






本文是pprof工具的文档readme的翻译
https://github.com/google/pprof/blob/master/doc/README.md
pprof
pprof是一个用来可视化与分析性能剖析数据的工具。
pprof会以profile.proto格式读取性能采样数据集,并生成报告来可视化及帮助分析这些数据。它可以生存文本的和图像化的报告(通过使用dot可视化包)。
profile.proto是一个描述调用栈和符号化信息的集合的pb文件。通常用来描述来自统计剖析的采样调用栈集合。其格式描述在proto/profile.proto文件。至于pb,详见https://developers.google.com/protocol-buffers
性能剖析可以读自一个本地文件,或者读自http。同种类型的多个剖析可以被聚合和比较。
如果剖析采样包含机器地址,pprof可以通过使用原生binutils工具(addr2line和nm)来符号化它们。
pprof 性能剖析
pprof运行在profile.proto格式的数据上。每个性能剖析都是一个采样集合,集合中每个采样都关联到位置层级中的一个点,一个或多个数值,以及一个标签集。通常,这些剖析代表着一个程序通过统计采样收集的数据,所以每个采样描述了一个程序调用栈以及在一个位置采集的数值。pprof与性能剖析语义上无关,所以也可以用于其他用途。对pprof生成的报告的解释依赖于性能剖析源的语义定义。
使用模式
有两种不同的使用pprof的方式。
生成报告
如果在命令行中输入报告格式:
pprof [options] source
pprof将会启动一个交互式shell,用户可以在其中输入命令。输入help可以获得在线帮助。
Web接口
如果在命令行指定一个 主机:端口号:
pprof -http=[host]:[port] [options] source
pprof将会在指定端口上处理HTTP请求。在浏览器上访问对应端口的http url(典型地是 http://<host>:<port>/)来看这个接口。
细节
pprof的目标是生成性能剖析的一个报告。这报告生成自一个位置分层,这是从性能剖析采样中重筑出来的。每个位置都包含两个值:
- flat:位置自身的值
- cum:位置的值加上他所有后代的值。
包含一个位置多次的采样(比如,对于递归函数)对于每个位置只会计算一次。
选项
选项是用来配置一个报告的内容。每个选项都有一个值,可以是布尔值,数字值,或者字符串。尽管只能指定一种格式,大部分选项都可以被独立设置。
这里是一些常见的选项:
- -flat [默认],-cum:分别指在文本报告上基于它们的值或累加值来排列。
- -functions [默认],-filefunctions,-files,-lines,-addresses:使用指定粒度生成报告。
- -noinlines:把内联函数的属性算在他们的首个非内联调用者。例如,一个像
pprof -list foo -noinlines profile.pb.gz这样的命令可用于生成带注释的源列表,将内联函数中的指标归因于外联调用行。 - -nodecount= int:报告中的最大实体数量。pprof将仅打印这么多个实体,并使用启发式方法来选择截断哪些实体。
- -focus= regex:仅包含 包含与regex匹配的报告实体的采样。
- -ignore= regex:排除 包含与regex匹配的报告实体的采样。
- -show_from= regex:不要在第一个匹配regex的条目上方显示实体。
- -show= regex:仅显示匹配regex的实体
- -hide= regex:不要展示匹配regex的实体
剖析文件中的每个采样都可能包含许多值,这些值代表着关联到采样的不同实体。pprof报告包含一个单采样值,约定上是指定在报告中的最后一个。sample_index=选项选择使用哪个值,可以设为一个数字(从0到values的数量-1)或者设为采样值的名字。
采样值是带有单位的数字值。如果pprof可以识别这些单位,它在可视化时会尝试将值缩放到合适的单位。使用unit=选项可以强制使用特定单位。例如,unit=sec会强制所有时间值以秒为单位来报告。pprof认得大部分常见时间和内存大小单位。
标签过滤
剖析文件中的采样可能是带有标签的。这些标签有一个名字和值;值可以是数字或字符串。pprof可以使用-tagfocus和-tagignore选项来从剖析文件中基于标签筛选采样。
通常,这些选项是按这样运作的:
- -tagfocus=regex 或 -tagfocus=range:筛选那些拥有标签符合正则表达式或者在指定范围内的采样。
- -tagignore=regex 或 -tagignore=range:排除那些拥有标签符合正则表达式或者在指定范围内的采样。
当使用-tagfocus和-tagignore时,正则表达式会与每个标签的值做比较。如果指定的值为 regex1, regex2,那么只有那些一个标签匹配regex1,一个标签匹配regex2的采样会被保留。
除了能够基于标签值进行过滤,还可以指定特定标签为特定值,像这样-tagfocus=tagName=value。这里,tagName必须精确匹配标签的名字,值可以是正则或者范围。如果你指定值为regex1,regex2,那么(指定标签的)标签值匹配regex1或者regex2的就会命中。
这里是一些使用tagfocus的示例:
-tagfocus 128kb:512kb筛选那些拥有在指定范围内内存值的任意数字值标签的采样-tagfocus mytag=128kb:512kb筛选那些拥有数字标签mytag,内存值在指定范围内的采样。没有-tagfocus mytag=128kb:512kb,16kb:32kb或者-tagfocus mytag=128kb:512kb,mytag2=128kb:512kb这样的用法。对于数字标签只能是单个值或者范围。-tagfocus someregex筛选那些拥有tagName:tagValue字符串匹配正则表达式的数字标签的采样。未来会改成筛选拥有tagValue字符串匹配正则表达式的数字标签的采样。-tagfocus mytag=myvalue1,myvalue2匹配那些拥有两个标签值之一的。
-tagignore的运作方式很相似,只是它是抛弃匹配的采样,而不是保留它们。
如果-tagignore和-tagfocus表达式(不管是正则还是范围)同时匹配一个采样,这个采样会被抛弃。
文本报告
pprof文本报告以文本格式展示位置分级关系。
- -text:打印位置,每行一个,包括值和累加值。
- -tree:打印每个位置时把父路径和子路径都打出来。
- -peek= regex:打印每个位置时把其所有的父路径和子路径都打出来,不进行截断。
- -traces:每行打印采样时带一个位置。
图像报告
pprof 可以以DOT格式生成图像报告并使用graphviz包将其转换为多种格式。
这些报告会以图像形式展示位置层级,每个报告实体都是一个节点。使用启发式算法来移走节点以限制图像的大小,可以使用nodecount选项来控制。
- -dot:以.dot格式生成一个报告。所有其他格式都是从这个生成出来的。
- -svg:以SVG格式生成一个报告。
- -web:在一个临时文件上以SVG格式生成一个报告并打开一个网页浏览器浏览它。
- -png、-jpg、-gif、-pdf:以这些格式生成一个报告。
理解调用图(Callgraph)
- 节点颜色:
- 大的正累积值是红色的
- 大的负累积值是绿色的
- 接近于零的累积值是灰色的。
- 节点字体大小:
- 较大的字体大小代表较大的绝对值
- 较小的字体大小代表较小的绝对值
- 边的宽度
- 边越厚表示这个路径上使用了越多资源
- 边越薄表示这个路径上使用了越少资源
- 边的颜色
- 大的正值是红色
- 大的负值是绿色
- 接近于0的值是灰色
- **虚线边:**两个连接的位置之间移除了一些位置
- **实线边:**一个位置直接调用另一个
- "(内联)"边标记调用被内联进调用方了。
我们看看以下示例图:
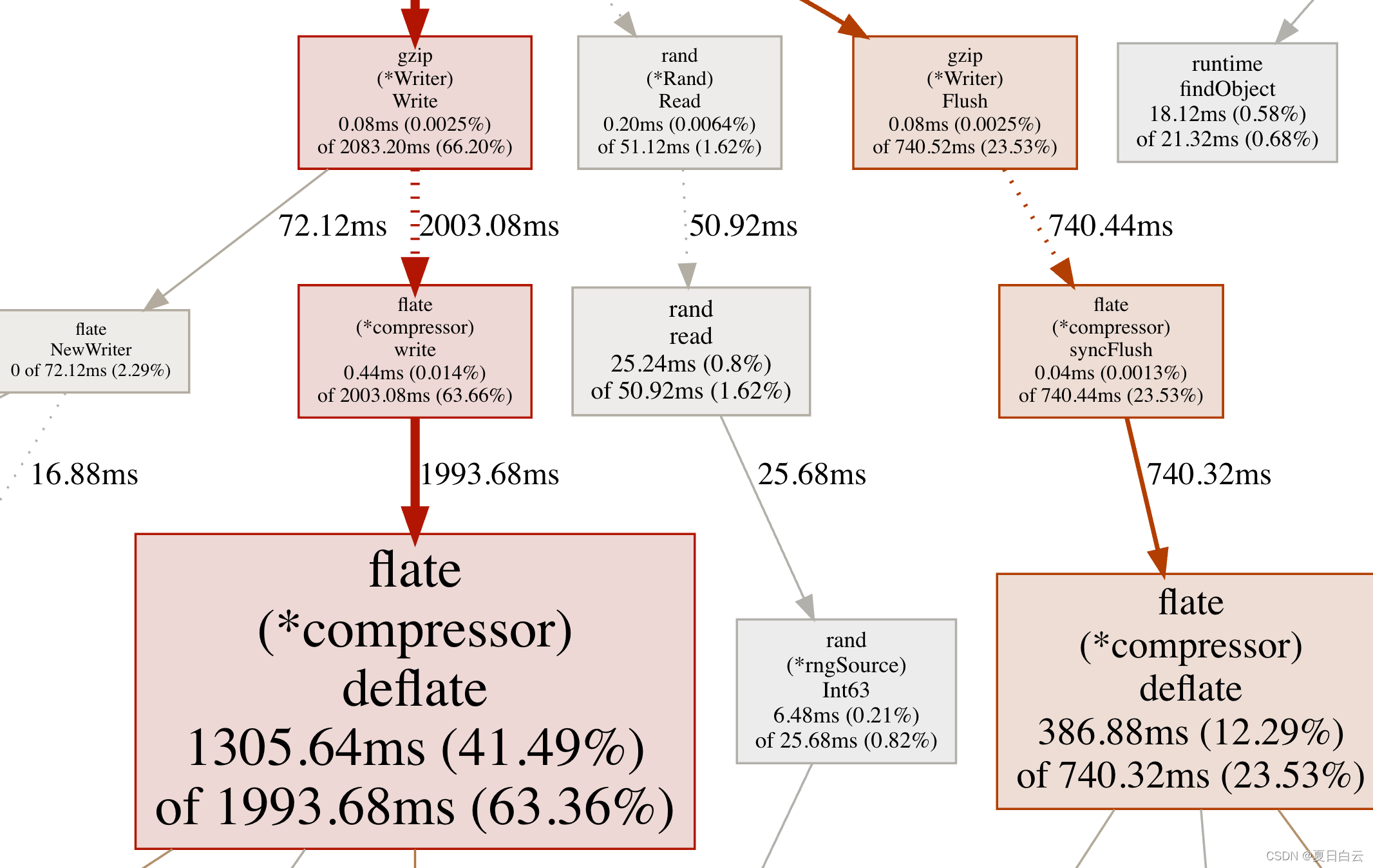
- 对于节点:
(*Rand).Read有一个小值和一个小累积值,因为字体很小,并且节点是灰色的。(*compressor).deflate有一个大值和大的累积值,因为字体很大,并且节点是红色的。(*Writer).Flush有一个小值和大的累积值,因为字体小,节点是红色。
- 对于边:
(*Writer).Write和(*compressor).write之间的边:- 由于它是一个虚线边,它们两之间移掉了一些节点
- 由于它是粗的红色边,这两个节点间的调用栈用到了较多的资源
(*Rand).Read和read之间的边:- 由于它是一个虚线边,它们两之间移掉了一些节点
- 由于它是细的灰色的,这两个节点间的调用栈用到了较少的资源
read和(*rngSource).Int63之间的边:- 由于它是一个实线边,它们两之间没有其他节点(即,它是一个直接调用)。
- 由于它是细的灰色的,这两个节点间的调用栈用到了较少的资源
注释代码
pprof还可以生成带注释源的报告,其中包含与之关联的示例。对这个,二进制文件或者源文件必须本地可得,剖析文件必须包含带有合适等级细节的数据。
pprof将在它当前工作路径和子路径下寻找源文件。pprof将在$PPROF_BINARY_PATH环境变量指定的路径下寻找二进制文件,默认是$HOME/pprof/binaries(Windows下是%USERPROFILE%\pprof\binaries)。它将通过名字寻找二进制文件。如果剖析文件包含链接器构建Id们,它还会在以构建Id命名的路径下搜索它们。
pprof使用binutils工具来校验和反汇编二进制文件。默认地,它会在当前路径下搜索这些工具,但是它也可以在环境变量$PPROF_TOOLS指向地路径下搜索它们。
- **-list= regex:**生成一个注释源,列出匹配 regex的函数,每个源行带着值或者累积值。
- -**disasm= regex:**为匹配regex的函数们生成一个带注释的反汇编的列表
- **-weblist= regex:**为匹配regex的函数们生成一个结合源文件/汇编的带注释的列表,并启动一个网页浏览器来展示它。
对比剖析文件
给两个兼容的类型的剖析文件(比如,两个heap剖析文件),pprof可以将两个文件相减。pprof有两个相关选项,可以用来指定一个剖析文件的文件名或者URL来被源剖析文件减。
- **diff_base= profile:**比较两个剖析文件时很有用。输出中的百分比是相对于diff base(差分基底)文件的总采样的。
- **-base= profile:**当需要将同一个程序不同时间采集的两个累积剖析文件做差分时有用,累积剖析文件如golang block profile。当比较采集自同一程序的不同累积剖析文件时,输出中的百分比是相对于 基剖析文件和源剖析文件的总值差 的。
当一个基剖析文件通过-diff_base或者-base选项给出时,可以使用**-normalize**标志。这个标志会缩放源剖析文件,以使得在从源剖析文件中减去基剖析文件之前,源剖析文件中的采样总数等于基剖析文件中的样本总数。这样可以用来确定两个剖析文件的相对差值。例如,在特定函数上哪个剖析文件的CPU使用时间有更大的百分比。
当使用**-diff_base**选项时,一些报告实体可能会有负值。如果合并的剖析文件输出为pb格式,diff base剖析文件中的所有采样将带有一个标签,键为"pprof::base",值为"true"。如果后面要用pprof来看合并的剖析文件,它会表现得仿佛源剖析文件和基剖析文件是被分别传入的。
当使用**-base**选项来将同一个程序不同时间采集的两个累积剖析文件做差分时,百分比是相对于 基剖析文件和源剖析文件的总值差 的,所有的值都是正值。一般情况下,当在地址级别聚合时,一些报告实体可能有负值,百分比将相对于所有采样的绝对值的总和。
获取剖析文件
pprof可以从一个文件中,或者直接从http或https的URL上获得剖析文件。它的原生格式是gzip压缩的profile.proto文件,但是也可以接受由gperftools生成的一些遗留格式。
当从一个URL中获取时,pprof接受以下选项来指定要等待这个剖析文件多久:
- **-seconds= int:**让pprof以指定的秒为单位的时间间隔请求一个剖析文件。仅对于基于消逝的时间的剖析文件的场景有意义,比如CPU剖析文件。
- **-timeout= int:**当从http上获取剖析一个文件时,让pprof等待指定的超时时间。如果没有指定,pprof会启发式地决定一个合理的超时时间。
pprof还接受些其他选项让用户能够指定TLS证书,当从受保护的网络端点获取或符号化剖析文件时需要用到。关于生成证书的信息,详见:https://docs.docker.com/engine/security/https/。
- **-tls_cert= /path/to/cert:**指定在获取或符号化剖析文件时要用到的包含TLS客户端证书的文件。
- **-tls_key= /path/to/key:**指定在获取或符号化剖析文件时要用到的包含TLS私钥的文件。
- **-tls_ca= /path/to/ca:**指定在获取或符号化剖析文件时要用到的包含证书授权的文件。
pprof还支持在收集或符号化剖析文件时跳过验证服务端的证书链和主机名。为了跳过这个验证,在URL中要使用“https+insecure”替换“https”。
如果指定了多个剖析文件,pprof将获取所有文件并合并它们。这可以用来结合分布式任务中多进程收集的剖析文件。剖析文件可以来自不同的程序,但是必须是兼容的(比如,CPU剖析文件不能和heap剖析文件结合)。
符号化
pprof可以增加符号信息到一个收集时仅带有地址信息的剖析文件上。这对于编译型语言的剖析文件很有用,在编译型语言中,在剖析源文件中包含函数名或者源定位可能很难,甚至做不到。
pprof可以通过使用binutils工具检验二进制文件来本地提取符号信息,或者也可以请求提供符号化接口的任务。
pprof默认会尝试符号化剖析文件,它的-symbolize选项提供了一些在符号化上的控制:
- **-symbolize=none:**禁用pprof的符号化
- **-symbolize=local:**仅尝试使用binutils工具从本地二进制文件符号化剖析文件。
- **-symbolize=remote:**仅尝试联系运行中的任务的符号化句柄来符号化。
对于本地符号化,pprof将在剖析文件指定的路径上寻找二进制文件,然后在环境变量$PPROF_BINARY_PATH指定的路径上搜索。同样,主二进制文件的名字可以作为其第一个参数直接传给pprof来覆写剖析文件的主二进制文件的名字和位置,像这样:
pprof /path/to/binary profile.pb.gz
默认的,pprof会尝试demangle和简化C++名字以提供可读的名字。它会激进地丢掉模版和函数参数。这可以通过-symbolize=demangle选项来控制。注意,对于远程符号化,符号化句柄可能不会提供mangled名字。
- **-symbolize=demangle=none:**不要做任何demangling。直接展示mangled名字(如有)。
- -symbolize=demangle=full: Demangle,不要做任何的符号化。直接展示完整的demangled名字(如有)。
- -symbolize=demangle=templates: Demangle,截断函数参数,但不截断模版参数。
Web接口
当用户(通过在命令行上给出-http=[host]:[port]参数)请求一个web接口,pprof会启动一个web服务器并打开浏览器窗口指向那个服务器。服务器提供的web接口允许用户以多种格式交互式地浏览剖析数据。
展示页面的顶部是一个header包含一些按钮和菜单。
配置
Config菜单允许用户保存当前的详尽配置(例如:焦点和隐藏列表)为一个命名的配置。保存好的配置可以之后被重新加载。Config菜单包含:
Save as …:会展示一个弹框,用户可以在其中输入配置的名字。当前的详尽配置会被保存在指定名字下。
Default:通过删除当前配置,切换回默认视图。
Config菜单还包含每个命名的配置各一个选项。选择其中一个选项会应用对应配置。当前选择的配置会被标记为 ✓。点击选项右边的那个按钮会(在提示用户确认后)删除对应配置。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









