







总结
-
flat的源码你确定你能看懂??各种调库的操作对小白也太不友好了吧~
-
本博客分成两部分,第一部分(part1)主要描述了一下复现flat可以参考的文档,数据集等;第二部分(part2)主要讲了论文的核心内容
update in 20230411
今天重新温故了一下Flat这篇文章的细节,准备复现一下其代码,发现论文真的是有太多问题了~
(1)因为添加过span的字符串与原来的已经不一致了,所以作者就把之前的Self-Attention 中的权重计算方式修改成了如下这个样子:

实际上这个权重的计算来源于Transformer-xl这篇文章,仔细对应如下左半部分:

按照Flat文中给出的计算方法,
A
i
,
j
A_{i,j}
Ai,j 这个计算的结果是
d
h
e
a
d
∗
d
h
e
a
d
d_{head} * d_{head}
dhead∗dhead 维度,而不是一个数值。具体的推导过程如下:

可以发现文中的公式是存在问题的。
(2)再看下面这张图,真实的句子中“重庆人和药店”肯定都是有标点符号的。但是在这个展示的例子中没有任何的符号。
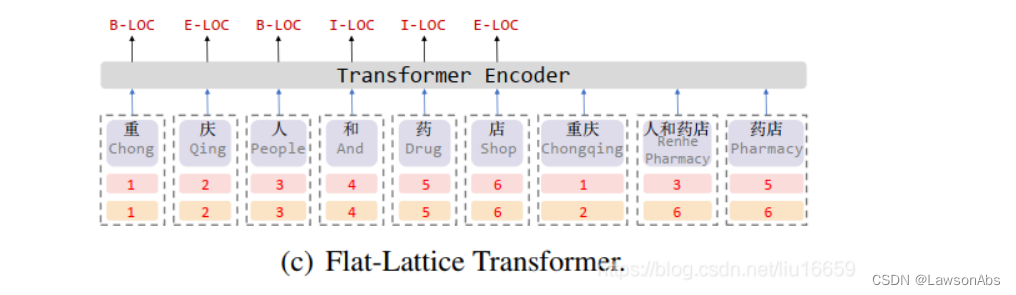
(3)仍然是上一个问题,我们在使用词典中的信息时,该如何从词典中找词呢?是使用那种顺序?比如上图中的结果是:
“重庆人和药店重庆人和药店药店”,还是“重庆人和药店人和药店药店重庆”,还是“重庆人和药店人和药店重庆药店”? 即这个词典的顺序对词有影响吗?
(4)作者应该是没有使用任何分隔符分割这些拼接的词,相反使用的是几个矩阵用来模拟词间的相对位置关系。但是我现在怀疑用“分割符”分割这个拼接得到的序列是否就能很好的取代了作者写的这个attention?毕竟后面很多工作都是这么做的。而且当时作者那会儿还不流行使用分隔符。
(5)模型的输入是什么?是 “重庆人和药店重庆人和药店药店” 这种文本?还是说是按照 “重庆人和药店(重庆)(人和药店)(药店)” 这种形式把字典中得到的各个词当做一个整体作为输入?
BERT的输入依旧是原始文本,然后得到的结果再交由 flat layer层处理。而flat layer 层中词的输入则是BERT的输出,而词的输入则是词典中词对应的embedding。
1 参考文档
本文介绍一种FLAT方法用于做中文NER。
- 论文地址。
- 论文的Github:https://github.com/LeeSureman/Flat-Lattice-Transformer
大家需要多根据issues 发现问题和解决问题,原作者对大多数问题进行了比较完整的回答。很多时候,不是因为解决不了问题,而是因为GitHub用的不熟悉。 - 作者讲演视频:https://www.bilibili.com/video/BV1Z54y1y766?from=search&seid=16334174024820448071
2 数据集
- WeiboNER:
flat这份工作中,作者对原Weibo数据集进行了稍微的修改,然后得到了下面这个网盘中的数据集,具体的修改方式我不清楚。
链接:https://pan.baidu.com/s/1SxsvSY1L446hb4zToRb1sA 提取码:7v5y - 其它数据集可以在链接 https://github.com/RowitZou/LGN 中获取具体的对应数据集(如下图所示)。

1.任务
中文NER
1.1中文NER和英文NER的区别
1.1.1 英文NER
英文NER 是基于单词(在我心中,其实这也是字哇),但为什么英文NER的任务就较轻松于中文NER 呢?是因为英文单词多种组合的情况很少,上下词确定时,其含义就比较唯一固定了。
1.1.2 中文NER
不同于英文NER(英文NER是以单词为单位),中文NER通常以字符为单位进行序列标注建模。但是我觉得中文NER较英文NER复杂的根本原因有两个,分别是:
第一:英文中的一个单词就约等于中文某个词组的效果。比如说:beautiful就相当于中文中的漂亮的,英文一个单词就可以解决,但是中文却需要使用三个字符才可以表示。
第二:中文NER中,按照字为单位后,其后续过程中遇到的组合种类更多,具有的不确定性更大。比如:重庆人和药店 就可以理解成如下两种方式:
重庆人,和,药店重庆,人和药店
而且这两种拆分方式没有固定的答案,需要通过上下含义才能得到。
1.2 论文动机?
基于分词的方法导致的误差使得中文NER只能基于字符的方法来做。但是将整句话分词字,就无法利用词的信息了。重庆人和药店这句话,将其作为单个字符来训练模型时,就不能利用上重庆,人和药店这两个词语。我们都知道,在深度学习中,该利用上的数据都应该使用,从而使得模型具备更好的拟合效果。于是便提出了基于词汇增强方式的FLAT 算法诞生了。
2. 相关工作
2.1 Lattice LSTM

这个工作我目前尚不是很清楚。
3.主要思想
文章的contribution就只有一个:
使用一种位置编码方式能够还原出 flat lattice 的信息,从而能够可以更好的得到训练效果。
3.1 什么是span?
 上面图中的每个绿色框框就是一个span。例如:
上面图中的每个绿色框框就是一个span。例如:重,人,人和药店等都是span。
3.2 什么是flat lattice?
lattice 本意为栅栏,栅格。下图就是一个形象的lattice结构:

3.3 将 lattice 式的DAG 转为flat lattice时,如何保持原序列结构?
在NER 问题中,位置信息是很重要的。flat的作者在transformer 的positional embedding的设计下,想到了能否使用一种各个span的相对编码方式从而保证原序列的结构信息?

- 可以看到整个图被压平了,所以称之为FLAT
3.4 如何利用flat之后的信息?
lattice 给我们flaten了,但是该怎么利用这些信息呢?有两个处理:
- 将序列分成了head 和 tail 两种
- 利用这个head 和 tail 信息做一个相对位置操作。也就是文中说的:
To encode the interactions among spans, we propose the relative position encoding of spans.For two spans xi and xj in the lattice, there are three kinds of relations between them: intersection, inclusion and separation, determined by their heads and tails.
也就得到了如下的信息:
d
i
j
(
h
h
)
=
h
e
a
d
[
i
]
−
h
e
a
d
[
j
]
d
i
j
(
h
t
)
=
h
e
a
d
[
i
]
−
t
a
i
l
[
j
]
d
i
j
(
t
h
)
=
t
a
i
l
[
i
]
−
h
e
a
d
[
j
]
d
i
j
(
t
t
)
=
t
a
i
l
[
i
]
−
t
a
i
l
[
j
]
d_{ij}^{(hh)} = head[i] - head[j] \\ d_{ij}^{(ht)} = head[i] - tail[j]\\ d_{ij}^{(th)} = tail[i] - head[j] \\ d_{ij}^{(tt)} = tail[i] - tail[j]
dij(hh)=head[i]−head[j]dij(ht)=head[i]−tail[j]dij(th)=tail[i]−head[j]dij(tt)=tail[i]−tail[j]
然后根据上面的这些数据,可以得到一个相对位置编码数据。

这里的
W
r
W_r
Wr是可学习参数,其它的参数与attention中原有的参数很像~ 【我不是很清楚】
4.源码阅读
4.1 可以参考我之前写的文章如何读源码?
4.2 如何跑通这份代码?
跑通这份代码可以用WeiboNER数据集(也就是原作者的数据集。)示例效果还是很贴合论文中的数据的,(水分还是比较少哇~)。但是下面我的讲解示例是用的是自己的一份数据集(TianchiNER)。
运行代码的时候需要注意配置fitlog,同时最好在Linux机器上跑(是因为有小伙伴在windows上跑的满是bug~)。
4.3 数据集
关于原作者的数据集,我在原作者的GitHub中的issues中说的很清楚了,这里再补充一下吧。
- 微博有份原始数据集是叫 WeiboNER ,可以在链接https://github.com/hltcoe/golden-horse/tree/master/data ,但是作者把这个数据集做了一定的修改,以便方便代码使用,修改后的文件如果需要可以加我微信(wxID就是csdn昵称),我私发给大家(网盘操作稍微麻烦,就不搞了~)
- 其它的数据集像 onetonotes,msra 我就不提供了,对于学习这份代码应该没有太大的影响 ~
4.1 宏观架构
先看一下宏观的过程,也就是对应论文中的那个花花绿绿的图:

下图中的红框的1,2,3,4 就代表上述的Embedding,slef-attention,Add & Norm,FFN,Add & Norm,Linear &CRF 中的一个或某几个步骤。下面仔细讲讲:
- 1代表的就是将embedding ,位置信息交由attention 处理
其中的self-Attention, Add&Norm , FFN, Add&Norm等操作都被封装到encoder 中了,所以只需要使用一个encoder()就行了。 - 2代表的是将attention处理的结果放到最后一层的Linear 中操作
- 3.代表的就是上步的结果做CRF 操作。
 其中embedding 是由 embed_char 和 embed_lex 两者合并得到的。
其中embedding 是由 embed_char 和 embed_lex 两者合并得到的。

4.2 微观调试
这一部分主要是仔细的查看整个过程变量的变化,以及处理的细节问题。
4.2.1 数据准备
为了方便调试,这里就用了几个字作为数据用于训练和测试。如下数据作为本次调试中的数据。

4.3 类的使用
在这个代码中,数据集的加载并非是pytorch 中的dataset 作为数据集的封装,而是用的fastNLP中自带的类。主要涉及到DataSet, Vocabulary,Embedding 三个部分。其功能分别是:封装数据集;词典中词到下标的映射;将词映射成embedding。
4.4 数据生成的概括
主要的加载过程如下:
 - load_tianchi_ner() 方法是用于加载我自己的一个数据集,返回值是datasets,vocab, embeddings
- load_tianchi_ner() 方法是用于加载我自己的一个数据集,返回值是datasets,vocab, embeddings
- load_yangjie_rich_pretrain_word_list() 方法是用于加载词典信息,这个涉及到后面的datasets中lexicon的使用
- equip_chinese_ner_with_lexicon() 方法是用于将词典信息写入datasets中
4.5 数据生成的详细过程
下面讲一下数据生成的详细过程:
chars:是原生的文本
target:就是序列标注的结果,也就是label。但是通常会将其写成target
bigram: 这个是文本的连续的分割结果。分割方法是连续两两分割,比如对于上面的dev数据集,得到的 bigram 就是下面这样:

字典中存在的词语有:

[0,1,'本品'] ,前两个数字代表起止下标,后面代表匹配的词语。
下面这个就是遍历每一个 datasets,然后交由concat

concat() 的功能就是把找到的词语拼接到之前的话中,得到ins[‘lattice’],结果如下:


各个字段的含义是什么?
seq_len:语句长度
lexicons:加入的词典信息
raw_chars: 源char
lex_num:表示raw char匹配词典中词的个数
lex_s: 各个匹配词中匹配的起始下标
lex_e: 各个匹配词中匹配的终止下标
lattice:源字符串匹配词典添加在源字符串之后得到的结果
在经过下面三个 apply操作,
 数据就变成如下的样子了:
数据就变成如下的样子了:

由 datasets['train']['lattice'] 可以得到 lattice_vocab ,其值如下:
 其长度为:
其长度为:



可以看到datasets 这个变量的值的变化。变化的原则是:把datasets中每个汉字改为对应vocab中的值的下标,Vocabulary这个类的作用就是实现字到下标的转换。(详细知识可以在Vocabulary的源码中看到)
至此datasets这个变量值的设置就完成了,接下来就需要操作 vocabs 这个变量了。
StaticEmbedding 这个实现自 TokenEmbedding,但是TokenEmbedding实现自nn.Module,所以前二者都有 forward()方法用于将一个tensor处理。这里以 StaticEmbedding 为例,介绍其forward的方法:

其方法中做了三件事儿:
- drop_word
- 得到words 的 embedding。这个embedding是 pytorch 自身模块中的 nn.Embedding的一个实例。
经过所有的处理之后,datasets 的值形式如下:
 传入模型中训练的数据就是 datasets[‘train’] ,如下:
传入模型中训练的数据就是 datasets[‘train’] ,如下:

真正训练时传入 forward 的是batch_x,

其值如下:

那么 lexicon 是怎么生成的呢?在add_lattice.py 下面的代码中:

其中get_skip_path() 如下:

其中chars是datasets[‘train’]中的chars值,也就是原生的字符串。w_trie是通过 词典得到的一个word_list,然后将其放入到了一个Trie树中。 get_lexicon()方法是用一个二重循环的方法去寻找一个匹配的result。得到的结果就是上面注释的这种,也如下面这个图所示:


难点
- fastNLP,fitlog 等开源的学习
- 源码阅读过程遇到的问题,解决问题的过程?
参考文章
- https://mp.weixin.qq.com/s/5-B4IRQ3Y_sTdryu4dNuNQ















 2033
2033











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











