







这里简单介绍下ARMA模型:
- 在生产和科学研究中,对某一个或者一组变量 x(t)x(t) 进行观察测量,将在一系列时刻
t1,t2,⋯,tn
t
1
,
t
2
,
⋯
,
t
n
所得到的离散数字组成的序列集合,称之为时间序列。
时间序列分析是根据系统观察得到的时间序列数据,通过曲线拟合和参数估计来 - 建立数学模型的理论和方法。
- 时间序列建模基本步骤:
- 获取被观测系统时间序列数据;
- 对数据绘图,观测是否为平稳时间序列;对于非平稳时间序列要先进行d阶差分运算,化为平稳时间序列;
- 经过第二步处理,已经得到平稳时间序列。要对平稳时间序列分别求得其自相关系数ACF 和偏自相关系数PACF ,通过对自相关图和偏自相关图的分析,得到最佳的阶层 p 和阶数 q
- 由以上得到的d、q、p得到ARIMA模型。然后开始对得到的模型进行模型检验。
具体理论知识可参考:
https://blog.csdn.net/u010414589/article/details/49622625
https://blog.csdn.net/wmn7q/article/details/70301215
http://www.360doc.com/content/18/0129/18/29308714_726199415.shtml
但下面的代码全部是基于《随机过程》——汪荣鑫,而编写的代码。
有些不足的地方会给出注释。
1. 首先是第一个functions_related.py文件,里面是会用到的函数:
# -*- coding: utf-8 -*-
# 差分处理
def difference(dataset, interval=1):
diff = list()
for i in range(interval, len(dataset)):
value = dataset[i] - dataset[i - interval]
diff.append(value)
return diff
# 逆差分处理
def difference_inv(data_diff,dtafir,interval=1):
diff_inv = dtafir
for i in range(len(data_diff)):
value = diff_inv[i]+data_diff[i]
diff_inv.append(value)
return diff_inv
# 自协方差函数(k值默认为15),dta的下标是从0~原始数据长度-差分阶数-1(30个数据一阶差分时:0~28)
def self_covariance(dta,k):
for kk in range(k+1):
sum=0
for j in range(dta_len-kk):
#print j,j+kk
sum=sum+dta[j]*dta[j+kk]
gamma.append(1/float(len(dta))*sum)
#print 'gamma:',gamma
return gamma
# 样本自相关函数
def autocorrelation(gamma):
rou=[i/gamma[0] for i in gamma]
return rou
# 样本偏相关函数
def partial_correlation(rou,k):
fai_ex=[1]
fai=[[0]*(k+1) for i in range(k+1)] # 初始化整个数组
fai[0][0]=1
fai[1][1]=rou[1] # k=1时,fai[1][1]=rou[1]
fai_ex.extend([fai[1][1]])
for kk in range(1,k): # 当kk=1,2,3....k
# 计算fai[k+1][k+1]
sum_up=0
sum_down=0
for j in range(1,kk+1): # j=1,2,...k
sum_up=sum_up+rou[kk+1-j]*fai[kk][j]
sum_down=sum_down+rou[j]*fai[kk][j]
fai[kk+1][kk+1]=(rou[kk+1]-sum_up)/(1-sum_down)
fai_ex.extend([fai[kk+1][kk+1]])
for j in range(1,kk+1): # j=1,2,...k
fai[kk+1][j]=fai[kk][j]-fai[kk+1][kk+1]*fai[kk][kk-j+1] # 计算fai[k+1][j]
return fai_ex,fai
# AR(p)模型参数估计
def model_ar(p,fai):
fai_mao=[0]
sum_sigma=0
# 计算fai的参数值
for j in range(1,p+1):
fai_mao.extend([fai[p][j]])
sum_sigma=sum_sigma+fai_mao[j]*gamma[j]
# 计算白噪声方差
sigma2_AR=gamma[0]-sum_sigma
return fai_mao,sigma2_AR
# MA(1)模型参数估计
def model_ma(rou,q=1):
tt=1+pow((1-4*rou[1]*rou[1]),0.5)
theta_1=(-2*rou[1])/tt
sigma2_MA=rou[0]*tt/2
return theta_1,sigma2_MA
# ARMA(p,1)参数估计
def model_arma(p,q,fai_mao):
#fai_mao,sigma2_ar=ar_pre.model_ar(p)
gammak_w=[0,0]
# 得到gamma_0_w
sum_L=0
sum_last=0
for L in range(1,p+1):
sum_j=0
for j in range(1,p+1):
sum_j=sum_j+fai_mao[L]*fai_mao[j]*gamma[abs(L-j)]
sum_L= sum_L+sum_j
for j in range(1,p+1):
sum_last=sum_last+fai_mao[j]*gamma[abs(-j)]+fai_mao[j]*gamma[j]
gammak_w[0]=gamma[0]+sum_L-sum_last
# 得到gamma_1_w
sum_L=0
sum_last=0
for L in range(1,p+1):
sum_j=0
for j in range(1,p+1):
sum_j=sum_j+fai_mao[L]*fai_mao[j]*gamma[abs(L-j+1)]
sum_L= sum_L+sum_j
for j in range(1,p+1):
sum_last=sum_last+fai_mao[j]*gamma[abs(1-j)]+fai_mao[j]*gamma[1+j]
gammak_w[1]=gamma[1]+sum_L-sum_last
rouk_w=gammak_w[1]/gammak_w[0]
theta1_ARMA=(-2*rouk_w)/(1+pow(1-4*rouk_w*rouk_w,0.5))
return theta1_ARMA
##########################################################################
#(dta,L,k)
def func(dta,L,k):
global dta_len,gamma,diff_n
diff_n=1
gamma=[]
# 计算差分运算
dta_diff=difference(dta, diff_n)
dta_len=len(dta_diff) # 数据长度
mean_dta=1/float(dta_len)*sum(dta_diff) # 求均值
dta_w=[i-mean_dta for i in dta_diff] # 样本变成W_t
# 计算自协方差
gamma=self_covariance(dta_w,k)
#print 'gamma:',gamma
# 计算自相关函数
rou=autocorrelation(gamma)
#print 'rou:',rou
# 计算偏相关函数
fai_ex,fai=partial_correlation(rou,k)
#print 'fai_ex,fai:',fai_ex,fai
print '(fai_ex,fai) is ok!!'
return dta_diff,dta_len,gamma,mean_dta,dta_w,rou,fai_ex,fai
函数有计算样本的差分函数,样本协方差函数,样本自相关函数,样本偏相关函数,逆差分处理函数。还有AR(p),MA(1),ARMA(p,1)模型的参数估计函数。
2. 下面的一个是pre_interface.py的文件,该文件里是定义的一些调用接口:
# -*- coding: utf-8 -*-
import functions_related as fr
# AR(P)模型预测未来7天的数量和(dta,p,L,k)
def ar_pre(dta,p,L,k):
# 得到AR模型
fai_mao,sigma2_ar=fr.model_ar(p,fai)
len_pre=dta_len-1
dta_pre=dta_diff[:] # dta_pre的改变不会影响fr.dta_diff原数据
fai_sum=0
for i in range(1,p+1):
fai_sum=fai_sum+fai_mao[i]
theta0_ARpre=mean_dta*(1-fai_sum)
for LL in range(1,L+1):
z_k=0
for pp in range(1,p+1):
z_k=z_k+fai_mao[pp]*dta_pre[len_pre+LL-pp] # 数据是从后往前的
dta_pre.extend([theta0_ARpre+z_k])
# 逆差分处理(差分数据,原数据的前n阶个,差分阶数)
AR_pre_inv=fr.difference_inv(dta_pre,dta[0:fr.diff_n],fr.diff_n)
return AR_pre_inv[dta_len+1:],sum(AR_pre_inv[dta_len+1:]),AR_pre_inv
# ARMA(P,1)模型预测未来7天的数量和(dta,p,q,L,k)
def arma_pre(dta,p,q,L,k):
#global fai_mao,sigma2_ar
fai_mao,sigma2_ar=fr.model_ar(p,fai)
# 得到ARMA(P,1)模型
theta1_ARMA=fr.model_arma(p,q,fai_mao)
z=dta_diff[:]
len_z=dta_len-1
alpha=[0]
mea=mean_dta
# 计算theta0初始值
fai_sum=0
for i in range(1,p+1):
fai_sum=fai_sum+fai_mao[i]
theta0_ARMApre=mean_dta*(1-fai_sum)
# 计算alpha_k
for k in range(1,dta_len):
sum_fai=0
for pp in range(1,p+1):
if k-pp-1<0:
sum_fai=sum_fai+fai_mao[pp]*mea
else:
sum_fai=sum_fai+fai_mao[pp]*z[k-pp-1]
alpha_tt=-theta0_ARMApre+z[k-1]-sum_fai+theta1_ARMA*alpha[k-1]
alpha.extend([alpha_tt])
sum_k1=0
for pp in range(1,p+1):
sum_k1=sum_k1+fai_mao[pp]*z[len_z+1-pp]
z_k1=theta0_ARMApre+sum_k1-theta1_ARMA*alpha[-1]
z.extend([z_k1])
for LL in range(2,L+1):
sum_pp=0
for pp in range(1,pp+1):
sum_pp=sum_pp+fai_mao[pp]*z[len_z+LL-pp]
z.extend([theta0_ARMApre+sum_pp])
# 逆差分处理(差分数据,原数据的前n阶个,差分阶数)
ARMA_pre_inv=fr.difference_inv(z,dta[0:fr.diff_n],fr.diff_n)
return ARMA_pre_inv[dta_len+1:],sum(ARMA_pre_inv[dta_len+1:]),ARMA_pre_inv
# MA(1)模型预测预测未来7天的数量和(dta,q,L,k)
def ma_pre(dta,q,L,k):
# 得到MA(1)模型
theta_1,sigma2_ma=fr.model_ma(rou,1)
z=dta_diff[:]
tt=dta_diff[0]-mean_dta
alpha=[0,tt]
for t in range(2,fr.dta_len):
mm=dta_diff[t-1]-mean_dta+theta_1*alpha[t-1]
alpha.extend([mm])
z.extend([mean_dta-theta_1*alpha[-1]])
z.extend([mean_dta]*(L-1))
# 逆差分处理(差分数据,原数据的前n阶个,差分阶数)
MA_pre_inv=fr.difference_inv(z,dta[0:fr.diff_n],fr.diff_n)
return MA_pre_inv[dta_len+1:],sum(MA_pre_inv[dta_len+1:]),MA_pre_inv
#预测接口 (dta,model,p,q=1,L=7,k=39)
def interface_pre(dta,model,p,q=1,L=7,k=20):
global dta_diff,dta_len,gamma,mean_dta,dta_w,rou,fai_ex,fai,AR_pre_inv
dta_diff,dta_len,gamma,mean_dta,dta_w,rou,fai_ex,fai=fr.func(dta,L,k)
if model==1:
AR_pre7,AR_sum7,AR_pre_inv=ar_pre(dta,p,L,k)
return AR_pre7,AR_sum7,AR_pre_inv
elif model==2:
MA_pre7,MA_sum7,MA_pre_inv=ma_pre(dta,q,L,k)
return MA_pre7,MA_sum7,MA_pre_inv
else:
ARMA_pre7,ARMA_sum7,ARMA_pre_inv=arma_pre(dta,p,q,L,k)
return ARMA_pre7,ARMA_sum7,ARMA_pre_inv
我这里的MA模型只计算了q=1时的参数,因为多阶的需要计算非线性方程组。这里没有找到好的算法,所以就只用了一阶的,一阶的比较好计算,直接就是解析解。
3. 下面的文件是一个简单的here_start.py数据输入接口文件:
# -*- coding: utf-8 -*-
import pre_interface as pre
global ARMA_pre7,ARMA_sum7,dta
dta=[10930,10318,10595,10972,7706,6756,9092,10551,9722,10913,11151,8186,6422,
6337,11649,11652,10310,12043,7937,6476,9662,9570,9981,9331,9449,6773,6304,9355,
10477,10148,10395,11261,8713,7299,10424,10795,11069,11602,11427,9095,7707,10767,
12136,12812,12006,12528,10329,7818,11719,11683,12603,11495,13670,11337,10232,
13261,13230,15535,16837,19598,14823,11622,19391,18177,19994,14723,15694,13248,
9543,12872,13101,15053,12619,13749,10228,9725,14729,12518,14564,15085,14722,
11999,9390,13481,14795,15845,15271,14686,11054,10395]
########################################################################################
# 预测(dta,model,p,q=1,L=7,k=39)
print 'the len of data:',len(dta)
ARMA_pre7,ARMA_sum7,ARMA_pre_inv=pre.interface_pre(dta,3,15,1,7,20)
print 'ARMA:',ARMA_pre7,ARMA_sum7
print 'the len of data:',len(dta)
'''
AR_pre7,AR_sum7,AR_pre_inv=pre.interface_pre(dta,1,5,1,7,39)
#print AR_pre7,AR_sum7,AR_pre_inv
print 'AR:',AR_pre7,AR_sum7
MA_pre7,MA_sum7,MA_pre_inv=pre.interface_pre(dta,2,3,1,7,9)
print MA_pre7,MA_sum7,MA_pre_inv
'''
- 只需要在该文件进行模型和p,q值的修改,便于调用。至此所有的代码基本完成,但缺陷就是没有p,q值的合理选择,需要自己设定。还有就是缺少模型的验证过程,有待改善,因为上面的代码都是基于python的内置库进行的编写,没有用第三方库,所以p,q值选择和模型验证有一定的难度,所以这里没有给出代码。
- 还有就是这里用的是混合模型,也就是ARIMA(15,1)模型预测了未来7天的值,也可以在接口中进行模型的选择和p,q值的设定(手动)。
- 最后一点需要说明的是这里其实是ARIMA的模型,因为用到了差分的过程,但开始写代码的时候用了ARMA这个变量,后来也就没有改过来,这里注意下就好。
4. 可视化
# -*- coding: utf-8 -*-
import matplotlib.pyplot as plt
import statsmodels.api as sm
import pandas as pd
import here_start as hs
import functions_related as fr
import pre_interface as pre_face
k=fr.diff_n # 差分阶数
# 绘制样本图
fig = plt.figure(figsize=(7,5))
dta_1=pd.Series(hs.dta)
p1=str(len(hs.dta))
dta_1.index = pd.Index(sm.tsa.datetools.dates_from_range('1',p1))
dta_1.plot(figsize=(7,5))
# 绘制一阶差分图
fig = plt.figure(figsize=(7,5))
dta_2=pd.Series(pre_face.dta_diff)
p2=str(len(hs.dta)-k)
dta_2.index = pd.Index(sm.tsa.datetools.dates_from_range('1',p2))
dta_2.plot()
plt.grid(True, linestyle = "-.", color = "r", linewidth = "1")
# 绘制预测图(还原差分)
dta_pre_inv=hs.ARMA_pre_inv[:]
fig = plt.figure(figsize=(7,5))
dta_3=pd.Series(dta_pre_inv)
p4=str(len(hs.dta)+7)
dta_3.index = pd.Index(sm.tsa.datetools.dates_from_range('1',p4))
dta_3.plot()
plt.grid(True, linestyle = "-.", color = "r", linewidth = "1")
以上代码整个的运行也是从这个py文件开始的,当然可以改成自己需要的模式。这里只所以这样写是为了方便别人调用。这里可视化的目的是为了验证下整个算法模型的正确性,当然这个py文件用了第三方库。
运行结果:
the len of data: 90
(fai_ex,fai) is ok!!
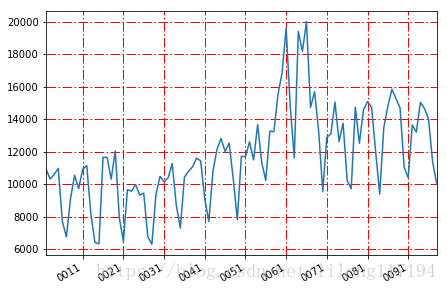
ARMA: [13638.509545077477, 13200.868625007959, 15035.380054400874, 14658.180516177894, 14010.39291430667, 11371.456018370734, 10042.910121382312] 91957.6977947
the len of data: 90这里是未来7天的各个数量,和总数。
原始数据图:
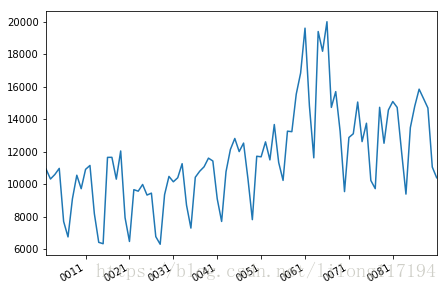
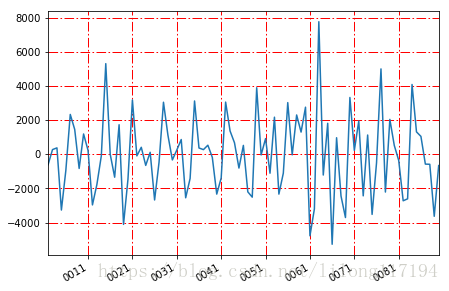
一阶差分图:
原始数据加7天预测图:
这里给出的代码很简陋,既没有优化,也没有模型验证,但基础的模型构建是正确的,供参考学习。
5. 总结
之所以这里用python内置库编写,是由于我参加2018年华为软件精英挑战赛,赛题要求不能使用第三方库,所以只能从头到尾手写代码。这里只是其中的一个预测模型,还写了其他的几个模型,但比较简单,这里不再贴出来了。我负责的是预测部分的代码,我队友负责的是放置部分。关于模型的部分还有调参,数据预处理,这里就不细说了,东西很多。
由于各种原因这次比赛成绩不太好,但通过参加比赛,还是学到了很多东西,代码优化,调bug。。。觉得还是有很多东西需要学习的。














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









