







变量说明
Customer_ID:用户编号
Gender:性别
Age:年龄
L_O_S:在网时长
Tariff:话费类型/话费方案
Handset:手机品牌
Peak_calls:高峰时期电话数
Peak_mins:高峰时期电话时长
OffPeak_calls:低谷时期电话数
OffPeak_mins:低谷时期电话时长
Weekend_calls:周末电话数
Weekend_mins:周末电话时长
International_mins:国际电话时长
Nat_call_cost:国内电话费用
month:月份
背景与目标
运营商能够将客户很好地进行分层是为客户推出差异化的服务的基础,好的用户分析也是提升用户体验的前提。本文通过分析电信客户的相关数据(客户信息与客户通话数据),以期(1)了解客户特征,(2)并通过Kmeans聚类分析对客户进行聚类。
导入数据
import pandas as pd
# 导入数据
# 用户电话情况
custcall = pd.read_csv('C:\\Users\\lin\\Desktop\\custcall.csv',sep = ',')
# 用户信息
custinfo = pd.read_csv('C:\\Users\\lin\\Desktop\\custinfo.csv',sep = ',')
查看数据
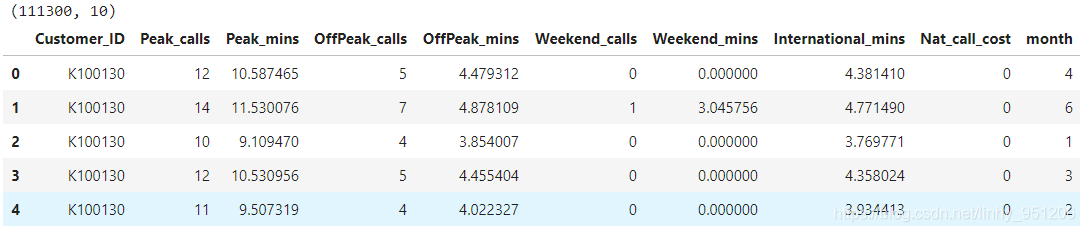
print(custcall.shape)
custcall.head()
返回结果:
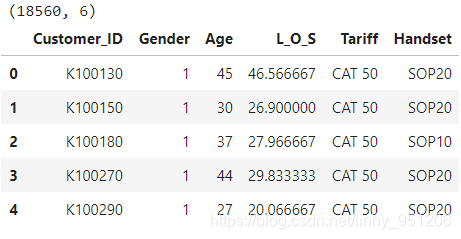
print(custinfo.shape)
custinfo.head()
返回结果:
1 数据清洗与整理
# 求每个用户各指标的平均值
custcall_avg = custcall.groupby(by = ['Customer_ID']).mean()
# month 的均值为同一值,故剔除 ‘month’
del custcall_avg['month']
# 合并数据集
cust = pd.merge(custinfo,custcall_avg,left_on = 'Customer_ID',right_index = True,how = 'inner')
# 查看Customer_ID是否有重复值
print(cust['Customer_ID'].duplicated().sum())
# 将Customer_ID设为索引
cust = cust.set_index(keys = ['Customer_ID'])
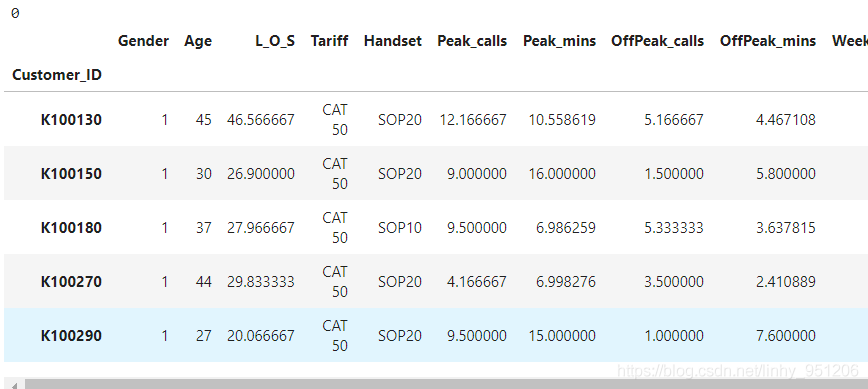
cust.head()
返回结果:
# 查看cust的形状并将其导出
print(cust.shape)
print(cust.columns.to_list())
cust.to_excel('C:\\User 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 1027
1027











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









