






LZ4 is a very fast compression and decompression algorithm. This nodejs module provides a Javascript implementation of the decoder as well as native bindings to the LZ4 functions. Nodejs Streams are also supported for compression and decompression.
NB. Version 0.2 does not support the legacy format, only the one as of "LZ4 Streaming Format 1.4". Use version 0.1 if required.
Encoding
There are 2 ways to encode:
asynchronous using nodejs Streams - slowest but can handle very large data sets (no memory limitations).
synchronous by feeding the whole set of data - faster but is limited by the amount of memory
Decoding
There are 2 ways to decode:
asynchronous using nodejs Streams - slowest but can handle very large data sets (no memory limitations)
synchronous by feeding the whole LZ4 data - faster but is limited by the amount of memory
LZ4格式
The compressed block is composed of sequences.
每个数据块可以压缩成若干个序列,格式如下:
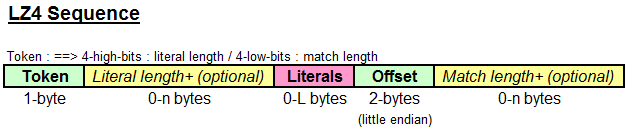
(1) literals
length of literals. If it is 0, then there is no literal. If it is 15, then we need to add some more bytes to indicate the
full length. Each additional byte then represent a value of 0 to 255, which is added to the previous value to produce
a total length. When the byte value is 255, another byte is output.
literals are uncompressed bytes, to be copied as-is.
(2) match
offset. It represents the position of the match to be copied from.
Note that 0 is an invalid value, never used. 1 means "current position - 1 byte".
The maximum offset value is really 65535. The value is stored using "little endian" format.
matchlength. There is an baselength to apply, which is the minimum length of a match called minmatch.
This minimum is 4. As a consequence, a value of 0 means a match length of 4 bytes, and a value of 15 means a
match length of 19+ bytes. (Similar to literal length)
(3) rules
1. The last 5 bytes are always literals.
2. The last match cannot start within the last 12 bytes.
So a file within less than 13 bytes can only be represented as literals.
(4) scan strategy
a single-cell wide hash table.
Each position in the input data block gets "hashed", using the first 4 bytes (minimatch). Then the position is stored
at the hashed position. Obviously, the smaller the table, the more collisions we get, reducing compression
effectiveness. The decoder do not care of the method used to find matches, and requires no addtional memory.
(5) Streaming format
















 278
278











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









