









最近看了几天的Python语法,就想做个简单的Demo来巩固所学的基础知识。爬虫是python里头比较广泛而有特点的一个应用面,之前没学python之前一直在用Java爬,现在试着用python抓取一个简单的列表页。
根据需要的实现需求,大体可以分为以下几步实现:
- 获取网页
- 解析网页,提取信息
- 将提取的信息写入Excel
在编写代码前,需要导入python相关的工具模块,打开CMD,分别输入以下命令导入模块
pip install requests
pip install BeautifulSoup4
pip install xlwt导入模块的功能:Requests(获取目标网页)、BeautifulSoup4(提取网页信息)、xlwt(将信息写入 Excel 文件)
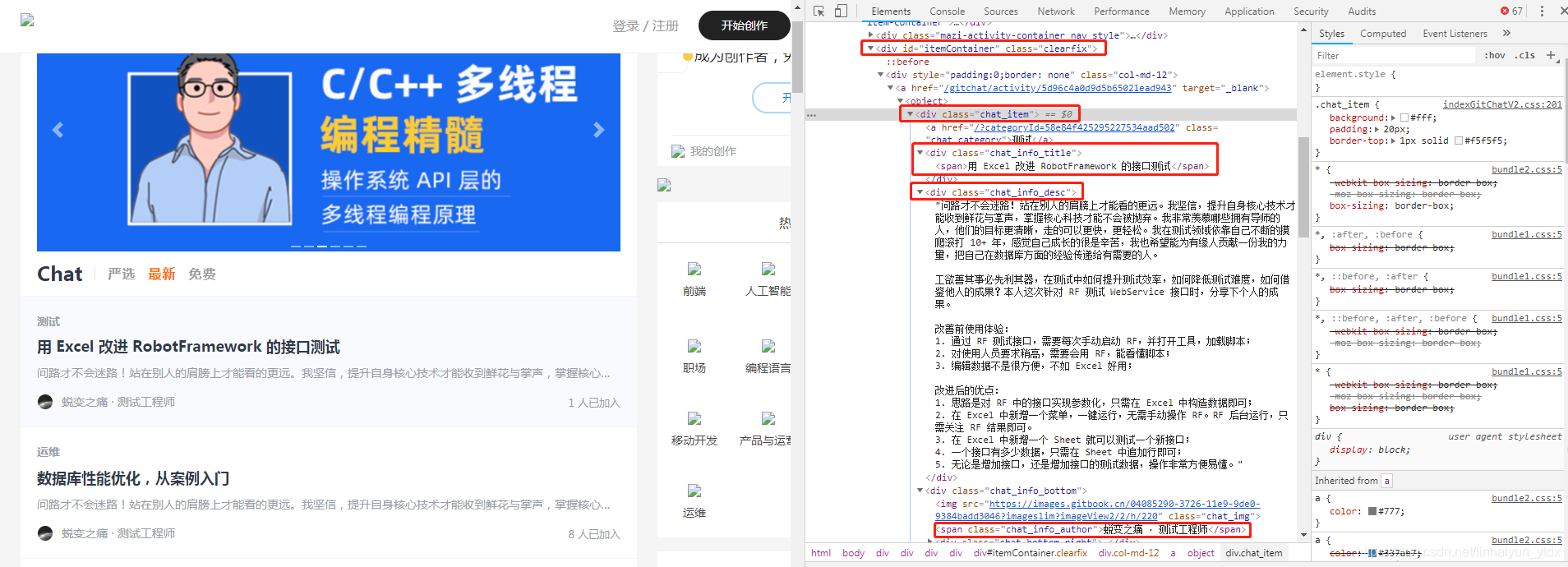
网页元素分析
最新的chat网页有大量的元素,我们需要的只是一部分,需要截取的如下截图所示
接下来就可以着手做编码工作了,上菜
'''
Created on 2019年10月4日
coding=utf-8
@author: linhaiy
'''
#第一步:获取网页所有html信息,拉取快照
import requests
from bs4 import BeautifulSoup
import xlwt
def getHTMLText(url):
try:
r = requests.get(url)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except Exception as err:
print(err)
#第二步:通过BeautifulSoup解析网页,提取我们需要的数据
def getDataFilter(html):
soup = BeautifulSoup(html, "html.parser")
ChatList = soup.find('div', attrs = {'id':'itemContainer'})
dataList = [] #用于存放提取到的全部Chat信息
#遍历每一条chat
for Chat in ChatList.find_all('div',attrs={'class':'col-md-12'}):
data = []
#提取Chat标题
chatTile=Chat.find('div',attrs={'class':'chat_info_title'}).getText()
data.append(chatTile)
#提取文章分类
chatCategory = Chat.find('a',attrs={'class':'chat_category'}).getText()
data.append(chatCategory)
#提取作者姓名
chatAuthor = Chat.find('span',attrs={'class':'chat_info_author'}).getText()
data.append(chatAuthor)
#抓取参加人数
chatPeople = Chat.find('div',attrs={'class':'chat_count'}).getText()
data.append(chatPeople)
#抓取描述简介
chatDesc = Chat.find('div',attrs={'class':'chat_info_desc'}).getText()
data.append(chatDesc)
dataList.append(data)
return dataList
#第三步:保存数据到Excel中
def saveData(datalist,path):
#标题栏背景色
styleBlueBkg = xlwt.easyxf('pattern: pattern solid, fore_colour pale_blue; font: bold on;'); # 80% like
#创建一个工作簿
book=xlwt.Workbook(encoding='utf-8',style_compression=0)
#创建一张表
sheet=book.add_sheet('最新ChatTop20',cell_overwrite_ok=True)
#标题栏
titleList=('Chat标题','文章分类','作者','参加人数','描述简介')
#设置第一列尺寸
first_col = sheet.col(0)
first_col.width=256*40
#写入标题栏
for i in range(0,5):
sheet.write(0,i,titleList[i], styleBlueBkg)
#写入Chat信息
for i in range(0,len(datalist)):
data=datalist[i]
for j in range(0,5):
sheet.write(i+1,j,data[j])
#保存文件到指定路径
book.save(path)
#网页地址
chatUrl='http://gitbook.cn/gitchat/hot'
html=getHTMLText(chatUrl)
dataList = getDataFilter(html)
print("抓取的网页为: " ,dataList)
saveData(dataList,str("C:/Users/linhaiy/Desktop/NewChat.xls"))
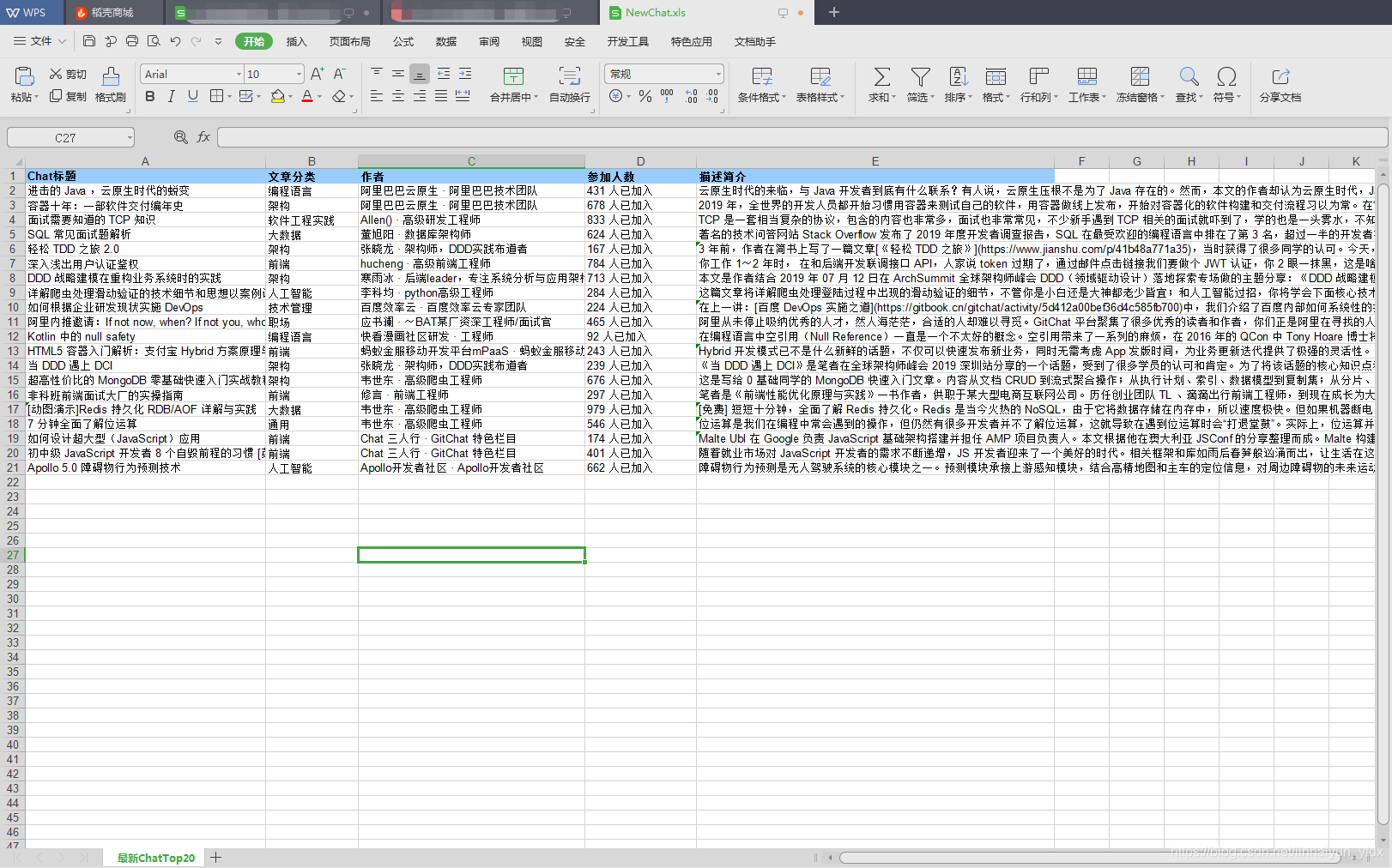
抓取结果
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











