









前段时间一口气读完了 NN4NLP,很是畅快,非常喜欢作者行文讲解的口吻和逻辑。大概两周读完,每页都有收获,读完后反而担心有所疏漏,知识太多留不住,索性从头来一遍,把学习过程的知识点和思考记录下来,也算精简版供自己今后查阅。
感兴趣的,可以一起学习讨论,真的很推荐这本书。
大致介绍下该书。NN4NLP 由 Goldberg 撰写,是 CMU CS11-747 课程的教材,配合公开课食用更佳,公开课链接。本书并非系统介绍 NN 和 NLP,而是聚焦 NN 在 NLP 领域的具体应用,所以分成了四大部分:NN 中前馈神经网络的入门,前馈神经网络在 NLP 中的应用,RNN 等特殊结构在 NLP 中的应用,部分前沿方向介绍。
因此,本博客也打算分成多篇进行总结,其他篇章请自行搜索本博客。
自然语言数据
三、语言模型
语言模型,即针对某种语言给定句子们分配概率值的任务,或者针对一串单词后跟一个词或者词串的可能性分配概率值的任务,实际这两个任务是等价的,可转换。语言模型在机器翻译和自动语音识别中具有重要作用,即对系统产生的多个翻译或者转录假设进行评分。
形式上,语言模型的任务是针对任意序列的词串分配概率,利用概率的链式规则,可写作
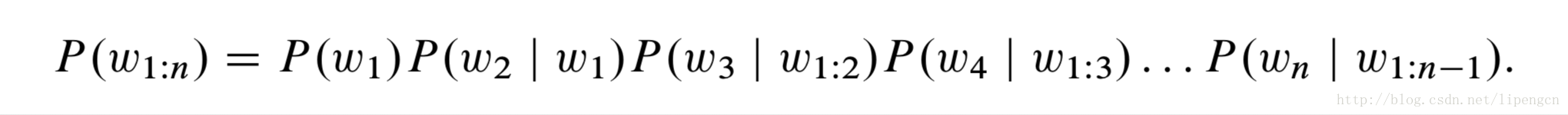
添加马尔科夫假设后,可以大大降低计算复杂度,这里用 k 阶马尔科夫假设,即下一个词仅依赖于该词和更前面的 k 个词,可以近似为
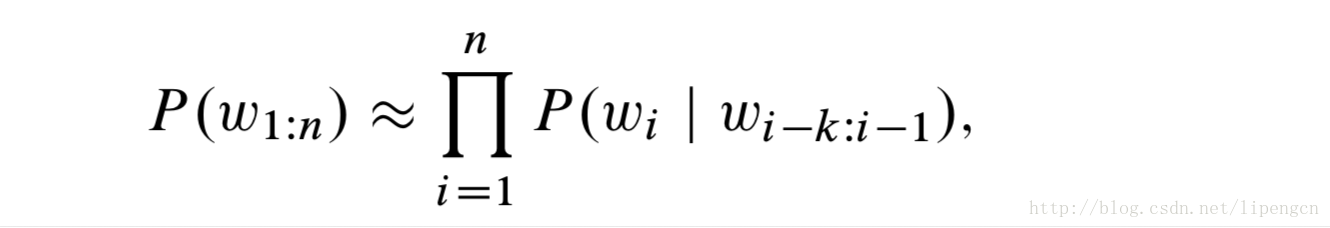
虽然马尔科夫假设明显不合理,但大大降低了计算复杂度,得到的结果也还不错,因此流行了数十年。
有几个评估语言模型的指标,常见的是以应用为中心的方式,即在具体应用中以更高层级的指标进行评估。
更本质的方式应该是使用困惑度(perplexity)指标。
语言模型的传统方式
传统方式基于 k 阶 markov 假设来 model
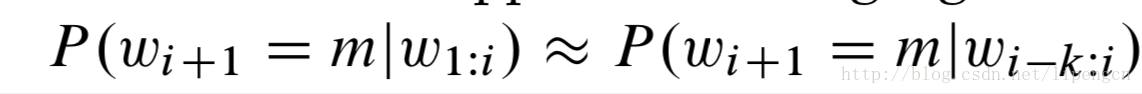
利用最大似然估计,有
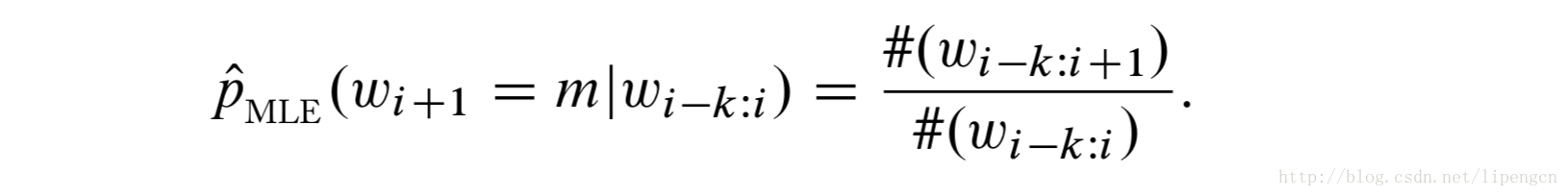
虽然有效,但最大缺点在于存在零事件,即由于训练数据有限导致上式分子经常为0。
解决方法一是,采用平滑技术。
解决方法二是,采用 back-off 技术,即如果 k gram 不存在,就用 k-1 gram 来近似。
目前,非 NN 的最先进技术是使用修正 Kneser-Ney 平滑。
上述基于平滑 MLE 估计的方法虽然方便训练、实际工作也不错,但有几个重要缺陷:
① 平滑技术本身比较复杂,且基于 back-off 到低阶事件。
② 很难应用到较大的 n-grams 场景。
③ 对上下文基本没有泛化能力,如观察到 black car 和 blue car 对估计未见过的 red car 基本没有影响
语言模型的 NN 方式
相应地,基于非线性 NN 的语言模型方法解决了传统语言模型的几个缺陷,即仅以参数数量的线性增长就可以处理较大的上下文尺寸,避免了手工设计 backoff 阶的必要,支持对不同上下文的泛化。
此时,NN 的输入是 k-gram 的词串,输出是该词串下一个词的预测概率分布。这 k 个词形成一个词窗,每个配以嵌入向量,然后所有串联形成输入向量。如下式
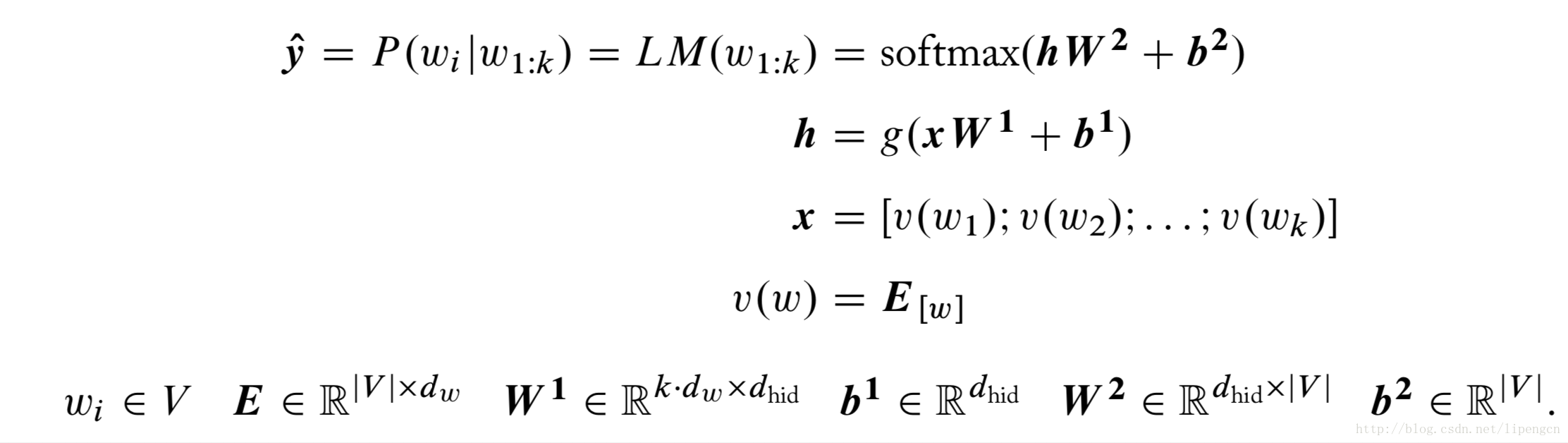
其中,E 就是嵌入矩阵。
(1)训练
通常使用交叉熵损失,但此时要使用较费时的 softmax 操作,从而使得 NN 语言模型难以拓展到大规模词典情况。
总而言之,扩大 n-gram 在计算复杂度上更好接受,但扩大 vocabulary 更难接受。
因此,处理在较大 vocabulary 上计算 softmax 而面临的大规模输出空间问题,主流方法有
① Hierarchical softmax,即将 softmax 计算构造为树遍历形式
② Self-normalizing 方法
③ Sampling 方法
(2)优点
虽然有上面那个限制,但 NN 语言模型优点还是很多的,至少性能比目前最好的传统语言模型要好。此外,除了对 k-gram 阶数更自由,还能对上下文进行泛化。
(3)缺点
比传统语言模型在预测时开销更大;
难以应用到大规模 vocabulary。
在机器翻译系统中,神经语言模型并不比 Kneser-Ney 平滑语言模型表现更好,但当两者结合时,系统性能却得到了提升。
实际上,两者可以互相补充:神经语言模型对未知事件泛化更好,但有时这种泛化却伤害了性能,此时僵化的传统模型反而更好。
此外,神经语言模型带来了一个很有用的副产品,词向量,即上式中矩阵 E 的行和 W^2 的列,可以用来表征词。
四、词向量
1、预训练词向量
初始化 embedding 向量的方式通常为随机初始化方法:初始化为均匀抽样随机数,即 word2vec 采用的,或者前面讲过的 xavier 初始化方法。
实际中,通常对普遍出现的特征可以用随机初始化方法,如 pos 或字母。对于出现较少的特征如词,一般用监督或者无监督的预训练方式来初始化。
(1)监督预训练方式
假设我们感兴趣的任务 A 只有有限的标注数据,如句法分析任务,同时有一个标注数据充分的辅助任务 B ,如 pos 标注任务。
此时,我们可以通过预训练词向量以在任务 B 上取得好的预测表现,然后用这个训练好的词向量再来训练任务 A。这样可以充分利用任务 B 上的大量标注数据。
当训练任务 A 时,可以把预训练词向量固定,或者针对任务 A 继续训练。
当然,还有种方式是两个目标结合起来进行,这在后面的博文中再介绍吧。
(2)无监督预训练方式
可惜的是,通常找不到拥有大量标注数据的辅助任务 B(或者我们想用更好的向量来引导辅助任务 B 的训练),这时就需要无监督辅助任务了,即在大量未标注文本上进行训练,实际即从原始文本中创造无限量的监督训练样本。
一大好处是可以提供监督训练集中未出现词的词向量。
无监督预训练方法的关键思想在于,期待相似词的嵌入向量具有相似的向量。
但词的相似性很难定义,通常是任务相关的。目前主流思路来源于 distributional hypothesis,即出现在相似上下文的词就相似。
前面提到词向量是语言模型的副产品,实际上,语言模型可以被视为无监督方法,即基于给定词的前 k 个词构成的上下文来预测该词。下面我们介绍具体的词嵌入算法。
注意,辅助任务(基于什么类型的上下文,预测什么)的选择相对用来训练的学习方法,对结果向量的影响大得多。这方面在词嵌入算法后面介绍。
2. 词向量训练算法
将词视作连续空间中的一个点,即词的连续表示,也可以分为两种:分布式表示(Distributional Representations),分散式表示(Distributed Representations)。
分布式表示,即通过共现矩阵的方式来进行词的表示,词的意义来源于其在语料中的分布。算法学习的是共现模式。
离散式表示,即将语言表示为稠密、低维、连续的向量,每个词被表示为“a pattern of activations”值构成的向量,词的意义以及与其他词之间的关系通过向量中的激活值和向量之间的相似性来反映。算法学习的是激活模式。
这两种表征看起来相距甚远,也就产生了不同族的算法和思考方式,但深层次上有关联关系,后面再讲。
(1)分布式表示
分布式表示使用 word-context 矩阵来捕捉词的分布式特性,表示为 M,其元素表示一个词和一个 context 之间的信息强度,通常用 PMI 计算。
从而,词向量可以用矩阵 M 的行来表示。
word-context 矩阵的一大缺点是数据稀疏和高维度。通常用 SVD 分解为低阶矩阵来表征。(这里讲到的 SVD 分解提到了一些近似理论,很有趣,有空再记录下)
(2)离散式表示
离散式表示中,词的含义不仅蕴含在整个词向量的所有维度里,还蕴含在其他词向量的维度中,即离散表示的向量维度是不可解释的,特定维并不对应特定概念。
前面提到的语言模型的表达式中,矩阵 W^2的列向量或者嵌入矩阵 E 的行向量即词的离散式表示。
但这毕竟是语言模型任务的副产品,有两个重要要求:
① 计算所有词的概率分布,即需要计算涉及词表中所有词的正则化项,计算开销太大
② 根据上下文去计算句子级的概率估计,即需要依据链式规则进行分解,从而限制了根据上下文处理 k-grams
如果只关注结果的词表示,则可完全解决这两个限制。
Collobert and Weston 与2008提出的模型解决了这个问题,Bengio 在2009又进行了深入处理。
用 w 表示目标词,c(1:k)表示有序词串,对于只有一个隐层的 MLP,输入是串联 w 和 c(1:k) 的向量表示,输出时对这对 word-context 的打分,如下式:
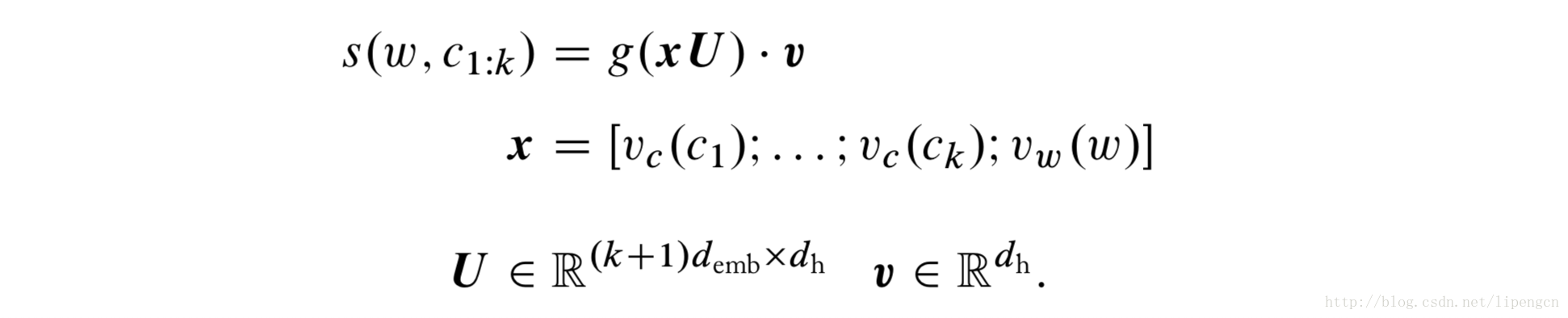
训练采用基于豁余的排序损失,以保证对正确 word-context 对的打分高于错误 word-context 对的打分至少豁余量1。即表示为
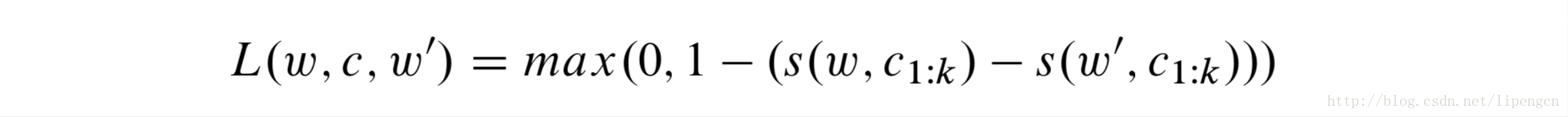
其中,w’是词表中的随机词。
训练过程就是重复处理语料中的 word-context 对,每次都是:随机抽样词 w’,计算 L,更新 U、v 和词、context 的 embedding 来最小化 loss。
这里提到的随机抽样 word 形成错误的 word-context 对的 negative sampling 法来进行优化,在 word2vec 中也有使用。
这里介绍下 word2vec,实际上它算一个工具包,实现了两种不同的 context 表征方式(CBOW 和 Skip-Gram),以及两种不同的优化目标(Negative-sampling 和 Hierarchical Softmax)。
这里介绍下基于Negative-sampling目标的吧。
类似于Collobert and Weston的方法,也是让网络学着区分好的和差的word-context 对,但 word2vec 做了些改变:将基于豁余的排序损失换成基于 sigmoid 的概率表示;大幅简化了word-context 对的打分定义。
如基于 CBOW 的 word2vec 实现直接将 context 所有词的 embedding 向量的加和表示为 context 向量,然后 s(w,c)=wc。这样虽然损失了 context 中词序信息,但使得变长 context 成为可能。
基于 Skip-gram 的 word2vec 实现进一步解耦了 context 中词之间的依赖,虽然解耦很彻底,但实践表现性能很好。
(3)两者关联
分布式方法和离散式方法,都是基于 Distributional hypothesis 的,都尝试从词所出现的 context 的相似性上来捕获词的相似性。
word2vec 训练会得到两个嵌入矩阵,E^W ∈ R^(|V_W × d_emb|) 和 E^C ∈ R^(|V_C × d_emb|),分别表示 word 和 context。一般舍弃 E^C 留下E^W。实际上 E^W × (E^C)^T = M’ ,可以发现,word2vec 隐式分解了word-context 矩阵 M’。
(4)其他类型算法
除了上面提的,还有不少 word2vec 算法的变种,目前还未能定性或定量分析他们的性能差异。包括 NCE 和 GloVe。
3. context 的选择
预测 word 所用的 context 的选择,对所得的词向量和对相似度的编码具有重要的影响。
(1)最常用的划窗法,即目标词和前 m 个词以及后 m 个词。
更大的窗口,倾向于产生更局部的相似性,如dog、bark、leash更可能聚到一起,walked、walking、run 更可能聚到一起。
更小的窗口,倾向于产生高跟功能性或语义层面的相似性,如 poodle、pitbull、rittweiler,walking、running、approaching。
如果倾向于更语义层面的相似性,除了小窗口,还可以配合加入 context 的位置信息。
(2)用目标词所在的句或段的所有词来做 context。
其实相当于非常大尺寸的窗口。
(3)用语义窗口来代替词窗口。
这种方式能产生高度功能性的相似性,即集合起那些能在句子里充当相同角色的词。
4. 预训练词向量的使用
使用预训练词向量时,有些选择需要考量。
(1)预处理
即使用时直接用还是讲每个向量归一化到单位长度?
在很多词嵌入算法中,词向量的范数和词频有关,对词向量进行归一化会损失掉频率信息,这可能算是一致性的需要,也可能是一种不该有的信息损失。这和具体任务有关。
(2)再训练
即针对目标任务是否以及如何对预训练词向量再精细化训练?
考量词嵌入矩阵 E ∈ R^|V|×d。
① 将 E 视为模型参数,和网络其他参数一样进行更新训练。
虽然表现不错,但可能由于带来不像要的副作用,即训练数据中存在的词的 representation 将改变,而原有的和其相似的词却没变,这将损害预训练词向量中的泛化能力。
② 保持 E 不变。
虽然保留了预训练词向量的泛化能力,但缺失了对给定任务的适应性。
③ 保持 E 不变,但训练一个变换矩阵 T ∈ R^d×d,词向量不再从 E 中查行向量而是矩阵 E’=ET 的行向量。
T 可以使得预训练向量的某些方面关于给定任务得到再训练。但是,通常任务相关的适配应该是针对所有词的线性变化,而非只是训练数据中出现的那些词。这个方法的缺点就是只能针对那些训练数据中存在的词进行线性变换。
④ 保持 E 不变,但训练一个变换矩阵 A ∈ R^|d|×d,词向量不再从 E 中查行向量而是矩阵 E’=E+A 或者 E’=ET+A 的行向量。
矩阵 A 初始化为零向量,并随着网络进行训练,可以学习到特定词的加性变化。
5. 基于 Distributional hypothesis 的局限性
(1)相似性在实践中有很多方面,基于 Distributional hypothesis 的上述方法完全没法控制它们学习到的相似性,只有对 context 进行有条件的筛选能稍微起点控制的作用。
(2)词所蕴含的很多更细节的性质可能没有反映在文本中,自然也就没法被 representation 捕获。不过这是由于语言文本的 well-documented bias 导致的,自然误导了基于 Distributional hypothesis 的上述方法。
(3)反义词由于常出现在相同的 context 中,从而认为是相似的。
(4)基于 Distributional hypothesis 的上述方法得到的最终词向量是和 context 无关了,但实际上词的含义和其 context 有关,即一词多义。显然对一个词在所有使用场景都使用一样的向量是不合理的。
6. 应用
(1)获取词向量
直接使用预训练词向量,要注意应用场景是否一致,毕竟应使用的训练集很可能不一致。
网上有修改过的 word2vec 二进制文件,可以根据需要修改 context 方式。
Polyglot project 提供了多语种的预训练词向量。
(2)词的相似度
一般用两个词向量的 cosine 相似度。
(3) 词聚类
聚好的类可以作为后续学习算法的离散特征使用。
(4)检索相似的词
简单的矩阵乘法 s=Ew 得到的就是所有词和词 w 之间的相似度,然后按值取前 k 个最大值即可。
(5)寻找一组词的最相似词
(6)剔除最差异的词
(7)短文本相似度
短文本计算相似度特别适合使用词向量。通常定义为
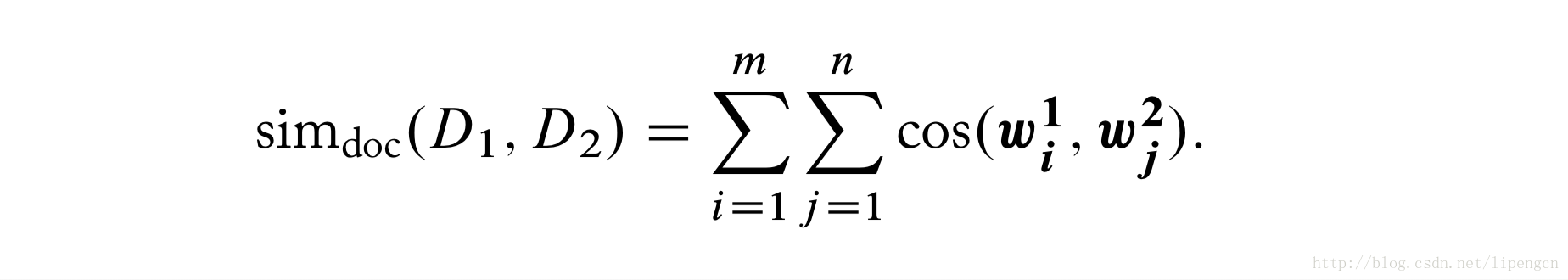
对于归一化了的词向量,可以直接写作
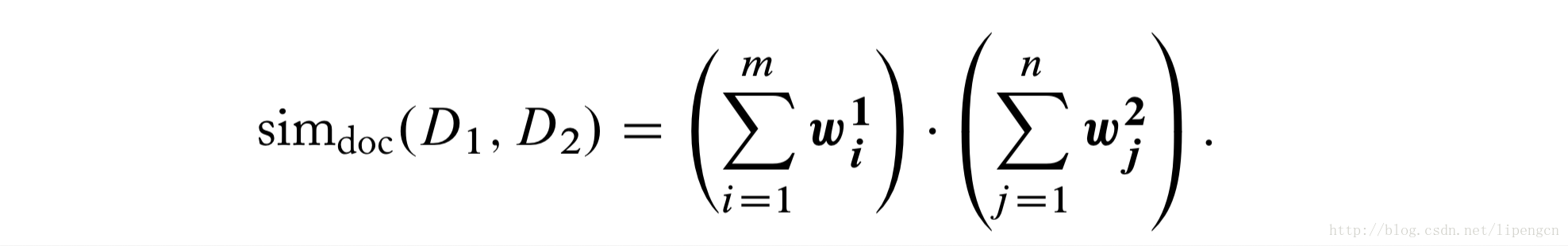
当然,上述方法表现不错,一般作为很不错的 baseline,但当有训练数据时,用上监督学习可以进一步提升表现,如 Parikh2016 为 SNLI 语义推理任务所提的网络结构
(8)词的类推
(9)改造
当我们找到一个规模更大更有代表性的词对集,比预训练的词向量更能反映想要的相似性,Faruqui2015提出的 retrofitting 方法可以利用这些数据来提高词向量矩阵的质量。主要思想描述如下:
① 假设矩阵 E 为预训练词向量矩阵,图 G 用来编码词和词之间的二进制相似性——图上的节点为词,如果两个词相似则用边相连(显然在边上加上权重就实现0-1连续相似性),很简单可以吧上述词对集表征为图 G。
② 构造OP:寻找新的词向量矩阵 E’,其中行向量不仅与 E 中相应行相似还和图 G 中相应邻居们的行相似,目标函数表示为
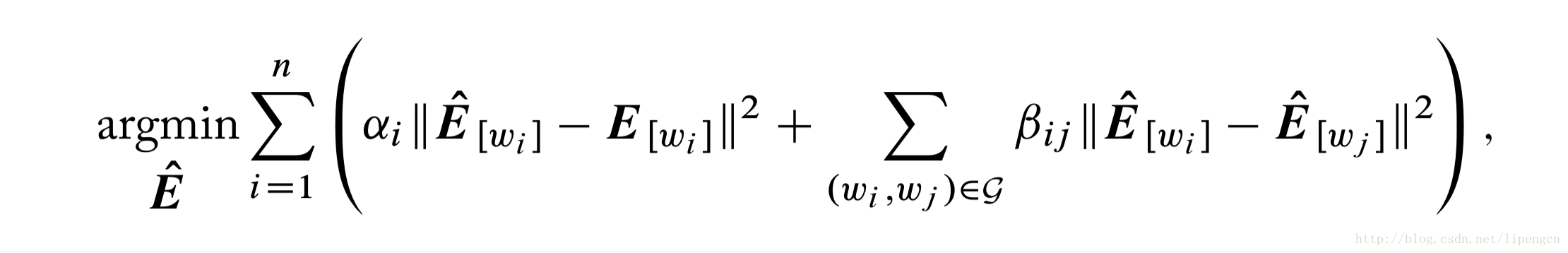
(10)映射
当我们拥有两个预训练词向量矩阵,一个词表较小,一个词表较大,两个是分开训练的因此不相容。也许较小词表的矩阵反而是用更复杂的算法训练的,而较大词表的矩阵是从网上下载的。一般这两个词表彼此有重叠的部分,我们期望用较大矩阵 E^L 中的词向量来表示较小矩阵 E^S 中不存在的词的向量。这两个嵌入空间的桥接就需要用到 Kiros2015、Mikolov2013 提出的线性映射方法。主要思想描述如下:
① 训练目标是寻找一个好的映射矩阵 M ,对那些两个词表公有的词,将 E^L 相应行更近地映射到 E^S 的相应行,即表示为
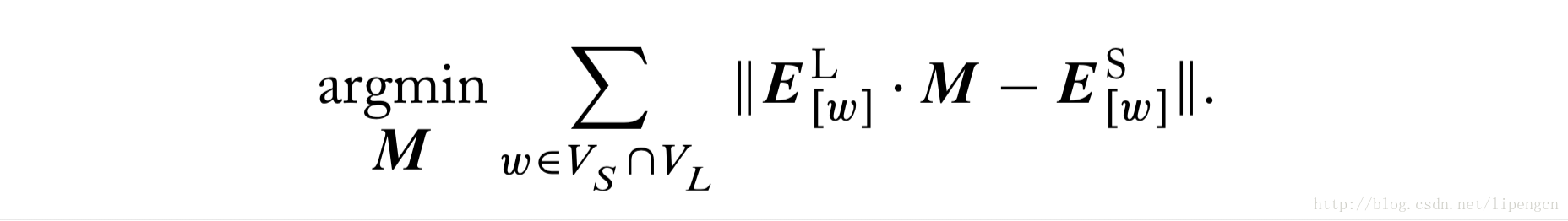
② 学好的矩阵 M 也可以用来从 E^L 映射 E^S 中没有的相应行。该方法被 Kiros2015用来增加基于 LSTM 句子编码器的词表扩展。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









