







 超级会员免费看
超级会员免费看
目录
1. UnBounded的双流JOIN:
https://developer.aliyun.com/article/672760?spm=a2c6h.13262185.0.0.6c007e186Tt5n
是双流驱动,即任何一个流有新数据过来都会触发计算。
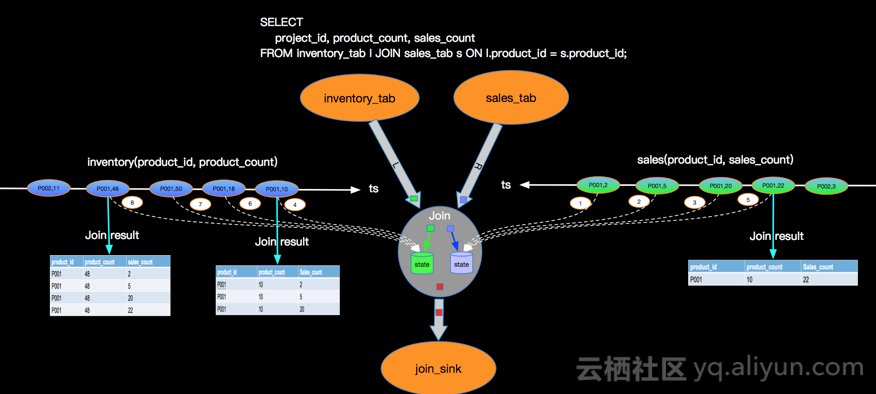
关联过程:左右两边的没进来一条数据,都会保存到state中,然后与另一边的state中的数据进行关联,然后输出。
sql的写法,和普通mysql表关联的sql写法是一样的,支持inner join、left/right outer join。
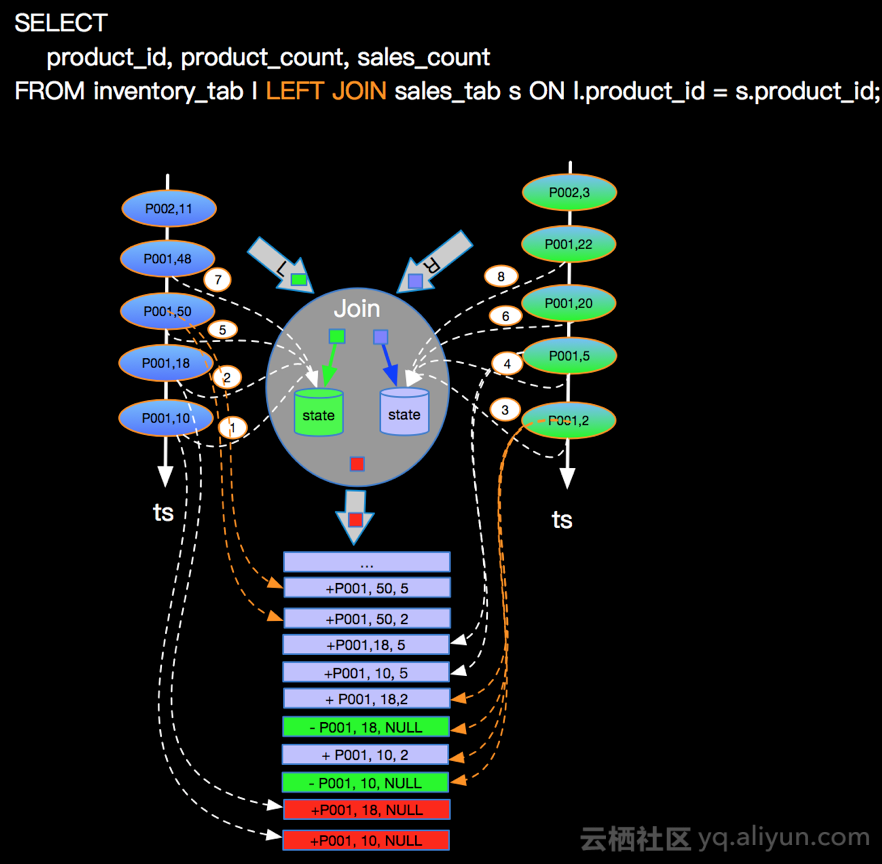
如下inner join场景和left join的流程图:
inner join只有关联上才会输出结果,left join则左边来了会先输出(右边没关联上就置为null,等右边来新的数据可以关联上左边的数据,则会先回撤结果,然后再新增。+代表正向记录,-代表撤回记录)
2. 单流与UDTF的JOIN操作:
3. 单流与版本表的JOIN:
由左边的单流驱动,temporal join。左表是流,右表是temporal table
temporal table 支持FOR SYSTEM_TIME AS OF语法,
例如DDL语句
CREATE TABLE Emp
ENo INTEGER,
Sys_Start TIMESTAMP(12) GENERATED
ALWAYS AS ROW Start,
Sys_end TIMESTAMP(12) GENERATED
ALWAYS AS ROW END,
EName VARCHAR(30),
PERIOD FOR SYSTEM_TIME (Sys_Start,Sys_end)
) WITH SYSTEM VERSIONINGDML语句
INSERT INTO Emp (ENo, EName) VALUES (22217, 'Joe'),说明: 其中Sys_Start和Sys_End是数据库系统默认填充的。
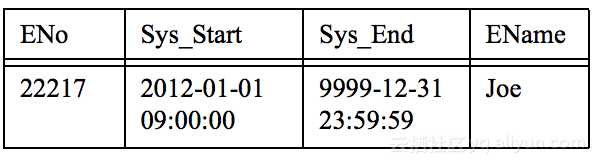
例如查询:
SELECT ENo,EName,Sys_Start,Sys_End FROM Emp
FOR SYSTEM_TIME AS OF TIMESTAMP '2011-01-02 00:00:00'
说明: 这个查询会返回所有Sys_Start <= 2011-01-02 00:00:00 并且 Sys_end > 2011-01-02 00:00:00 的记录。https://github.com/ververica/flink-sql-cookbook/blob/main/joins/03_kafka_join/03_kafka_join.md
Apache Flink 漫谈系列(11) - Temporal Table JOIN-阿里云开发者社区
https://developer.aliyun.com/article/679659?spm=a2c6h.12873639.0.0.47903da5UARE9V
4.interval join
在UnBounded数据流上按时间维度进行数据划分进行JOIN操作 - Time Interval(Time-windowed)JOIN, 后面我们叫做Interval JOIN:
https://developer.aliyun.com/article/683681















 2562
2562











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









