







《DeepLab V2》论文阅读
背景
作者提到DeepLab系列面临三大挑战:
挑战一:为分类任务设计的DCNN中的多次Max-Pooling和全连接层会导致空间信息的丢失。在DeepLabV1中引入了空洞卷积来增加输出的分辨率,以保留更多的空间信息。
挑战二:图像存在多尺度问题,有大有小。一种常见的处理方法是图像金字塔,即将原图resize到不同尺度,输入到相同的网络,获得不同的feature map,然后做融合,这种方法的确可以提升准确率,然而带来的另外一个问题就是速度太慢。DeepLab v2为了解决这一问题,引入了ASPP(atrous spatial pyramid pooling)模块,即是将feature map通过并联的采用不同膨胀速率的空洞卷积层,并将输出结果融合来得到图像的分割结果。
挑战三:分割结果不够精细的问题。这个和DeepLabV1的处理方式一样,在后处理过程使用全连接CRF精细化分割结果。
同时,相比于DeepLabV1,DeepLabV2的backbone由V1的VGG16变成了ResNet,并带来了效果提升。最后DeepLabV2在PASCAL VOC 2012获得了SOAT结果。代码开源在http://liangchiehchen.com/projects。
网络结构
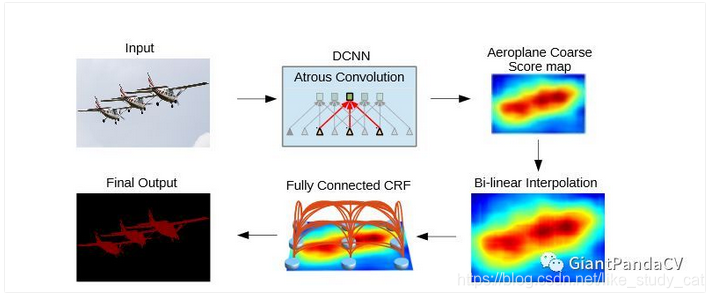 相比于DeepLabV1的输出步幅是16,需要双线性插值上采样16倍才可以得到预测结果,DeepLabV2的输出步幅是8,只需要上采样8倍,结果清晰了很多。
相比于DeepLabV1的输出步幅是16,需要双线性插值上采样16倍才可以得到预测结果,DeepLabV2的输出步幅是8,只需要上采样8倍,结果清晰了很多。
空洞/(膨胀)卷积
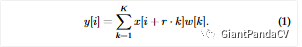
空洞卷积作用在一维信号时可以用公式1表示,其中x代表输入信号,w是卷积核系数,y是输出,其中k是输入信号维度,r是膨胀速率,如果r等于就退化为标准卷积。Fig.2表示空洞卷积的一维示意图:
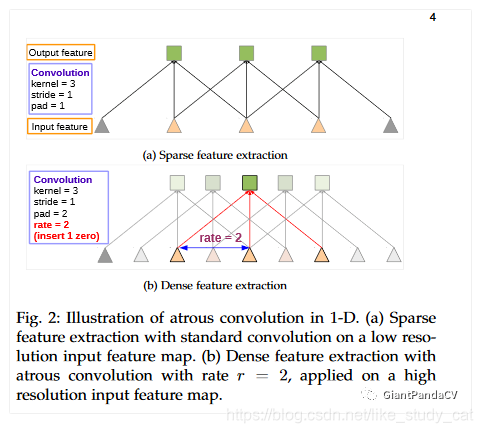
其中Fig.2(a)表示表示标准卷积在低分辨率图上提取稀疏特征的示意图,底部为输入为3维向量,zeropadding=1,经kenel_size=3,stride=1的卷积后输出为3维。而Fig.2(b)在高分辨率输入5维图片上,zeropadding=2,膨胀速率2的膨胀卷积来采集密集特征的示意图,使用空洞卷积能提取到更多的密集特征,计算量较常规卷积基本保持不变。
在二维图像上的空洞卷积,论文给了另外一张图Fig3:
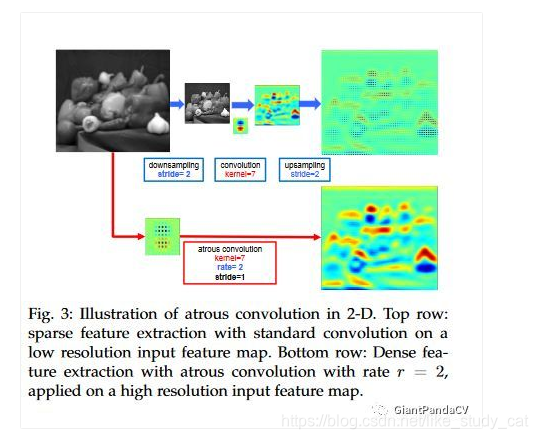
Fig.3中上分支是将输入图片下采样1/2后使用卷积核大小为7的标注卷积得到feature map后再上采样2倍得到结果。下分支是将原卷积函数中每个系数中间都插入0(rate=2),用空洞卷积在原图上直接进行卷积操作,这样省去了下采样和上采样的操作,而且计算量不变的情况下(卷积核中那些为0的系数在反向梯度计算中没有传递性),能得到更大的感受野,也就是说能获取到更多的密集特征,尤其是像素的边界信息,对比两个分支的输出可以得到印证。
从上面可以看到我们可以通过膨胀卷积的膨胀速率,随意控制特征图的感受野(FOV)大小。
ASPP模块
传统方法是把图像强行resize成相同的尺寸,但是这样会导致某些特征扭曲或者消失,这里联想到SIFT特征提取的时候用到过图像金字塔,将图像放缩到不同的尺度,再提取的SIFT特征点具有旋转,平移不变性。因此这里也是借鉴这种方式使用空间金字塔的方法,来实现对图像大小和不同长宽比的处理。这样产生的新的网络,叫做SPP-Net,可以不论图像的大小产生相同大小长度的表示特征。ASPP(多孔金字塔池化)就是通过不同的空洞卷积来对图像进行不同程度的缩放,得到不同大小的输入特征图,因为DeepLab的ASPP拥有不同rate的滤波器,再把子窗口的特征进行池化就生成了固定长度的特征表示。之前需要固定大小的输入图像的原因是全连接层需要固定大小。现在将SPP层接到最后一个卷积层后面,SPP层池化特征并且产生固定大小的输出,它的输出再送到全连接层,这样就可以避免在网络的入口处就要求图像大小相同。ASPP模块可以用下图表示:
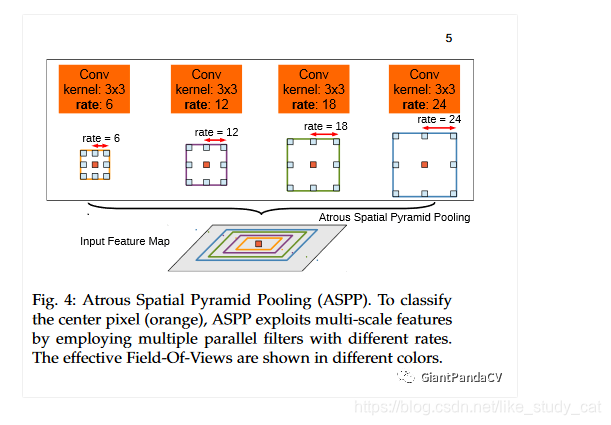
训练细节
论文在ImageNet预训练的VGG-16和ResNet-101网络上进行finetune,将输出的1000类改成语义分割数据集的分类数,COCO和VOC都是21类,损失函数是CNN的输出(原图1/8大小)特征图和GT(同样下采样到1/8)的交叉熵损失和,每个位置在损失函数中的权重是相等的,并且使用SGD优化算法,后处理过程仍然使用和DeepLab V1一样的全连接CRF来进一步确定像素边界和分割结果。在训练时,作者分享了三个关键技术。
一,数据增强,参考Semantic contours from inverse detectors》将VOC 2012的训练集由1464扩增到10582张。
二,初始学习率、动量以及CRF参数的选取都类似于DeepLabv1,通过调整膨胀速率来控制FOV(field-of-view),在DeepLab-LargeFOV上,作者对学习率下降策略进行了不同的尝试,相对step的测试,poly在Batch_size=30,迭代20000次时能在VOC2012验证集上达到65.88%的mIOU(未做CRF后处理)。
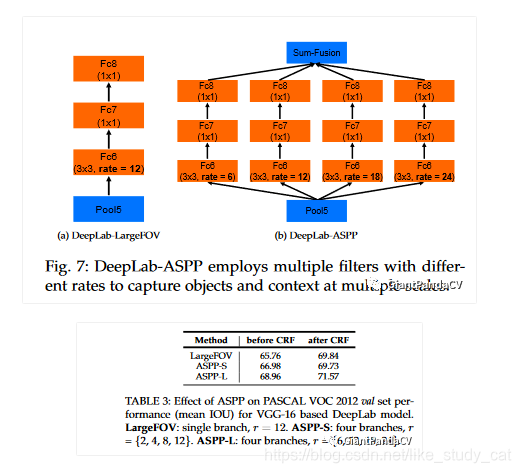
三,二提到了LargeFOV,LargeFOV是指采用膨胀速率r=12的膨胀卷积策略,作者在VGG-16的fc6采用该膨胀卷积,并将fc7和fc8改为1x1的全卷积,命名为DeepLab-LargeFOV,作为对比,同时在VGG-16的fc6-fc8层用四路采用不同膨胀速率的膨胀卷积作用于各自的fc6,在fc7和fc8同样采用全卷积策略,命名为DeepLab-ASPP,根据膨胀卷积r的不同组合,r={2,4,8,12}的称为DeepLab-ASPP-S,r={6,12,18,24}的称为DeepLab-ASPP-L,如下图分别为VGG16上的DeepLab-LargeFOV和DeepLab-ASPP示意图:
如果不经过CRF,DeepLab-ASPP-S的效果会比DeepLab-LargeFOV mIOU超1.22%,经过CRF后两个的准确率相似,而ASPP-L则经过CRF前和后都超过LargeFOV大概2-3个百分点,具体数据如表3。
除了这些工作,论文还尝试了在COCO数据集上进行了测试,mIOU可以达到77.69%,具体可以参考原文,这个算法也是达到了当时的SOAT。
后记
可以看到DeepLabv2仍然存在两个阶段,即DCNN+CRF,后面我们会介绍DeepLabV3扔掉CRF并且精度更高,请期待一下。
网络部分代码
地址:https://github.com/zhengyang-wang/Deeplab-v2–ResNet-101–Tensorflow/blob/master/network.py
import tensorflow as tf
import numpy as np
import six
"""
This script defines the segmentation network.
The encoding part is a pre-trained ResNet. This script supports several settings (you need to specify in main.py):
Deeplab v2 pre-trained model (pre-trained on MSCOCO) ('deeplab_resnet_init.ckpt')
Deeplab v2 pre-trained model (pre-trained on MSCOCO + PASCAL_train+val) ('deeplab_resnet.ckpt')
Original ResNet-101 ('resnet_v1_101.ckpt')
Original ResNet-50 ('resnet_v1_50.ckpt')
You may find the download links in README.
To use the pre-trained models, the name of each layer is the same as that in .ckpy file.
"""
class Deeplab_v2(object):
"""
Deeplab v2 pre-trained model (pre-trained on MSCOCO) ('deeplab_resnet_init.ckpt')
Deeplab v2 pre-trained model (pre-trained on MSCOCO + PASCAL_train+val) ('deeplab_resnet.ckpt')
"""
def __init__(self, inputs, num_classes, phase):
self.inputs = inputs
self.num_classes = num_classes
self.channel_axis = 3
self.phase = phase # train (True) or test (False), for BN layers in the decoder
self.build_network()
def build_network(self):
self.encoding = self.build_encoder()
self.outputs = self.build_decoder(self.encoding)
def build_encoder(self):
print("-----------build encoder: deeplab pre-trained-----------")
outputs = self._start_block()
print("after start block:", outputs.shape)
outputs = self._bottleneck_resblock(outputs, 256, '2a', identity_connection=False)
outputs = self._bottleneck_resblock(outputs, 256, '2b')
outputs = self._bottleneck_resblock(outputs, 256, '2c')
print("after block1:", outputs.shape)
outputs = self._bottleneck_resblock(outputs, 512, '3a', half_size=True, identity_connection=False)
for i in six.moves.range(1, 4):
outputs = self._bottleneck_resblock(outputs, 512, '3b%d' % i)
print("after block2:", outputs.shape)
outputs = self._dilated_bottle_resblock(outputs, 1024, 2, '4a', identity_connection=False)
for i in six.moves.range(1, 23):
outputs = self._dilated_bottle_resblock(outputs, 1024, 2, '4b%d' % i)
print("after block3:", outputs.shape)
outputs = self._dilated_bottle_resblock(outputs, 2048, 4, '5a', identity_connection=False)
outputs = self._dilated_bottle_resblock(outputs, 2048, 4, '5b')
outputs = self._dilated_bottle_resblock(outputs, 2048, 4, '5c')
print("after block4:", outputs.shape)
return outputs
def build_decoder(self, encoding):
print("-----------build decoder-----------")
outputs = self._ASPP(encoding, self.num_classes, [6, 12, 18, 24])
print("after aspp block:", outputs.shape)
return outputs
# blocks
def _start_block(self):
outputs = self._conv2d(self.inputs, 7, 64, 2, name='conv1')
outputs = self._batch_norm(outputs, name='bn_conv1', is_training=False, activation_fn=tf.nn.relu)
outputs = self._max_pool2d(outputs, 3, 2, name='pool1')
return outputs
def _bottleneck_resblock(self, x, num_o, name, half_size=False, identity_connection=True):
first_s = 2 if half_size else 1
assert num_o % 4 == 0, 'Bottleneck number of output ERROR!'
# branch1
if not identity_connection:
o_b1 = self._conv2d(x, 1, num_o, first_s, name='res%s_branch1' % name)
o_b1 = self._batch_norm(o_b1, name='bn%s_branch1' % name, is_training=False, activation_fn=None)
else:
o_b1 = x
# branch2
o_b2a = self._conv2d(x, 1, num_o / 4, first_s, name='res%s_branch2a' % name)
o_b2a = self._batch_norm(o_b2a, name='bn%s_branch2a' % name, is_training=False, activation_fn=tf.nn.relu)
o_b2b = self._conv2d(o_b2a, 3, num_o / 4, 1, name='res%s_branch2b' % name)
o_b2b = self._batch_norm(o_b2b, name='bn%s_branch2b' % name, is_training=False, activation_fn=tf.nn.relu)
o_b2c = self._conv2d(o_b2b, 1, num_o, 1, name='res%s_branch2c' % name)
o_b2c = self._batch_norm(o_b2c, name='bn%s_branch2c' % name, is_training=False, activation_fn=None)
# add
outputs = self._add([o_b1,o_b2c], name='res%s' % name)
# relu
outputs = self._relu(outputs, name='res%s_relu' % name)
return outputs
def _dilated_bottle_resblock(self, x, num_o, dilation_factor, name, identity_connection=True):
assert num_o % 4 == 0, 'Bottleneck number of output ERROR!'
# branch1
if not identity_connection:
o_b1 = self._conv2d(x, 1, num_o, 1, name='res%s_branch1' % name)
o_b1 = self._batch_norm(o_b1, name='bn%s_branch1' % name, is_training=False, activation_fn=None)
else:
o_b1 = x
# branch2
o_b2a = self._conv2d(x, 1, num_o / 4, 1, name='res%s_branch2a' % name)
o_b2a = self._batch_norm(o_b2a, name='bn%s_branch2a' % name, is_training=False, activation_fn=tf.nn.relu)
o_b2b = self._dilated_conv2d(o_b2a, 3, num_o / 4, dilation_factor, name='res%s_branch2b' % name)
o_b2b = self._batch_norm(o_b2b, name='bn%s_branch2b' % name, is_training=False, activation_fn=tf.nn.relu)
o_b2c = self._conv2d(o_b2b, 1, num_o, 1, name='res%s_branch2c' % name)
o_b2c = self._batch_norm(o_b2c, name='bn%s_branch2c' % name, is_training=False, activation_fn=None)
# add
outputs = self._add([o_b1,o_b2c], name='res%s' % name)
# relu
outputs = self._relu(outputs, name='res%s_relu' % name)
return outputs
def _ASPP(self, x, num_o, dilations):
o = []
for i, d in enumerate(dilations):
o.append(self._dilated_conv2d(x, 3, num_o, d, name='fc1_voc12_c%d' % i, biased=True))
return self._add(o, name='fc1_voc12')
# layers
def _conv2d(self, x, kernel_size, num_o, stride, name, biased=False):
"""
Conv2d without BN or relu.
"""
num_x = x.shape[self.channel_axis].value
with tf.variable_scope(name) as scope:
w = tf.get_variable('weights', shape=[kernel_size, kernel_size, num_x, num_o])
s = [1, stride, stride, 1]
o = tf.nn.conv2d(x, w, s, padding='SAME')
if biased:
b = tf.get_variable('biases', shape=[num_o])
o = tf.nn.bias_add(o, b)
return o
def _dilated_conv2d(self, x, kernel_size, num_o, dilation_factor, name, biased=False):
"""
Dilated conv2d without BN or relu.
"""
num_x = x.shape[self.channel_axis].value
with tf.variable_scope(name) as scope:
w = tf.get_variable('weights', shape=[kernel_size, kernel_size, num_x, num_o])
o = tf.nn.atrous_conv2d(x, w, dilation_factor, padding='SAME')
if biased:
b = tf.get_variable('biases', shape=[num_o])
o = tf.nn.bias_add(o, b)
return o
def _relu(self, x, name):
return tf.nn.relu(x, name=name)
def _add(self, x_l, name):
return tf.add_n(x_l, name=name)
def _max_pool2d(self, x, kernel_size, stride, name):
k = [1, kernel_size, kernel_size, 1]
s = [1, stride, stride, 1]
return tf.nn.max_pool(x, k, s, padding='SAME', name=name)
def _batch_norm(self, x, name, is_training, activation_fn, trainable=False):
# For a small batch size, it is better to keep
# the statistics of the BN layers (running means and variances) frozen,
# and to not update the values provided by the pre-trained model by setting is_training=False.
# Note that is_training=False still updates BN parameters gamma (scale) and beta (offset)
# if they are presented in var_list of the optimiser definition.
# Set trainable = False to remove them from trainable_variables.
with tf.variable_scope(name) as scope:
o = tf.contrib.layers.batch_norm(
x,
scale=True,
activation_fn=activation_fn,
is_training=is_training,
trainable=trainable,
scope=scope)
return o
class ResNet_segmentation(object):
"""
Original ResNet-101 ('resnet_v1_101.ckpt')
Original ResNet-50 ('resnet_v1_50.ckpt')
"""
def __init__(self, inputs, num_classes, phase, encoder_name):
if encoder_name not in ['res101', 'res50']:
print('encoder_name ERROR!')
print("Please input: res101, res50")
sys.exit(-1)
self.encoder_name = encoder_name
self.inputs = inputs
self.num_classes = num_classes
self.channel_axis = 3
self.phase = phase # train (True) or test (False), for BN layers in the decoder
self.build_network()
def build_network(self):
self.encoding = self.build_encoder()
self.outputs = self.build_decoder(self.encoding)
def build_encoder(self):
print("-----------build encoder: %s-----------" % self.encoder_name)
scope_name = 'resnet_v1_101' if self.encoder_name == 'res101' else 'resnet_v1_50'
with tf.variable_scope(scope_name) as scope:
outputs = self._start_block('conv1')
print("after start block:", outputs.shape)
with tf.variable_scope('block1') as scope:
outputs = self._bottleneck_resblock(outputs, 256, 'unit_1', identity_connection=False)
outputs = self._bottleneck_resblock(outputs, 256, 'unit_2')
outputs = self._bottleneck_resblock(outputs, 256, 'unit_3')
print("after block1:", outputs.shape)
with tf.variable_scope('block2') as scope:
outputs = self._bottleneck_resblock(outputs, 512, 'unit_1', half_size=True, identity_connection=False)
for i in six.moves.range(2, 5):
outputs = self._bottleneck_resblock(outputs, 512, 'unit_%d' % i)
print("after block2:", outputs.shape)
with tf.variable_scope('block3') as scope:
outputs = self._dilated_bottle_resblock(outputs, 1024, 2, 'unit_1', identity_connection=False)
num_layers_block3 = 23 if self.encoder_name == 'res101' else 6
for i in six.moves.range(2, num_layers_block3+1):
outputs = self._dilated_bottle_resblock(outputs, 1024, 2, 'unit_%d' % i)
print("after block3:", outputs.shape)
with tf.variable_scope('block4') as scope:
outputs = self._dilated_bottle_resblock(outputs, 2048, 4, 'unit_1', identity_connection=False)
outputs = self._dilated_bottle_resblock(outputs, 2048, 4, 'unit_2')
outputs = self._dilated_bottle_resblock(outputs, 2048, 4, 'unit_3')
print("after block4:", outputs.shape)
return outputs
def build_decoder(self, encoding):
print("-----------build decoder-----------")
with tf.variable_scope('decoder') as scope:
outputs = self._ASPP(encoding, self.num_classes, [6, 12, 18, 24])
print("after aspp block:", outputs.shape)
return outputs
# blocks
def _start_block(self, name):
outputs = self._conv2d(self.inputs, 7, 64, 2, name=name)
outputs = self._batch_norm(outputs, name=name, is_training=False, activation_fn=tf.nn.relu)
outputs = self._max_pool2d(outputs, 3, 2, name='pool1')
return outputs
def _bottleneck_resblock(self, x, num_o, name, half_size=False, identity_connection=True):
first_s = 2 if half_size else 1
assert num_o % 4 == 0, 'Bottleneck number of output ERROR!'
# branch1
if not identity_connection:
o_b1 = self._conv2d(x, 1, num_o, first_s, name='%s/bottleneck_v1/shortcut' % name)
o_b1 = self._batch_norm(o_b1, name='%s/bottleneck_v1/shortcut' % name, is_training=False, activation_fn=None)
else:
o_b1 = x
# branch2
o_b2a = self._conv2d(x, 1, num_o / 4, first_s, name='%s/bottleneck_v1/conv1' % name)
o_b2a = self._batch_norm(o_b2a, name='%s/bottleneck_v1/conv1' % name, is_training=False, activation_fn=tf.nn.relu)
o_b2b = self._conv2d(o_b2a, 3, num_o / 4, 1, name='%s/bottleneck_v1/conv2' % name)
o_b2b = self._batch_norm(o_b2b, name='%s/bottleneck_v1/conv2' % name, is_training=False, activation_fn=tf.nn.relu)
o_b2c = self._conv2d(o_b2b, 1, num_o, 1, name='%s/bottleneck_v1/conv3' % name)
o_b2c = self._batch_norm(o_b2c, name='%s/bottleneck_v1/conv3' % name, is_training=False, activation_fn=None)
# add
outputs = self._add([o_b1,o_b2c], name='%s/bottleneck_v1/add' % name)
# relu
outputs = self._relu(outputs, name='%s/bottleneck_v1/relu' % name)
return outputs
def _dilated_bottle_resblock(self, x, num_o, dilation_factor, name, identity_connection=True):
assert num_o % 4 == 0, 'Bottleneck number of output ERROR!'
# branch1
if not identity_connection:
o_b1 = self._conv2d(x, 1, num_o, 1, name='%s/bottleneck_v1/shortcut' % name)
o_b1 = self._batch_norm(o_b1, name='%s/bottleneck_v1/shortcut' % name, is_training=False, activation_fn=None)
else:
o_b1 = x
# branch2
o_b2a = self._conv2d(x, 1, num_o / 4, 1, name='%s/bottleneck_v1/conv1' % name)
o_b2a = self._batch_norm(o_b2a, name='%s/bottleneck_v1/conv1' % name, is_training=False, activation_fn=tf.nn.relu)
o_b2b = self._dilated_conv2d(o_b2a, 3, num_o / 4, dilation_factor, name='%s/bottleneck_v1/conv2' % name)
o_b2b = self._batch_norm(o_b2b, name='%s/bottleneck_v1/conv2' % name, is_training=False, activation_fn=tf.nn.relu)
o_b2c = self._conv2d(o_b2b, 1, num_o, 1, name='%s/bottleneck_v1/conv3' % name)
o_b2c = self._batch_norm(o_b2c, name='%s/bottleneck_v1/conv3' % name, is_training=False, activation_fn=None)
# add
outputs = self._add([o_b1,o_b2c], name='%s/bottleneck_v1/add' % name)
# relu
outputs = self._relu(outputs, name='%s/bottleneck_v1/relu' % name)
return outputs
def _ASPP(self, x, num_o, dilations):
o = []
for i, d in enumerate(dilations):
o.append(self._dilated_conv2d(x, 3, num_o, d, name='aspp/conv%d' % (i+1), biased=True))
return self._add(o, name='aspp/add')
# layers
def _conv2d(self, x, kernel_size, num_o, stride, name, biased=False):
"""
Conv2d without BN or relu.
"""
num_x = x.shape[self.channel_axis].value
with tf.variable_scope(name) as scope:
w = tf.get_variable('weights', shape=[kernel_size, kernel_size, num_x, num_o])
s = [1, stride, stride, 1]
o = tf.nn.conv2d(x, w, s, padding='SAME')
if biased:
b = tf.get_variable('biases', shape=[num_o])
o = tf.nn.bias_add(o, b)
return o
def _dilated_conv2d(self, x, kernel_size, num_o, dilation_factor, name, biased=False):
"""
Dilated conv2d without BN or relu.
"""
num_x = x.shape[self.channel_axis].value
with tf.variable_scope(name) as scope:
w = tf.get_variable('weights', shape=[kernel_size, kernel_size, num_x, num_o])
o = tf.nn.atrous_conv2d(x, w, dilation_factor, padding='SAME')
if biased:
b = tf.get_variable('biases', shape=[num_o])
o = tf.nn.bias_add(o, b)
return o
def _relu(self, x, name):
return tf.nn.relu(x, name=name)
def _add(self, x_l, name):
return tf.add_n(x_l, name=name)
def _max_pool2d(self, x, kernel_size, stride, name):
k = [1, kernel_size, kernel_size, 1]
s = [1, stride, stride, 1]
return tf.nn.max_pool(x, k, s, padding='SAME', name=name)
def _batch_norm(self, x, name, is_training, activation_fn, trainable=False):
# For a small batch size, it is better to keep
# the statistics of the BN layers (running means and variances) frozen,
# and to not update the values provided by the pre-trained model by setting is_training=False.
# Note that is_training=False still updates BN parameters gamma (scale) and beta (offset)
# if they are presented in var_list of the optimiser definition.
# Set trainable = False to remove them from trainable_variables.
with tf.variable_scope(name+'/BatchNorm') as scope:
o = tf.contrib.layers.batch_norm(
x,
scale=True,
activation_fn=activation_fn,
is_training=is_training,
trainable=trainable,
scope=scope)
return o














 1585
1585











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









