









同步、异步、阻塞、非阻塞 I/O
第一部分来自:
http://blog.csdn.net/historyasamirror/archive/2010/07/31/5778378.aspx
Stevens在文章中一共比较了五种IO Model:
blocking IO
nonblocking IO
IO multiplexing
signal driven IO
asynchronous IO
由于signal driven IO在实际中并不常用,所以我这只提及剩下的四种IO Model。
再说一下IO发生时涉及的对象和步骤。
对于一个network IO (这里我们以read举例),它会涉及到两个系统对象,一个是调用这个IO的process (or thread),另一个就是系统内核(kernel)。当一个read操作发生时,它会经历两个阶段:
1 等待数据准备 (Waiting for the data to be ready)
2 将数据从内核拷贝到进程中 (Copying the data from the kernel to the process)
记住这两点很重要,因为这些IO Model的区别就是在两个阶段上各有不同的情况。
blocking IO
在linux中,默认情况下所有的socket都是blocking,一个典型的读操作流程大概是这样:
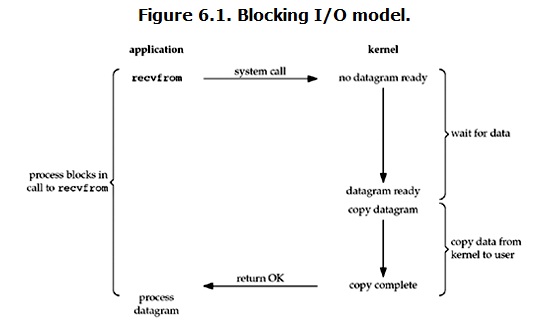
当用户进程调用了recvfrom这个系统调用,kernel就开始了IO的第一个阶段:准备数据。对于network io来说,很多时候数据在一开始还没有到达(比如,还没有收到一个完整的UDP包),这个时候kernel就要等待足够的数据到来。而在用户进程这边,整个进程会被阻塞。当kernel一直等到数据准备好了,它就会将数据从kernel中拷贝到用户内存,然后kernel返回结果,用户进程才解除block的状态,重新运行起来。
所以,blocking IO的特点就是在IO执行的两个阶段都被block了。
non-blocking IO
linux下,可以通过设置socket使其变为non-blocking。当对一个non-blocking socket执行读操作时,流程是这个样子:
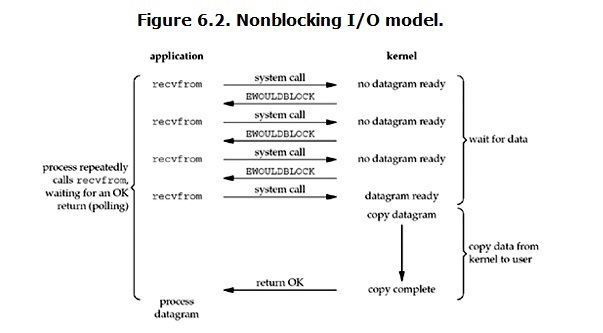
从图中可以看出,当用户进程发出read操作时,如果kernel中的数据还没有准备好,那么它并不会block用户进程,而是立刻返回一个error。从用户进程角度讲 ,它发起一个read操作后,并不需要等待,而是马上就得到了一个结果。用户进程判断结果是一个error时,它就知道数据还没有准备好,于是它可以再次发送read操作。一旦kernel中的数据准备好了,并且又再次收到了用户进程的system call,那么它马上就将数据拷贝到了用户内存,然后返回。
所以,用户进程其实是需要不断的主动询问kernel数据好了没有。
IO multiplexing
IO multiplexing这个词可能有点陌生,但是如果我说select,epoll,大概就都能明白了。有些地方也称这种IO方式为event driven IO。我们都知道,select/epoll的好处就在于单个process就可以同时处理多个网络连接的IO。它的基本原理就是select/epoll这个function会不断的轮询所负责的所有socket,当某个socket有数据到达了,就通知用户进程。它的流程如图:
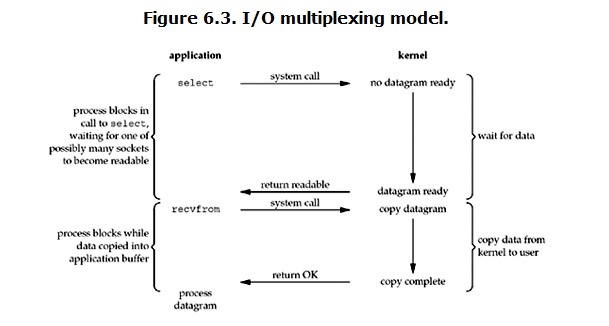
当用户进程调用了select,那么整个进程会被block,而同时,kernel会“监视”所有select负责的socket,当任何一个socket中的数据准备好了,select就会返回。这个时候用户进程再调用read操作,将数据从kernel拷贝到用户进程。
这个图和blocking IO的图其实并没有太大的不同,事实上,还更差一些。因为这里需要使用两个system call (select 和 recvfrom),而blocking IO只调用了一个system call (recvfrom)。但是,用select的优势在于它可以同时处理多个connection。(多说一句。所以,如果处理的连接数不是很高的话,使用select/epoll的web server不一定比使用multi-threading + blocking IO的web server性能更好,可能延迟还更大。select/epoll的优势并不是对于单个连接能处理得更快,而是在于能处理更多的连接。)
在IO multiplexing Model中,实际中,对于每一个socket,一般都设置成为non-blocking,但是,如上图所示,整个用户的process其实是一直被block的。只不过process是被select这个函数block,而不是被socket IO给block。
Asynchronous I/O
linux下的asynchronous IO其实用得很少。先看一下它的流程:
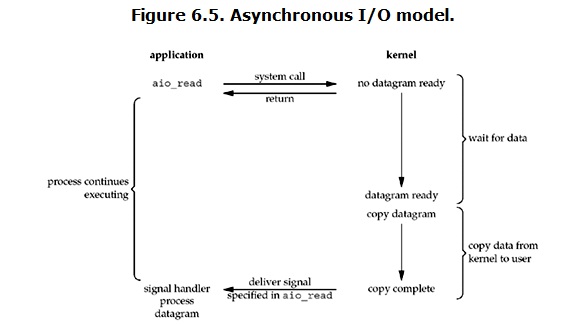
用户进程发起read操作之后,立刻就可以开始去做其它的事。而另一方面,从kernel的角度,当它受到一个asynchronous read之后,首先它会立刻返回,所以不会对用户进程产生任何block。然后,kernel会等待数据准备完成,然后将数据拷贝到用户内存,当这一切都完成之后,kernel会给用户进程发送一个signal,告诉它read操作完成了。
到目前为止,已经将四个IO Model都介绍完了。现在回过头来回答最初的那几个问题:blocking和non-blocking的区别在哪,synchronous IO和asynchronous IO的区别在哪。
先回答最简单的这个:blocking vs non-blocking。前面的介绍中其实已经很明确的说明了这两者的区别。调用blocking IO会一直block住对应的进程直到操作完成,而non-blocking IO在kernel还准备数据的情况下会立刻返回。
在说明synchronous IO和asynchronous IO的区别之前,需要先给出两者的定义。Stevens给出的定义(其实是POSIX的定义)是这样子的:
A synchronous I/O operation causes the requesting process to be blocked until that I/O operation completes;
An asynchronous I/O operation does not cause the requesting process to be blocked;
两者的区别就在于synchronous IO做”IO operation”的时候会将process阻塞。按照这个定义,之前所述的blocking IO,non-blocking IO,IO multiplexing都属于synchronous IO。有人可能会说,non-blocking IO并没有被block啊。这里有个非常“狡猾”的地方,定义中所指的”IO operation”是指真实的IO操作,就是例子中的recvfrom这个system call。non-blocking IO在执行recvfrom这个system call的时候,如果kernel的数据没有准备好,这时候不会block进程。但是,当kernel中数据准备好的时候,recvfrom会将数据从kernel拷贝到用户内存中,这个时候进程是被block了,在这段时间内,进程是被block的。而asynchronous IO则不一样,当进程发起IO 操作之后,就直接返回再也不理睬了,直到kernel发送一个信号,告诉进程说IO完成。在这整个过程中,进程完全没有被block。
各个IO Model的比较如图所示:

经过上面的介绍,会发现non-blocking IO和asynchronous IO的区别还是很明显的。在non-blocking IO中,虽然进程大部分时间都不会被block,但是它仍然要求进程去主动的check,并且当数据准备完成以后,也需要进程主动的再次调用recvfrom来将数据拷贝到用户内存。而asynchronous IO则完全不同。它就像是用户进程将整个IO操作交给了他人(kernel)完成,然后他人做完后发信号通知。在此期间,用户进程不需要去检查IO操作的状态,也不需要主动的去拷贝数据。
最后,再举几个不是很恰当的例子来说明这四个IO Model:
有A,B,C,D四个人在钓鱼:
A用的是最老式的鱼竿,所以呢,得一直守着,等到鱼上钩了再拉杆;
B的鱼竿有个功能,能够显示是否有鱼上钩,所以呢,B就和旁边的MM聊天,隔会再看看有没有鱼上钩,有的话就迅速拉杆;
C用的鱼竿和B差不多,但他想了一个好办法,就是同时放好几根鱼竿,然后守在旁边,一旦有显示说鱼上钩了,它就将对应的鱼竿拉起来;
D是个有钱人,干脆雇了一个人帮他钓鱼,一旦那个人把鱼钓上来了,就给D发个短信。
异步I/O实现
第二部分来自:
http://www.ibm.com/developerworks/cn/linux/l-async/
其中包含用aio.h的API实现。
下面是用libaio.h的API实现。
初始化异步IO上下文:
int io_queue_init(int maxevents, io_context_t *ctx );
maxevents:允许提交的最大异步IO请求数目;
ctx:异步IO上下文
返回值:成功返回0,失败返回-errno
初始化IOCB块
异步IO块的数据结构。
struct iocb {
void *data;//用于存储回调函数或者字符串
unsigned key;
short aio_lio_opcode;//操作码,是读还是写,或者其他
short aio_reqprio;
int aio_fildes;//
union {
struct io_iocb_common c;
struct io_iocb_vector v;
struct io_iocb_poll poll;
struct io_iocb_sockaddr saddr;
} u;
};
初始化一个异步IO读请求:
inline void io_prep_pread(struct iocb *iocb, int fd, void *buf, size_t count, long long offset);
初始化一个异步IO写请求:
inline void io_prep_pwrite(struct iocb *iocb, int fd, void *buf, size_t count, long long offset);
对buf进行对齐:
int posix_memalign(void **memptr, size_t alignment, size_t size);
提交异步IO请求:
int io_submit(aio_context_t ctx_id, long nr, struct iocb **iocbpp);
ctx_id:异步IO上下文
nr:要提交的异步IO请求的数目
iocbpp:指向异步IO块的指针的指针
获取已完成的异步IO事件:
int io_getevents(aio_context_t ctx_id, long min_nr, long nr, struct io_event *events, struct timespec *timeout);
min_nr:等待的最小的事件数
nr:等待的最大事件数
timeout:超时
io_event结构:
#define PADDEDptr(x, y) x; unsigned y
#define PADDEDul(x, y) unsigned long x; unsigned y
struct io_event {
PADDEDptr(void *data, __pad1);//data 用于存放回调函数,如果无回调函数,该data也可以存放入字符串这样的信息
PADDEDptr(struct iocb *obj, __pad2);//存放iocb对象
PADDEDul(res, __pad3);//实际读到的字符串长度,当所传递的fd是以O_DIRECT打开,但是,buf长度不是AIO_BLKSIZE的时候,该参数被设置为-22,errno为22时,其意义为“Invalid argument”
PADDEDul(res2, __pad4);//出错码,如果出错,则不为0;若未出错,则为0
};
注意的地方:
对于不满足规定的异步IO块大小的文本,使用没有用O_DIRECT打开的文件描述符进行操作
实例:
该程序实现了一个复制文件的功能,运行程序时需要传入两个参数,第一个是原文件名,第二个是目标文件名。
//#define __USE_GNU
#undef _FILE_OFFSET_BITS
#define _FILE_OFFSET_BITS 64
#include <stdlib.h>
#include <stdio.h>
#include <unistd.h>
#include <dirent.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <sys/param.h>
#include <fcntl.h>
#include <errno.h>
#include <libaio.h>
#define AIO_BLKSIZE 1024
#define AIO_MAXIO 64
static int busy = 0;
static int tocopy = 0;
static int srcfd = -1;
static int srcfd2 = -1;
static int dstfd = -1;
static int dstfd2 = -1;
static const char *dstname = NULL;
static const char *srcname = NULL;
/*fatal error handler*/
static void io_error(const char *func, int rc)
{
if(rc == -ENOSYS)
fprintf(stdout, "AIO not in this kernel/n");
else
fprintf(stdout, "%s: errno%d", func, rc);
if(dstfd > 0)
close(dstfd);
if(dstname)
unlink(dstname);
exit(1);
}
/*
*write complete callback
*adjust counts and free resources
*/
static void wr_done(io_context_t ctx, struct iocb *iocb, long res, long res2)
{
if(res2 != 0)
{
io_error("aio write", res2);
}
if(res != iocb->u.c.nbytes)
{
fprintf(stdout, "write missed bytes expect %d got %d", iocb->u.c.nbytes, res);
exit(1);
}
// printf("res = %d, res2 = %d/n", res, res2);
--tocopy;
--busy;
free(iocb->u.c.buf);
free(iocb);
}
/*
*read complete callback
*change read iocb into a write iocb and start it.
*/
static void rd_done(io_context_t ctx, struct iocb *iocb, long res, long res2)
{
/*library needs accessors to look at iocb*/
int iosize = iocb->u.c.nbytes;
char *buf = (char *)iocb->u.c.buf;
off_t offset = iocb->u.c.offset;
int fd, tmp;
char *wrbuff = NULL;
if(res2 != 0)
{
io_error("aio read", res2);
}
if(res != iosize)
{
fprintf(stdout, "read missing bytes expect %d got %d", iocb->u.c.nbytes, res);
exit(1);
}
if(iocb->aio_fildes == srcfd)
{
fd = dstfd;
}
else
fd = dstfd2;
/*turn read into write*/
tmp = posix_memalign((void **)&wrbuff, getpagesize(), AIO_BLKSIZE);
if(tmp < 0)
{
perror("posix_memalign");
exit(1);
}
snprintf(wrbuff, iosize + 1, "%s", buf);
// printf("wrbuff-len = %d:%s/n", strlen(wrbuff), wrbuff);
// printf("wrbuff_len = %d/n", strlen(wrbuff));
free(buf);
io_prep_pwrite(iocb, fd, wrbuff, iosize, offset);
io_set_callback(iocb, wr_done);
if(1 != (res=io_submit(ctx, 1, &iocb)))
io_error("io_submit write", res);
printf("/nsubmit %d write request/n", res);
}
void m_io_queue_run(io_context_t myctx)
{
// printf("in m_io_queue_run:/n");
struct io_event events[AIO_MAXIO];
io_callback_t cb;
int n, i;
n = io_getevents(myctx, 1, AIO_MAXIO, events, NULL);
printf("/n%d io_request completed/n/n", n);
for(i=0;i<n;i++)
{
cb = (io_callback_t)events[i].data;
struct iocb *io = events[i].obj;
//use epoll_fd to register EPOLLOUT
//here segmentfault
// printf("events[%d].data = %x, res = %d, res2 = %d/n", i, cb, events[i].res, events[i].res2);
cb(myctx, io, events[i].res, events[i].res2);
}
}
int main(int argc, char *const *argv)
{
struct stat st;
// off_t length = 0, offset = 0;
long long length = 0, offset = 0;
io_context_t myctx;
char *buff = NULL;
int leftover;
int tmp;
int last;
if(argc != 3 || argv[1][0] == '-')
{
fprintf(stdout, "Usage: aiocp SOURCE DEST/n");
exit(1);
}
if((srcfd=open(srcname=argv[1], O_RDONLY | O_DIRECT)) < 0)
{
perror(srcname);
exit(1);
}
if(fstat(srcfd, &st) < 0)
{
perror("fstat");
exit(1);
}
length = (long long)st.st_size;
if((dstfd=open(dstname=argv[2], O_WRONLY | O_CREAT | O_DIRECT, 0666))< 0)
{
close(srcfd);
perror(dstname);
exit(1);
}
leftover = length%AIO_BLKSIZE;
length -= leftover;
/*initialize stat machine*/
memset(&myctx, 0, sizeof(myctx));
io_queue_init(AIO_MAXIO, &myctx);
/*in sys/param.h # define howmany(x, y) (((x) + ((y) - 1)) / (y))*/
tocopy = howmany(length, AIO_BLKSIZE);
while(tocopy > 0)
{
int i, rc;
/*submit as many reads as once as possible upto AIO_MAXIO
*in sys/param #define MIN(a,b) (((a)<(b))?(a):(b))
*/
int n = MIN(MIN(AIO_MAXIO - busy, AIO_MAXIO/2),howmany(length - offset, AIO_BLKSIZE));
if(n > 0)
{
struct iocb *ioq[n];
for(i=0;i<n;i++)
{
struct iocb *io = (struct iocb*)malloc(sizeof(struct iocb));
int iosize = AIO_BLKSIZE;
tmp = posix_memalign((void **)&buff, getpagesize(), AIO_BLKSIZE);
if(tmp < 0)
{
perror("posix_memalign");
exit(1);
}
if(NULL == io)
{
fprintf(stdout, "out of memeory/n");
exit(1);
}
io_prep_pread(io, srcfd, buff, iosize, offset);
io_set_callback(io, rd_done);
ioq[i] = io;
offset += iosize;
buff = NULL;
}
printf("START.../n/n");
rc = io_submit(myctx, n, ioq);
if(rc < 0)
io_error("io_submit", rc);
printf("/nsubmit %d read request/n", rc);
busy += n;
}
// Handle IO's that have completed
m_io_queue_run(myctx);
//if we have maximum number of i/o's in flight
//then wait for one to complete
/* if(busy == AIO_MAXIO)
{
rc = io_queue_wait(myctx, NULL);
if(rc < 0)
{
io_error("io_queue_wait", rc);
}
}
*/
}
if(leftover)
{
srcfd2 = open(srcname, O_RDONLY);
if(srcfd2 < 0)
{
perror("srcfd2 open");
exit(1);
}
dstfd2 = open(dstname, O_WRONLY);
if(dstfd2 < 0)
{
perror("dstfd2 open");
exit(1);
}
struct iocb *io = (struct iocb *)malloc(sizeof(struct iocb));
if(io == NULL)
{
perror("malloc failed");
exit(1);
}
buff = NULL;
tmp = posix_memalign((void **)&buff, getpagesize(), AIO_BLKSIZE);
if(tmp < 0)
{
perror("posix_memalign");
exit(1);
}
io_prep_pread(io, srcfd2, buff, leftover, offset);
io_set_callback(io, rd_done);
if((last = io_submit(myctx, 1, &io)) < 0)
{
perror("io_submit");
exit(1);
}
printf("/nsubmit %d io request/n", last);
m_io_queue_run(myctx);
}
exit(0);
}















 2635
2635

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









