









一、 启动IDEA
进入/home/iespark/hadoop_program_files/idea-IC-143.1184.17/bin,执行“./idea.sh”。
二、 新建工程
点击File->new->project,弹出对话框,选择Java->Kotlin(Java)(如图1.1),点击next,输入项目名,项目保存路径,点击Finish,NewWindow新工程至此创建完成。
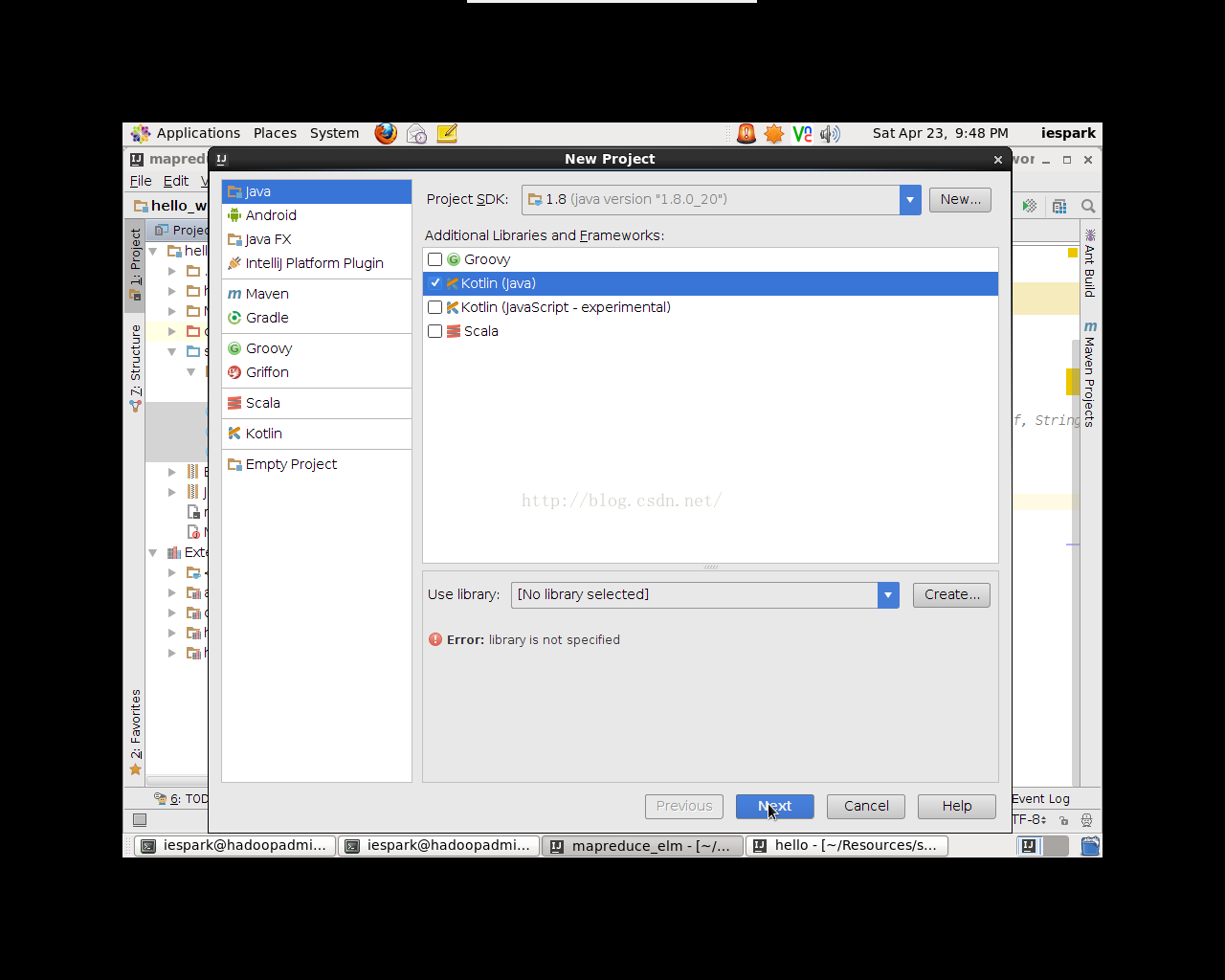
图1.1创建新工程
三、 导入JAR包
点击File->ProjectStructure,弹出对话框(如图2.1)。选择Libraries(与eclipse的lib一个道理),点击“+”号,选择JAVA,在弹出的窗口中选择需要导入的JAR包的位置(如图2.2),此例中只需导入conmmon(3个jar)和mapreduce张的jar包即可(在hadoop-2.6.2/share/Hadoop/)。
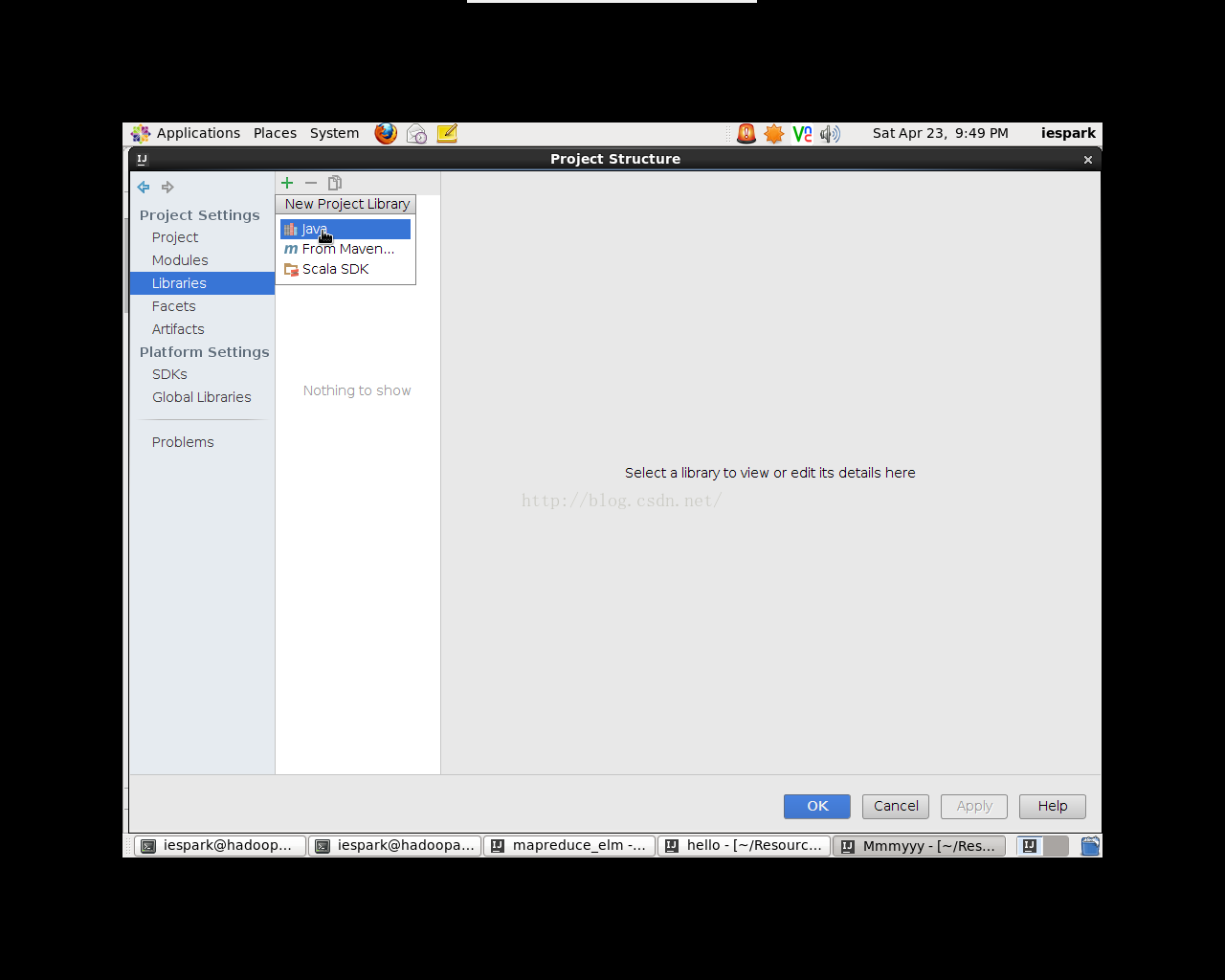
图2.1 创建Lib文件
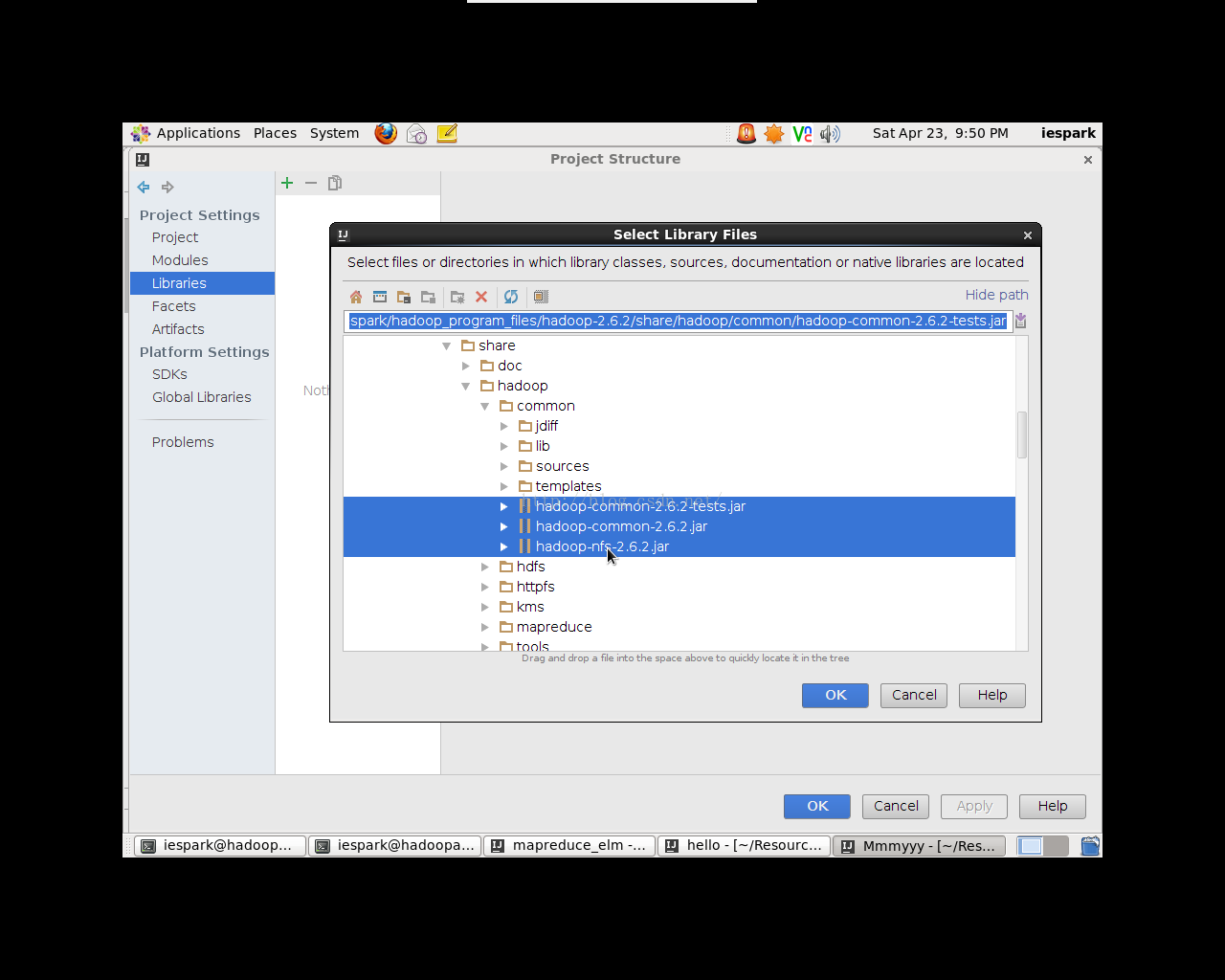
图2.2 导入Jar包
四、 编写程序
编写WordCount程序,该程序分为三个部分,Map类、Reduce类以及Main。以下是个各类的具体代码
注意:修改代码之后,一定要点击saveall保存(笔者未知原因)
Map类
| import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException; import java.util.StringTokenizer;
/** * Created by iespark on 2/26/16. */ public class WcMapper extends Mapper<LongWritable,Text,Text,IntWritable>{ @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { // IntWritable one=new IntWritable(1); String line=value.toString(); StringTokenizer st=new StringTokenizer(line); //StringTokenizer "kongge" while (st.hasMoreTokens()){ String word= st.nextToken(); context.write(new Text(word),new IntWritable(1)); //output } } } |
Reduce类
| import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException;
/** * Created by iespark on 2/26/16. */ public class McReducer extends Reducer<Text,IntWritable,Text,IntWritable> { @Override protected void reduce(Text key, Iterable<IntWritable> iterable, Context context) throws IOException, InterruptedException { int sum=0; for (IntWritable i:iterable){ sum=sum+i.get(); } context.write(key,new IntWritable(sum)); } } |
Main
| import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
/** * Created by iespark on 2/26/16. */ public class JobRun { public static void main(String[] args){ Configuration conf=new Configuration(); try{ Job job = Job.getInstance(conf, "word count"); //Configuration conf, String jobName job.setJarByClass(JobRun.class); job.setMapperClass(WcMapper.class); job.setReducerClass(McReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job,new Path("/input/wc")); FileSystem fs= FileSystem.get(conf); Path op1=new Path("hdfs://219.226.86.155:9000//output/wc"); if(fs.exists(op1)){ fs.delete(op1, true); System.out.println("存在此输出路径,已删除!!!"); } FileOutputFormat.setOutputPath(job,op1); System.exit(job.waitForCompletion(true)?0:1); }catch (Exception e){ e.printStackTrace(); } } } |
五、 导出JAR包
点击File->ProjectStructure,弹出对话框(如图4.1)。选择Artifacts,点击“+”号,选择JAR->Frommodules with dependencies…,在弹出的窗口中选择Main Class的位置(如图4.2),选择JabRun,选择导出JAR包的位置,一路OK即可完成。
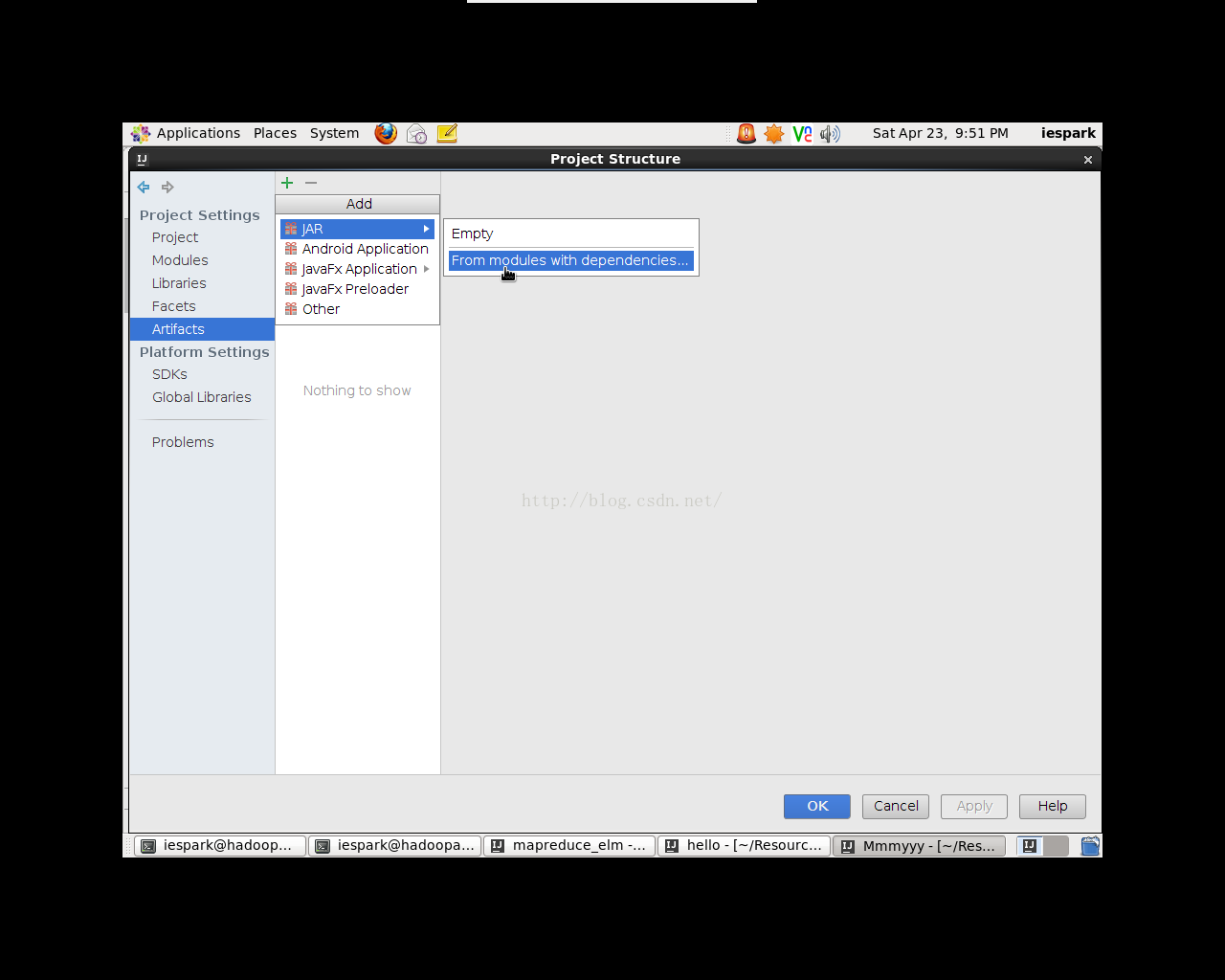
图4.1 导出jar包
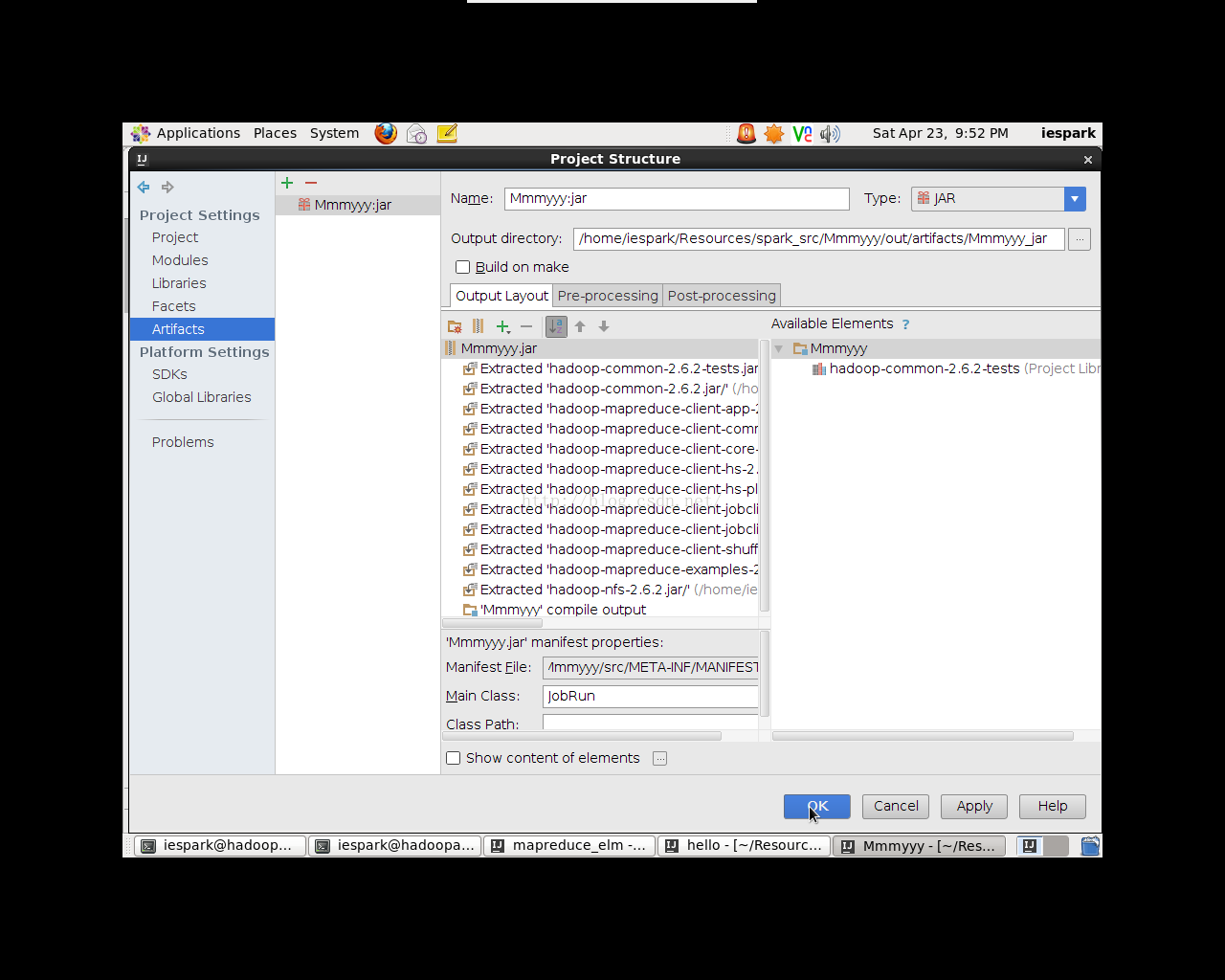
图4.2 导出完成
这里需要注意,导出之后的JAR包还不能直接运行,需要经过buildArtifacts过程。如图4.3,点击菜单栏Build->BuildArtifacts,此时JAR包才算导出成功。
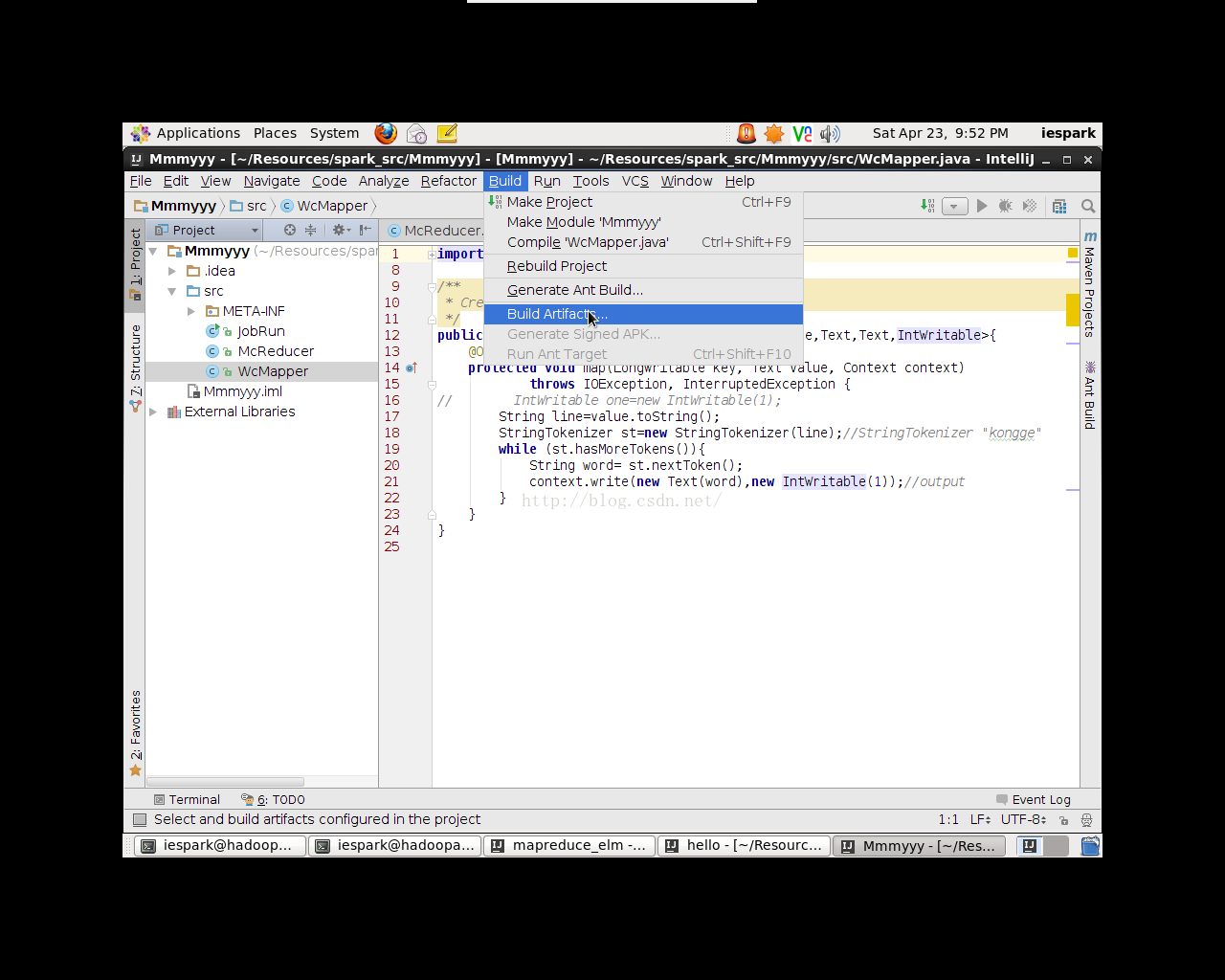
图4.3 BuildArtifacts
六、 运行
6.1 导入输入文件
首先在本地创建好原始输入文件(命名为word_count),之后在HDFS上新建“/input”目录,将本地的文件上传到HDFS的/input上,并命名为wc。
| [iespark@hadoopadmin ~]$ hadoop dfs -mkdir /input [iespark@hadoopadmin zzh]$ hadoop dfs – put ./word_count /input/wc |
6.2 执行JAR文件
到导出的JAR包所在目录执行JAR包,具体命令如下:
| [iespark@hadoopadmin Bymyself_jar]$ hadoop jar Bymyself.jar |
6.3 查看结果
结果保存在HDFS上,可通过网页访问(http://namenode-name:50070)也可以通过如下命令访问。
| [iespark@hadoopadmin ~]$ hadoop dfs –ls /oupput/wc Found 2 items -rw-r--r-- 2 iespark supergroup 0 2016-04-25 16:49 /output/wc/_SUCCESS -rw-r--r-- 2 iespark supergroup 28 2016-04-25 16:49 /output/wc/part-r-00000 [iespark@hadoopadmin ~]$ hadoop dfs –text /output/wc/part-r-00000 |














 1070
1070











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









