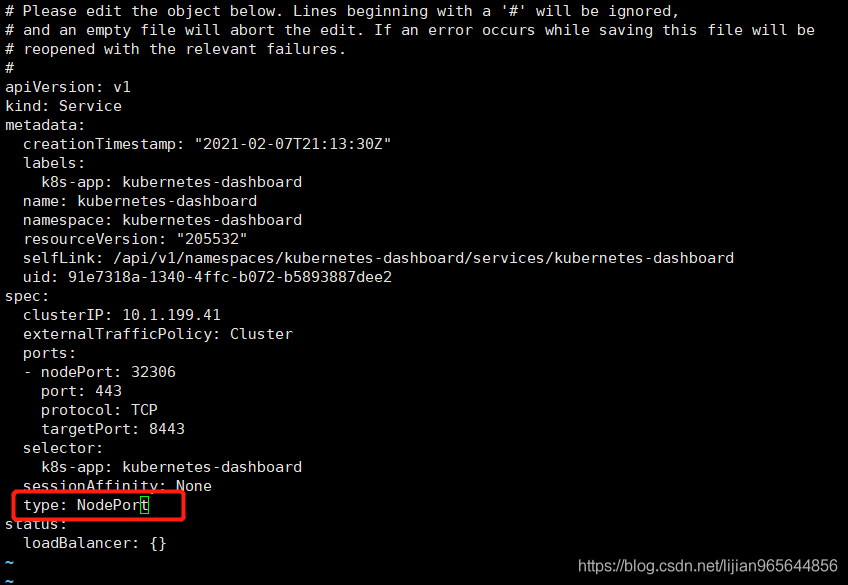
[root@k8s2 ~]# kubectl get svc -n kubernetes-dashboard
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
dashboard-metrics-scraper ClusterIP 10.1.213.83 <none> 8000/TCP 42m
kubernetes-dashboard NodePort 10.1.199.41 <none> 443:32306/TCP 42m
可以看到对应的端口是32306
打开chrome访问网站:
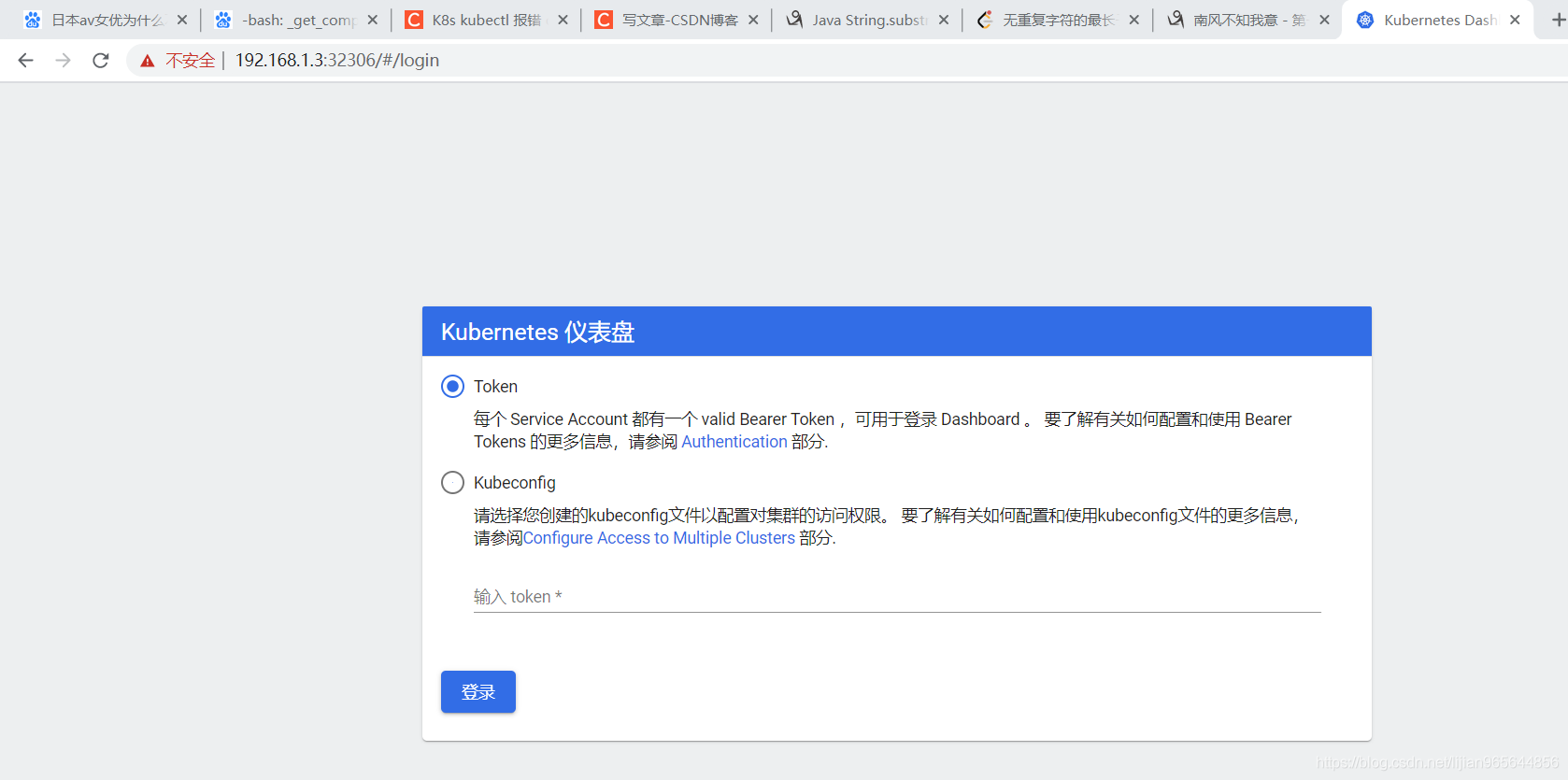
选择用token的方式:
输入上面kubectl describe secret dashboard-admin-token-25hk7 -n kubernetes-dashboard这个命令得到的token 点击登陆即可
[root@k8s2 ~]# kubectl describe secret dashboard-admin-token-25hk7 -n kubernetes-dashboard
Name: dashboard-admin-token-25hk7
Namespace: kubernetes-dashboard
Labels: <none>
Annotations: kubernetes.io/service-account.name: dashboard-admin
kubernetes.io/service-account.uid: ac69e55f-377c-4481-8ed7-16f6294cad03
Type: kubernetes.io/service-account-token
Data
====
ca.crt: 1066 bytes
namespace: 20 bytes
token: eyJhbGciOiJSUzI1NiIsImtpZCI6IjlUZlFaMVB5Vm04VktTUWE5OHlsWlMyUVNmOWROM1lsX0NxOC1nSEREUXMifQ.eyJpc3MiOiJrdWJlcm5ldGVzL3NlcnZpY2VhY2NvdW50Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9uYW1lc3BhY2UiOiJrdWJlcm5ldGVzLWRhc2hib2FyZCIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VjcmV0Lm5hbWUiOiJkYXNoYm9hcmQtYWRtaW4tdG9rZW4tMjVoazciLCJrdWJlcm5ldGVzLmlvL3NlcnZpY2VhY2NvdW50L3NlcnZpY2UtYWNjb3VudC5uYW1lIjoiZGFzaGJvYXJkLWFkbWluIiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9zZXJ2aWNlLWFjY291bnQudWlkIjoiYWM2OWU1NWYtMzc3Yy00NDgxLThlZDctMTZmNjI5NGNhZDAzIiwic3ViIjoic3lzdGVtOnNlcnZpY2VhY2NvdW50Omt1YmVybmV0ZXMtZGFzaGJvYXJkOmRhc2hib2FyZC1hZG1pbiJ9.r90w90FGCamd5smW6T5PtwyutEFoSXEsWX53r-akULk6sMhj0du18sakwV_lArIPZfxl24D2nbKr2hHCazx4_2VRbgMF7OAjGk8je83fDAcYCzarLx33f-sQxYNp2anmB1HSyclJJeZalH4Q4PYF0TEk35dfN8haFUOiFygTHVfa82VJ-WM_w7-d4rIJfzqgDosL-icroyW68nbsWg6n4WUlMP_yY_VKYDRU6TXfidRuXAK-7ClG5MQD0Oen6D2lbgpcVs5Rug2CApd8Jqoh4krBAyoLulaGmM6yj1nmS2Tp41lRC5YxbY8ZRA5IJ53KG0hioRXGcEY_0bGdZj4wjw
登陆成功:















 1348
1348











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











