









在原课程视频中,lecture4讲解了反向传播及一部分神经网络的内容,但是“反向传播”(Backpropagation)作为神经网络计算的基础太过重要了,于是在笔记中我将反向传播单独拿出来,结合自己查资料的理解,做了一些记录,希望读这篇文章的人也能看懂。
视频:b站转载
幻灯片:Slider
课程参考:backprop note
课程参考翻译:智能单元
motivation
若我们有损失函数
f(x,W,b)
,x是输入数据,一般已知;W是权值,b是偏差量,两者都要求最优,一般来说,我们都是要计算
f对W和b
的梯度,在之前的课程中,我们已经有了定义法和分析法,但是这两种方法都有其问题,定义法计算量太大,分析法比易错且需要对每个函数具体分析,但是对具体函数的求偏导有时并不是那么容易,于是我们想到,能不能找到简化一些的方法呢?
在高数中我们都学过,对于一个复合函数,我们可以采用链式法则来一层层的对其求导,从而获得最终的求导结果,这里举一个直观例子:
函数
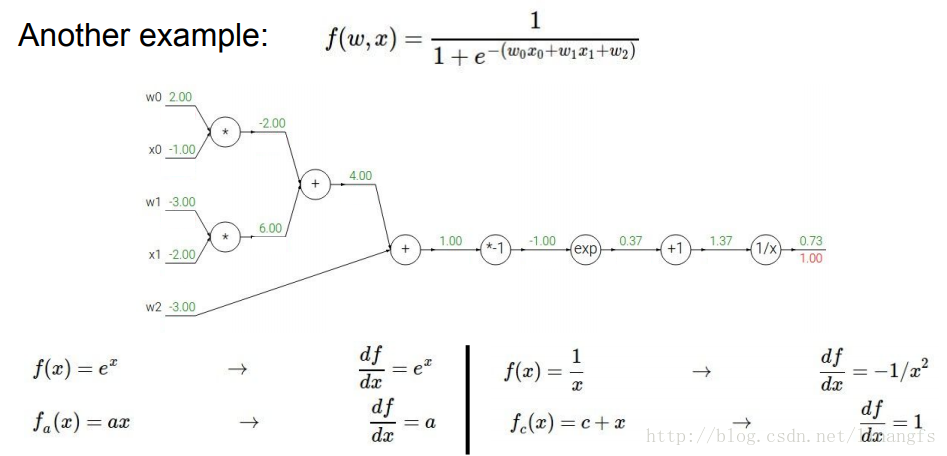
在实际操作中,虽然W和b是所求量,但在每次计算梯度时,本次的W和b都是已知的,所以,为了便于直观理解,我们不妨在这里对其设一个值: x=−2;y=5;z=−4 ,于是用如下的计算图(Computational graphs)表示这一过程:
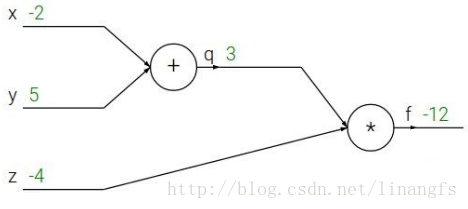
要求解 dfdx 其链式法则的公式是
这是个好主意,但是有个问题,当链更长、我们不仅求其中一个值的偏导时,比如当 x=(x1+x2);y=(x2+x3) ,我们对 x1,x2 分别求偏导时
用一个转自知乎的借钱的比喻来描绘一下:
举个不太恰当的例子,如果把上图中的箭头表示欠钱的关系,即
q→f 表示f欠q的钱。以 x1,x2 为例,直接计算 f 对它们俩的偏导相当于x1,x2 各自去讨薪。 x1 向 q 讨薪,q 说 f 欠我钱,你向他要。于是x1 又跨过 q 去找f 。 x2 先向 q 讨薪,同样又转向f , x2 又向 y 讨薪,再次转向e 。可以看到,追款之路,充满艰辛,而且还有重复,即 x1,x2 都从 q 转向f 。这是一种正向的思维,那么既然正向要账很乱,我们能不能反向来?
f 把所欠之钱还给
q , y 。q , y 收到钱,乐呵地把钱转发给了x1,x2 ,皆大欢喜。这便是反向传播算法(BP)
反向传播(Backpropagation)
反向传播与正向传播的不同在于,正向传播是一种自下而上的收取,顶层收集所有与之相连的下层来取得偏倒,反向传播则是,顶层将对其下层各个路径的偏倒堆放在其面前,下层将所有堆在其面前的偏倒进行运算获得顶层对其的偏倒,然后将其堆在下一层面前,于是顶层对各层的偏倒就一层层的传播下去,因为偏倒一直堆在那,所以我们完全不用重复计算路径值,从而减少了计算。
计算方法:在正向传播中,每一个运算节点传播给下一个节点的输入的变化对输出的影响,而反向传播则是从输出端将梯度传播给输入端,即我们不会去传播 dqdx 而是传播 dfdq 是一种由输出诉诸求输入的算法,每反向经过一层节点到达下一层面前的时候,得到的都是顶端f对该层下一层的梯度。
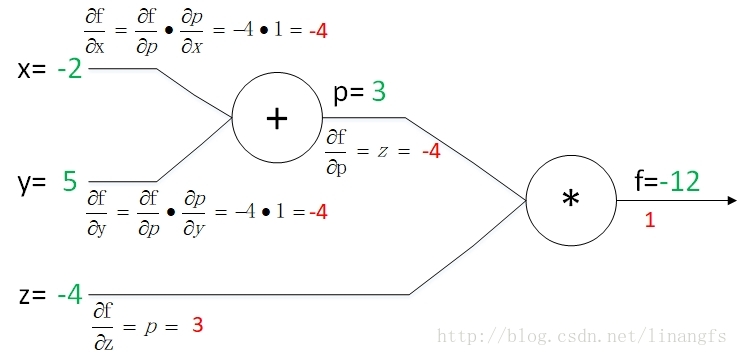
还是上面那计算图,我们来看下反向传播的结果,其先设定 dfdf=1 。
所以,既然在每一层面前的都是顶层对其的梯度,我们为什么不将任意几层压缩成一层呢?或者说(正想看是将复杂函数划分成几个简单函数的复合运算),于是就有的模块的概念。
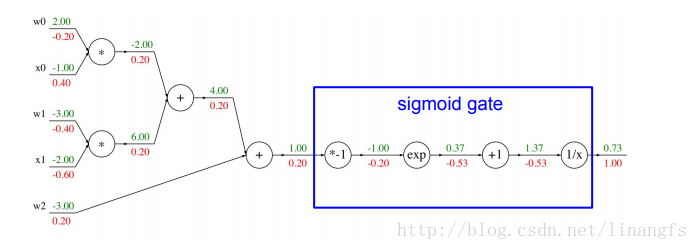
模块化:Sigmoid例子
首先,我们将各个函数运算成为门,则简单函数是简单的门,复杂函数是将几个门合并,从第一个门进去,直接获得最后一个门出来的结果。
我们有这样一个例子来理解模块化:
根据下方的基本求导法则,我们可以计算出反向传播结果:
我们在尾端的一长链的门都是对 w0x0+w1x1+w2 在进行计算,于是我们对其合并为一个函数即Sigmoid函数
σ(x)=11+e−x
我们试着验算来证实一下:
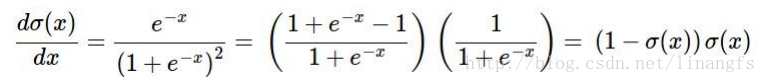
σ(x)=0.37 所以反向传播结果为
(1−0.37)∗0.37=0.2
可以看到结果是一致的。反向传播中的模式
如果在刚才的两个例子中,你都自己演算过一遍,那么我们可以发现一些反向传播的模式特点:
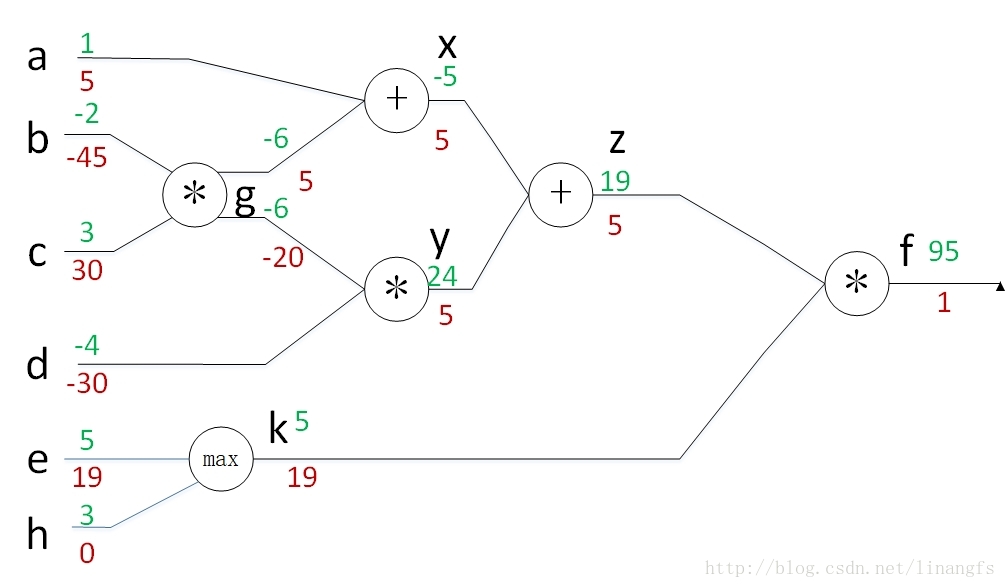
如上图:
1. 加法门可以看做一个梯度分发器:如图,z=5经过加法门的的传播分发为x=y=5,加法门就是将梯度原封不动的分发出去
2. 乘法门可以看做一个梯度转换器:如图,f回流到k上的梯度等于1乘以z的值;回流到k上的梯度等于1乘以z的值;即其局部梯度就是将两个输入值交叉互换。
3. max门可以看做一个梯度路由器:哪个输入值大,梯度就回流到谁那,如图k回流到e和h上的梯度。
4. 门后分散可以看做一个加法器:将两个路径上回流的梯度相加,比如从g回流到b是(-20+5)*c=-45。
其实门后分散就是一个很好的例子来说明在之前对反向传播思想的解释。
回归到矩阵
在上面的推导与理解中,我们都是用的单一实数,而实际上无论是W还是X都是很大的矩阵,而每层传递的梯度也就相应的变成了Jacobian行列式,那么,怎么算?看起来会很麻烦,其实不然:
首先,其同样遵守上面提到的几个模式,加法门、max门、门后分散,都没问题,乘法门涉及到左乘和右乘。在课程视频中是一步步讲解,直接计算梯度来获得的结果,并给出了公式,但这很容易搞错,其实在课程note中有很好的说明:要分析维度!注意不需要去记忆dW和dX的表达,因为它们很容易通过维度推导出来。例如,权重的梯度dW的尺寸肯定和权重矩阵W的尺寸是一样的,而这又是由X和dD的矩阵乘法决定的(在上面的例子中X和W都是数字不是矩阵)。总有一个方式是能够让维度之间能够对的上的。例如,X的尺寸是[10x3],dD的尺寸是[5x3],如果你想要dW和W的尺寸是[5x10],那就要dD.dot(X.T)。
我觉得这个方法是最好的,便于思考也便于检查错误。
编程实现
从上面的计算过程中我们我们可以很轻松的总结出编程实现,注意,在反向传播中需要用到中间变量的计算结果,因此,不仅要编写反向传播过程,更要编写中间变量的计算式。
课程note中的例子:
其编程实现如下:
x = 3 # 例子数值 y = -4 # 前向传播 sigy = 1.0 / (1 + math.exp(-y)) # 分子中的sigmoi #(1) num = x + sigy # 分子 #(2) sigx = 1.0 / (1 + math.exp(-x)) # 分母中的sigmoid #(3) xpy = x + y #(4) xpysqr = xpy**2 #(5) den = sigx + xpysqr # 分母 #(6) invden = 1.0 / den #(7) f = num * invden # 搞定! #(8)# 回传 f = num * invden dnum = invden # 分子的梯度 #(8) dinvden = num #(8) # 回传 invden = 1.0 / den dden = (-1.0 / (den**2)) * dinvden #(7) # 回传 den = sigx + xpysqr dsigx = (1) * dden #(6) dxpysqr = (1) * dden #(6) # 回传 xpysqr = xpy**2 dxpy = (2 * xpy) * dxpysqr #(5) # 回传 xpy = x + y dx = (1) * dxpy #(4) dy = (1) * dxpy #(4) # 回传 sigx = 1.0 / (1 + math.exp(-x)) dx += ((1 - sigx) * sigx) * dsigx # Notice += !! See notes below #(3) # 回传 num = x + sigy dx += (1) * dnum #(2) dsigy = (1) * dnum #(2) # 回传 sigy = 1.0 / (1 + math.exp(-y)) dy += ((1 - sigy) * sigy) * dsigy #(1)后记:看课程视频+看课程note+查资料+自行理解,前前后后花了进20小时,写成了这篇课程笔记,我一直觉得能把学到的内容写出来,才算是真正理解;确实在写的时候发现了不少理解上的错漏,也不妄花时间写了这篇笔记,人力有限,缺陷不足之处,欢迎交流
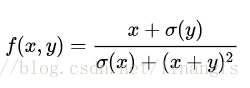














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









