







1. 文件重命名
file.rename()
2. 画图的par()函数变回默认值
device.off()
3. apply函数加额外参数
x <- matrix(1:12, 3, 4)
apply(x, 1, function(x, a) sum((x-a)^2), a =3)
4. 表的合并
R中的表合并
一、merge函数外连接合并)
>merge(x = df1, y = df2, by ="CustomerId", all = TRUE)
CustomerId Product State
1 1Toaster <NA>
2 2Toaster Alabama
3 3Toaster <NA>
4 4 Radio Alabama
5 5 Radio <NA>
6 6 Radio Ohio
左连接:
merge(x = df1, y = df2, by="CustomerId", all.x=TRUE)
CustomerId Product State
1 1Toaster <NA>
2 2Toaster Alabama
3 3Toaster <NA>
4 4 Radio Alabama
5 5 Radio <NA>
6 6 Radio Ohio
右连接:
> merge(x = df1, y = df2, by="CustomerId", all.y=TRUE)
CustomerId Product State
1 2Toaster Alabama
2 4 Radio Alabama
3 6 Radio Ohio
交叉连接:
> merge(x = df1, y = df2, by = NULL)
CustomerId.x ProductCustomerId.y State
1 1 Toaster 2 Alabama
2 2 Toaster 2 Alabama
3 3 Toaster 2 Alabama
4 4 Radio 2 Alabama
5 5 Radio 2 Alabama
6 6 Radio 2 Alabama
7 1 Toaster 4 Alabama
8 2 Toaster 4 Alabama
9 3 Toaster 4 Alabama
10 4 Radio 4 Alabama
11 5 Radio 4 Alabama
12 6 Radio 4 Alabama
13 1 Toaster 6 Ohio
14 2 Toaster 6 Ohio
15 3 Toaster 6 Ohio
16 4 Radio 6 Ohio
17 5 Radio 6 Ohio
18 6 Radio 6 Ohio
使用sqldf包查询合并表
##eg:sqldf("SELECT *FROM df1 where CUstomerId=2"
CustomerId Product
1 2Toaster
内连接:
sqldf("SELECT CustomerId, Product,StateFROM df1 JOIN df2 USING(CustomerID)"
CustomerId Product State
1 2Toaster Alabama
2 4 Radio Alabama
3 6 Radio Ohio
左连接:
sqldf("SELECT CustomerId,Product,State FROM df1 LEFT JOIN df2USING(CustomerID)"
CustomerId Product State
1 1Toaster <NA>
2 2Toaster Alabama
3 3Toaster <NA>
4 4 Radio Alabama
5 5 Radio <NA>
6 6 Radio Ohio
三、使用plyr包
library(plyr)
join(df1, df2,type="inner"
CustomerId Product State
1 2Toaster Alabama
2 4 Radio Alabama
3 6 Radio Ohio
Type的选项包括:inner、left、right、full(内连接,左连接,右连接,外连接)
四、使用dplyr包
library(dplyr)
> inner_join(df1,df2,by="CustomerId"
CustomerId Product State
1 2Toaster Alabama
2 4 Radio Alabama
3 6 Radio Ohio
> left_join(df1,df2)
Joining by: "CustomerId"
CustomerId Product State
1 1Toaster <NA>
2 2Toaster Alabama
3 3Toaster <NA>
4 4 Radio Alabama
5 5 Radio <NA>
6 6 Radio Ohio
> semi_join(df1,df2)
Joining by: "CustomerId"
CustomerId Product
1 2Toaster
2 4 Radio
3 6 Radio
> anti_join(df1,df2)
CustomerId Product
1 1Toaster
2 3Toaster
3 5 Radio
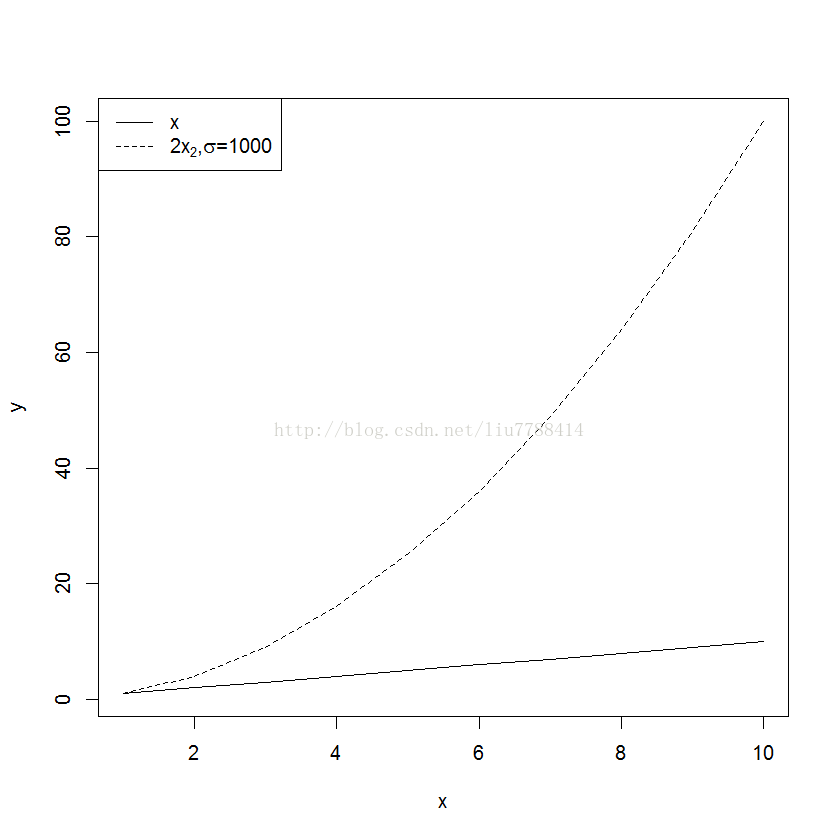
5. 绘制图例
plot(x^2,type = "n",ylab ="y" , xlab = "x")
lines(x, lty = 1)
lines(x^2, lty = 2)
legend.txt <-c("x",expression(paste("2",x[2],",",sigma,"=1000")))
legend("topleft", legend =legend.txt, lty = c(1,2))
6. 快速读取大规模数据
Data.table包fread函数可以快速读取大规模文件,4GB文件读取时间可以在1分钟左右。代码示例如下
require(data.table)
system.time(DT <-fread("test.csv"))
## user system elapsed
## 3.12 0.01 3.22
7. 陷阱:在循环内部改变循环变量
i<-0
for (j in 1:3) {
print(j)
if (i==0&&j==2){i<-(i+1)
j<-(j-1)
print(j+100)
}
}
结果竟然是
[1] 1
[1] 2
[1] 101
[1] 3
为什么不是
[1] 1
[1] 2
[1] 101
[1] 2
[1] 3 ??
循环是按照顺序来的 j =1, 2, 3, 4, 5, ...
在每个循环体内,你可以对 j随意赋值。但是到下一个循环开始的时候 j总会变成比前一个循环多1的值,而不管前面循环体内 j是多少
你开始的程序写出来其实就是
i <- 0
j <- 1
print(j)
if (i==0&&j==2) {
i <- (i+1)
j <- (j-1)
print(j+100)
}
j <- 2
print(j)
if (i==0&&j==2) {
i <- (i+1)
j <- (j-1)
print(j+100)
}
j <- 3
print(j)
if (i==0&&j==2) {
i <- (i+1)
j <- (j-1)
print(j+100)
}
另外一个例子:
for(j in 1:3){
print(j)
j<-"hi stcopy"
print(j)
j<-1.5555
print(j)
}
8. 函数内部访问全局域
a <- 1
x <- "abc"
listVar <- function() {
b <- "local b"
print(ls())
print(ls(pos =".GlobalEnv"))
}
9. 选取上下三角矩阵
upper.tri()
lower.tri()
分别返回矩阵的上三角和下三角
10. 构造等比数列
a=10
i=seq(1,4,1)
y=a*10^i
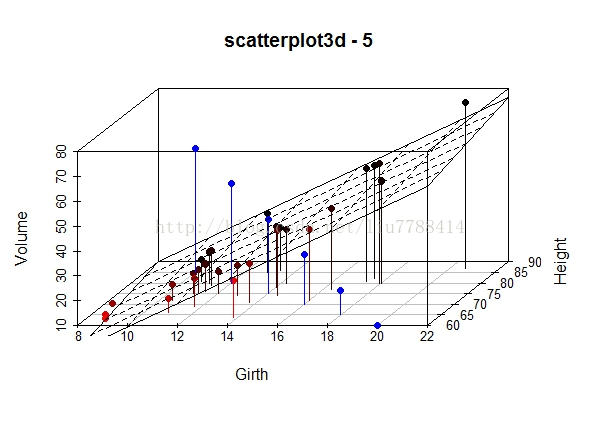
11. 三维网格图
library(scatterplot3d)
## example 5
data(trees)
s3d <- scatterplot3d(trees,type="h", highlight.3d=TRUE, angle=55, scale.y=0.7, pch=16,main="scatterplot3d - 5")
# Now adding some points to the"scatterplot3d"
s3d$points3d(seq(10,20,2), seq(85,60,-5),seq(60,10,-10), col="blue", type="h", pch=16)
# Now adding a regression plane to the"scatterplot3d"
attach(trees)
my.lm <- lm(Volume ~ Girth + Height)
s3d$plane3d(my.lm, lty.box ="solid")
12.library与require的区别
载入需要的包时,library,reuqire都可以使用
存在区别是,require()返回一个布尔值,library返回一个地址的值
> t <- library("ac")
Error in library("ac") : 不存在叫‘ac’这个名字的程辑包
> t
[1] "#FF0000FF""#80FF00FF" "#00FFFFFF" "#8000FFFF"
> t1 <- require("ac")
载入需要的程辑包:ac
Warning message:
In library(package, lib.loc = lib.loc,character.only = TRUE, logical.return = TRUE, : 不存在叫‘ac’这个名字的程辑包
> t1
[1] FALSE
13. 判断某个日期是星期几
#day.of.week() returns a number between 0 and6 to
#specify day of the week–0 refers toSunday.
library(chron)
print(day.of.week(2,8,2010)) #1
print(day.of.week(2,9,2010)) #2
print(day.of.week(2,10,2010)) #3
print(day.of.week(2,11,2010)) #4
print(day.of.week(2,12,2010)) #5
print(day.of.week(2,13,2010)) #6
print(day.of.week(2,14,2010)) #0
print(day.of.week(2,15,2010)) #1
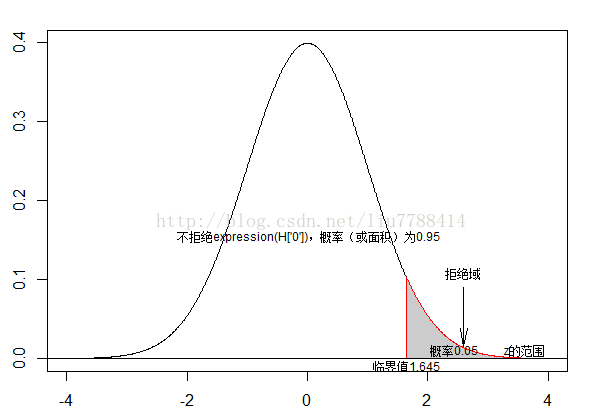
14. 带数学表达式的曲线图
par(mfrow = c(1,1))
xv<-seq(-4,4,0.01)
yv<-dnorm(xv)
plot(xv,yv,type="l",xlab="",ylab="")
polygon(c(xv[xv>=1.645],1.645),c(yv[xv>=1.645],yv[xv==4]),col="grey80",border = "red")
text(2.1+0.5, dnorm(1.645), "拒绝域", adj= c(0.5, 0), cex = 0.75)
arrows(2.6,0.09,2.6,0.015, angle = 10)
text(1.65, -0.015, "临界值1.645",adj = c(0.5, 0), cex = 0.75)
text(2.45, 0.005, "概率0.05",adj = c(0.5, 0), cex = 0.75)
text(0, 0.15, " 不拒绝expression(H['0']),概率(或面积)为0.95",adj = c(0.5, 0), cex = 0.75)
#这里似乎不行,我需要弄出H_0来,还望指点一二!谢谢
text(3.6, 0.005, "z的范围", adj= c(0.5, 0), cex = 0.75)
abline(h=0)
15. 注意冒号:优先级最高
例如,在R中,当n=10, n+1:n 的输出结果是 11 12 13 14 15 16 17 18 19 20;而n+2-1:n的输出结果是1110 9 8 7 6 5 4 3 2。
为什么输出的结果不一样呢?这是因为在R中:(冒号)的计算优先级高于加减法.前面两个例子等价于 n+(1:n), n + 2 – (1:n)















 816
816

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









