







Fine-tuning(Finetune|微调)
很多时候,我们的电脑跑不了那么多的数据,就可以去下载别人已经训练好的网络进行第二次训练,达到准确率更高,或者增加一个新的类别,让我们一步一步来。
在原有数据集上进行微调
我们之前训练好了mnist,我们可以修改lenet_solver.prototxt如下
# The train/test net protocol buffer definition
net: "examples/mnist/lenet_train_test.prototxt"
# test_iter specifies how many forward passes the test should carry out.
# In the case of MNIST, we have test batch size 100 and 100 test iterations,
# covering the full 10,000 testing images.
test_iter: 10 # 测试时迭代几次
# Carry out testing every 500 training iterations.
test_interval: 500 # 每迭代多少次进行测试
# The base learning rate, momentum and the weight decay of the network.
base_lr: 0.001 #这里是学习速率,调小
momentum: 0.9
weight_decay: 0.0005
# The learning rate policy
lr_policy: "inv"
gamma: 0.0001
power: 0.75
# Display every 100 iterations
display: 100
# The maximum number of iterations
max_iter: 2000 # 最大迭代次数
# snapshot intermediate results
snapshot: 5000 # 这是快照,即5000次迭代进行一次快照
snapshot_prefix: "examples/mnist/lenet" # 快照前面的名字
# solver mode: CPU or GPU
solver_mode: CPU我们这里主要是将学习速率调低,使其更加精确,迭代次数减少(因为也不用那么多次了- -)。
sudo ./build/tools/caffe train --solver ./examples/mnist/lenet_solver.prototxt --weights ./examples/mnist/lenet_iter_10000.caffemodel - 微调前
- 微调后
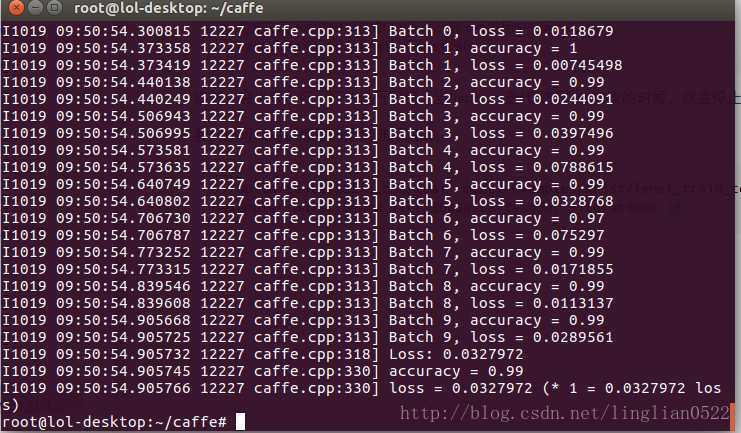
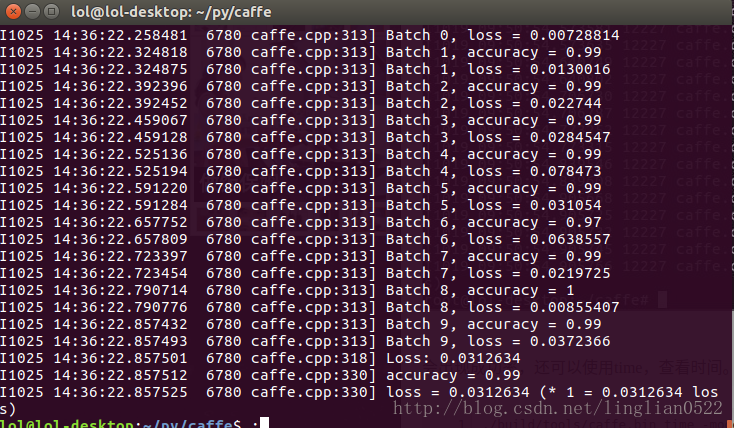
增加了0.1%- -,在试试看将学习策略改成step。
继续修改lenet_solver.prototxt文件如下
# The train/test net protocol buffer definition
net: "examples/mnist/lenet_train_test.prototxt"
# test_iter specifies how many forward passes the test should carry out.
# In the case of MNIST, we have test batch size 100 and 100 test iterations,
# covering the full 10,000 testing images.
test_iter: 100
# Carry out testing every 500 training iterations.
test_interval: 500
# The base learning rate, momentum and the weight decay of the network.
base_lr: 0.001
momentum: 0.9
weight_decay: 0.0005
# The learning rate policy
lr_policy: "step"
gamma: 0.0001
stepsize: 100
# Display every 100 iterations
display: 100
# The maximum number of iterations
max_iter: 2000
# snapshot intermediate results
snapshot: 5000
snapshot_prefix: "examples/mnist/lenet"
# solver mode: CPU or GPU
solver_mode: CPU sudo ./build/tools/caffe.bin train -solver examples/mnist/lenet_solver.prototxt -weights examples/mnist/lenet_iter_2000.caffemodel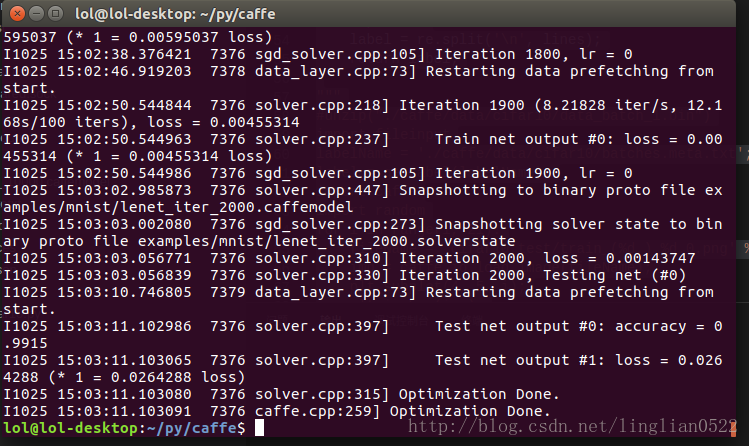
可以看到有进步了- -而且训练时间非常短。
我们试试看将数字0123456剔除,只训练789,接着用789的模型,训练0,看看能不能成功。
我们之前提取了mnist的图片,这次我们根据给出的标签,来进行分类。
首先需要创建文件夹
mkdir mnist_test
mkdir ./mnist_test/0
mkdir ./mnist_test/1
mkdir ./mnist_test/2
mkdir ./mnist_test/3
mkdir ./mnist_test/4
mkdir ./mnist_test/5
mkdir ./mnist_test/6
mkdir ./mnist_test/7
mkdir ./mnist_test/8
mkdir ./mnist_test/9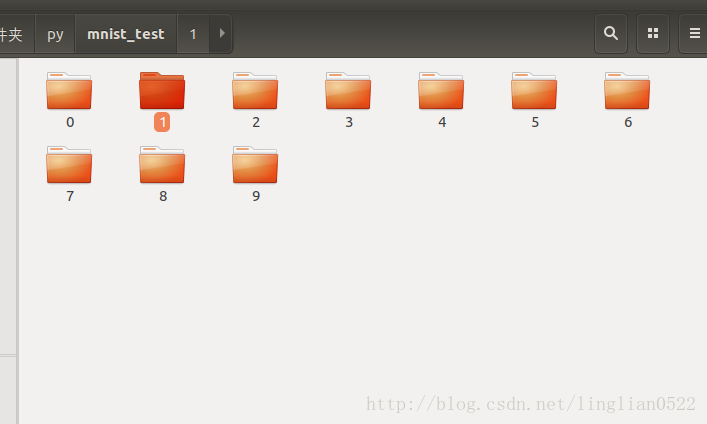
import numpy as np
import struct
import matplotlib.pyplot as pyplot
import Image
def unzip(fileName, labelName):
binfile = open(fileName, 'rb')
buf = binfile.read()
binfileOfLabel = open(labelName, 'rb')
bufOfLabel = binfileOfLabel.read()
index = 0
index2 = 0
magic, numImages, numRows, numColumns = struct.unpack_from(
'>IIII', buf, index)
index += struct.calcsize('>IIII')
index2 += struct.calcsize('>II')
n = [0 for x in range(0, 10)];
for image in range(0, numImages):
im = struct.unpack_from('>784B', buf, index)
label = struct.unpack_from('>1B', bufOfLabel, index2)
index += struct.calcsize('>784B')
index2 += struct.calcsize('>1B')
im = np.array(im, dtype='uint8')
im = im.reshape(28, 28)
im = Image.fromarray(im)
im.save('mnist_test/%d/train_%s.bmp' % (label[0], n[label[0]]), 'bmp')
n[label[0]] += 1
unzip('./caffe/data/mnist/t10k-images-idx3-ubyte', './caffe/data/mnist/t10k-labels-idx1-ubyte')
好了,把数字分割开来以后,我们需要将要测试数据随机存入mdb














 1558
1558











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









