







总结
- 文章来源:LawsonAbs(CSDN)
- 不适合入门选手
1.Self-Attention
1.1 Q:下面这个图是怎么得到的呢?

上面这个图讲得是:每个单词对其它单词的一个关注度。我们attention之后不是只得到一个向量吗? (左侧这句话是错误的)怎么会有关注度(attention score)呢?仔细读读下面这段话:
As we are encoding the word “it” in encoder #5 (the top encoder in the stack), part of the attention mechanism was focusing on “The Animal”, and baked a part of its representation into the encoding of “it”.
也就是说:it这个单词的 embedding 是结合了The , animal 等一系列单词的权重得到的embedding。同样,对于单词animal 也会用一系列的加权值来表示它的向量,即对于每个token,都有:
t
o
k
e
n
=
∑
i
=
1
n
α
i
∗
v
i
token = \sum_{i=1}^n \alpha_i * v_i
token=i=1∑nαi∗vi
对应于下面这张图:
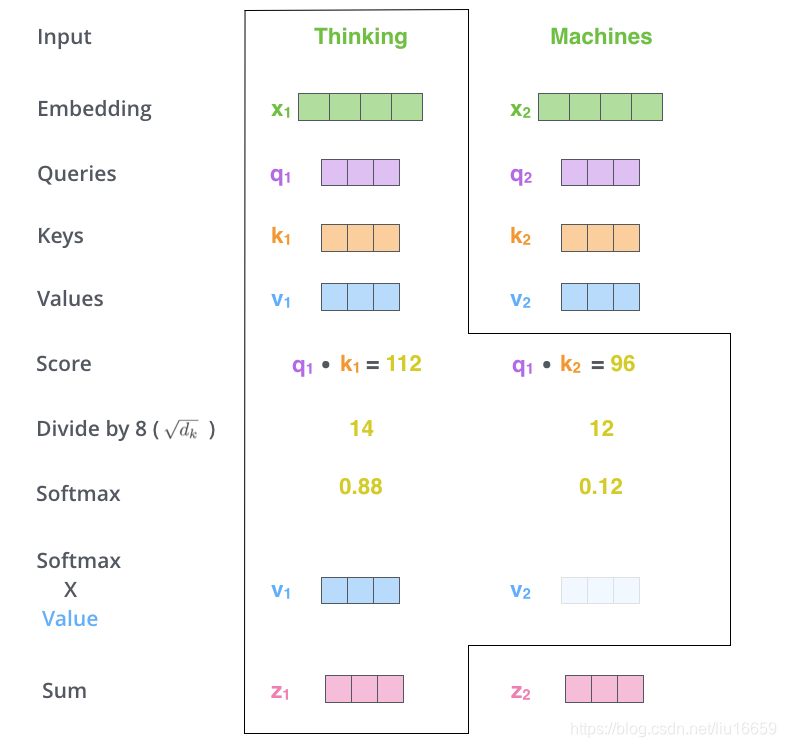 向量
向量z1 和向量 z2 不同的原因在于==在计算attention值的时候,采用的不是同一个q。==也就是说,在计算Thinking这个单词用的是
q
1
,
k
1
,
k
2
,
v
1
,
v
2
q_1,k_1,k_2,v_1,v_2
q1,k1,k2,v1,v2,但是计算Machines 这个单词用的是
q
2
,
k
1
,
k
2
,
v
1
,
v
2
q_2,k_1,k_2,v_1,v_2
q2,k1,k2,v1,v2 所以会得到一个不同单词对其它单词的关注度(但是事实证明,attention并不是像作者们说的这么有效,大家听听就好~,有兴趣深究的可以看我的博客:Bert实战二之探索Attention score)。
由上可知,不能单纯的以为attention 只能把一句话编码成一个向量!它还可以self-attention 把句子中的每个token都编码成一个向量。
2. 代码细节
2.1 在 key-value attention 中, 随机生成的 Query, Key 矩阵 在每个批次训练中是否是一致的?也就是说,这两个矩阵是否是全局唯一的?
我觉得是的,因为需要针对这两个也是参数,需要对应训练,如果总是变化,肯定是不可的。
3.有哪些attention?
从软硬的角度来分析
- 软性attention
- 硬性attention
从打分
-
普通attention
-
键值对attention
这个也就是我们常说的QKV attention,这种方法 -
多头attention
4. attention score 的计算方法有哪些?
给定一个和任务相关的查询向量q,以及输入向量x, W , U , v W,U,v W,U,v均为可学习参数,那么通常有如下几种方式计算注意力得分:
- 加性模型 s ( x , q ) = v T t a n h ( W x + U q ) s(x,q)=v^T tanh(Wx+Uq) s(x,q)=vTtanh(Wx+Uq)
- 点积模型 s ( x , q ) = x T q s(x,q)=x^Tq s(x,q)=xTq
- 缩放点积模型 s ( x , q ) = x T q D s(x,q) = \frac{x^T q}{\sqrt{D}} s(x,q)=DxTq
- 双线性模型 s ( x , q ) = x T W q s(x,q) = x^T W q s(x,q)=xTWq
在得到这些score 之后,再使用 softmax 计算出 注意力分布。
5. global attention 和 local attention 的区别是什么?
5.1 global attention
就是常说的attention:对所有输入信息进行一个attention操作。
5.2 local attention
为了解决 global attention 时间复杂度较高的原因,所以就可以将其优化成只专注一部分,即衍化成 local attention。 local attention 的主要步骤如下:
- 首先确定一个中心位置 p t p_t pt
- 然后人为选择一个窗口大小参数 D D D,以 p t p_t pt 为中心,得到窗口 [ p t − D , p t + D ] [p_t -D, p_t + D] [pt−D,pt+D]
在得到的窗口上进行一个 attention 操作。
参考资料
- The Illustrated Transformer
- 生活中的加权求和就是attention 的真实来源。
- 邱锡鹏《nndl》
- https://zhuanlan.zhihu.com/p/80692530 【讲解global attention 和 local attention 的区别】















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











