







1,SRAM高速缓存的结构
获取本机CPU的SRAM缓存信息
我使用的是一个叫cpuinfo_x86的小程序,可以获取x86架构的cpu相关信息。下载地址:http://osxbook.com/book/bonus/misc/cpuinfo_x86/cpuinfo_x86.c
gcc编译后运行,以下是当前测试环境的SRAM信息:
L1 Instruction Cache //L1指令缓存
Size : 32K
Line Size : 64B
Sharing : shared between 2 processor threads
Sets : 64
Partitions : 1
Associativity : 8
L1 Data Cache //L1数据缓存
Size : 32K
Line Size : 64B
Sharing : shared between 2 processor threads
Sets : 64
Partitions : 1
Associativity : 8
L2 Unified Cache //L2指令数据缓存
Size : 256K
Line Size : 64B
Sharing : shared between 2 processor threads
Sets : 512
Partitions : 1
Associativity : 8
L3 Unified Cache //L3指令数据缓存
Size : 3M
Line Size : 64B
Sharing : shared between 16 processor threads
Sets : 4096
Partitions : 1
Associativity : 12
Size是该缓存所有数据块的合计大小,Sets是总组数,Associativity是每组的行数,LineSize是每行的数据块大小。指令和数据缓存只用来缓存指令或内存数据,有利于CPU并行取指和访存提速,Unified Cache可以同时缓存两者,L1L2为每核心独享,L3为多核共享,整体结构大概如下图:
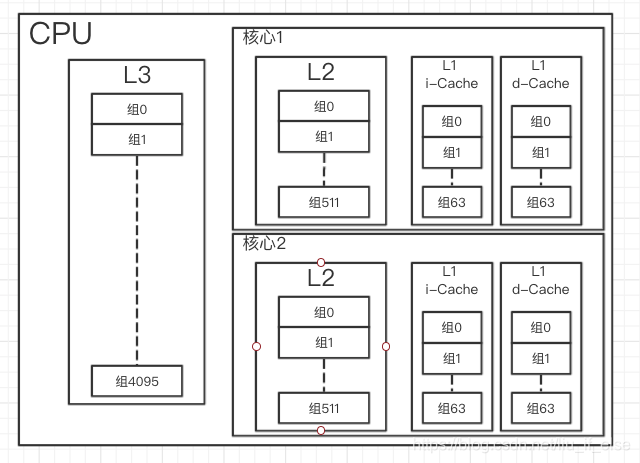
(图1)
内存数据在缓存中的定位与传输
假设有指令要从L1中读一个字节,内存地址为0000000000000000000000000000000000000000000000000000000000000000
由于L1缓存块大小64B,
64
=
2
6
64=2^6
64=26,所以最后六位用于计算数据块中的字节偏移,称为
b
位
\color{orange}b位
b位:
0000000000000000000000000000000000000000000000000000000000
000000
0000000000000000000000000000000000000000000000000000000000\color{orange}000000
0000000000000000000000000000000000000000000000000000000000000000
组数量也为64,那么可得出组的index为接下来的6位,称为
s
位
\color{red}s位
s位:
0000000000000000000000000000000000000000000000000000
000000
000000
0000000000000000000000000000000000000000000000000000\color{red}000000\color{orange}000000
0000000000000000000000000000000000000000000000000000000000000000
剩下的位用来寻找该组中存有该数据的行,称为tag标签,
t
位
\color{blue}t位
t位:
0000000000000000000000000000000000000000000000000000
000000
000000
\color{blue}0000000000000000000000000000000000000000000000000000\color{red}000000\color{orange}000000
0000000000000000000000000000000000000000000000000000000000000000
缓存的控制逻辑硬件解析内存地址后会先用s位定位组,然后并行的用t位定位行。如果找到了组和行既是缓存命中,会用b位来寻找数据位置(或数据起始位置)并返回数据。否则就是缓存不命中,会向下一级缓存读取数据。
每行都有一个数据块,数据块的基本单位为字节,例如L1的数据块为64字节,缓存着内存中0000000000000000000000000000000000000000000000000000000000至 0000000000000000000000000000000000000000000000000000111111的数据。每字节index与b位对应,例如上面要寻找的数据既是在下图行1中的数据块的字节0中:
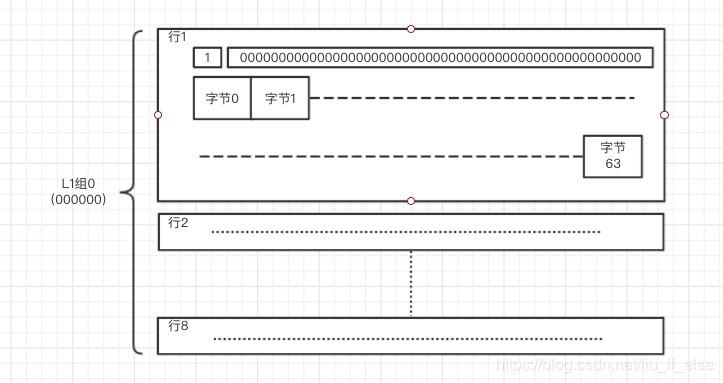
(图2)
通过这种机制将内存数据分布在SRAM缓存中有点类似于编程中的散列表。内存中每连续n个字节相当于要存储的value,内存地址的s位相当于key,缓存的组相当于桶,每个行相当于node。与散列表不同的是node数量有限制,如果超出数量限制,将会进行不同策略的行替换,另外每个node之间也没有链接关系,所有行用t位进行标记,由硬件进行并行搜索。
s,b,t位由缓存的结构决定,例如测试环境的L3缓存与L2,L1缓存对比:
L
1
:
0000000000000000000000000000000000000000000000000000
000000
000000
L1:\color{blue}0000000000000000000000000000000000000000000000000000\color{red}000000\color{orange}000000
L1:0000000000000000000000000000000000000000000000000000000000000000
L
2
:
0000000000000000000000000000000000000000000000000
000000000
000000
L2:\color{blue}0000000000000000000000000000000000000000000000000\color{red}000000000\color{orange}000000
L2:0000000000000000000000000000000000000000000000000000000000000000
L
3
:
0000000000000000000000000000000000000000000000
000000000000
000000
L3:\color{blue}0000000000000000000000000000000000000000000000\color{red}000000000000\color{orange}000000
L3:0000000000000000000000000000000000000000000000000000000000000000
这种设计使L1,L2,L3每级缓存之间的数据传输有以下的映射关系(组index由0改为1起始):
(图3)
由于内存很大,缓存相对很小,这种映射关系对于正常编程中的数据访问是合理的,但是由于映射关系固定,从L1的角度来看,整个内存地址中有1/64的地址段的数据(对于一个4GB内存来讲既是有64MB的数据)最终都是要缓存到它的某一个组中,如果大量反复访问该范围数据(64MB=1048576个数据块)会造成该组中大量的行替换,增加缓存不命中率,由于行替换会造成访存指令等待,进而导致CPU数据吞吐率降低。
2,缓存读不命中测试
缓存不命中有冷不命中,容量不命中与冲突不命中。缓存在空的状态下,任何读写操作都会造成冷不命中。当工作集(例如循环中要访问的内存地址)整体大小超出该缓存的最大容量时导致的不命中称为容量不命中。
冲突不命中与图3中的映射关系有关,由于内存数据向上一级传输的映射关系是固定的,反复访问内存中的某个子集内的数据会造成大量的不命中,例如根据测试环境,在Unity内进行以下测试:
using System.Collections;
using UnityEngine;
public class TestScript : MonoBehaviour
{
int[] array1 = new int[10000000];
// Use this for initialization
void Start()
{
int pTime;
int cTime;
int sum = 0;
Refresh();
pTime = System.Environment.TickCount;
sum = Sum1(sum);
cTime = System.Environment.TickCount;
Debug.Log("sum=" + sum);
Debug.Log("以步长8192循环:Time:" + (cTime - pTime));
Refresh();
pTime = System.Environment.TickCount;
sum = 0;
sum = Sum2(sum);
cTime = System.Environment.TickCount;
Debug.Log("sum=" + sum);
Debug.Log("以步长1循环:Time:" + (cTime - pTime));
Refresh();
pTime = System.Environment.TickCount;
sum = 0;
sum = Sum3(sum);
cTime = System.Environment.TickCount;
Debug.Log("sum=" + sum);
Debug.Log("以步长8191循环:Time:" + (cTime - pTime));
Refresh();
pTime = System.Environment.TickCount;
sum = 0;
sum = Sum3(sum);
cTime = System.Environment.TickCount;
Debug.Log("sum=" + sum);
Debug.Log("以步长8193循环:Time:" + (cTime - pTime));
}
void Refresh() {
for (int i = 0; i< array1.Length; i++)
{
array1[i] =UnityEngine.Random.Range(1, 100000);
}
}
int Sum1(int sum){
for (int i = 0,j = 1; j < 5000000;i = 8192 * (j % 1000),j = j + 1){
sum += array1[i];
}
return sum;
}
int Sum2(int sum)
{
for (int i = 0, j = 1; j < 5000000; i = 1 * (j % 8192), j = j + 1)
{
sum += array1[i];
}
return sum;
}
int Sum3(int sum)
{
for (int i = 0, j = 1; j < 5000000; i = 8191 * (j % 1000), j = j + 1)
{
sum += array1[i];
}
return sum;
}
int Sum4(int sum)
{
for (int i = 0, j = 1; j < 5000000; i = 8193 * (j % 1000), j = j + 1)
{
sum += array1[i];
}
return sum;
}
}
对一个一千万长的int数组(38.15MB)根据不同的步长进行50万次循环,测试结果:
以步长8192循环:Time:330
以步长1循环:Time:84
以步长8191循环:Time:95
以步长8193循环:Time:85
可以看出8192对于测试机来讲是一个神奇的数字,其原因可以从该机CPU的缓存结构中找出。int长度为4个字节32位,8192*4B=32768B=32KB,32KB正好是L1缓存的大小,也既是循环中的所有数据最终都要缓存到L1的组0,CPU对L1的所有访存指令都会造成不命中(除非L1在第一次缓存满八行后只对组中同一行进行行替换,那么在1000次循环中会有7次命中),同一个循环中L2与L3相对L1不命中率会稍微低一些,但是数据从内存到L3的时间会更慢,每次不命中造成的时间惩罚相对L1会更高,对整体的时间惩罚也有相当大的影响。
以上研究的都是读不命中的问题,写不命中时有两种策略,写分配与非写分配,写分配 的行为与读类似,会加载下级缓存数据上来直到L1后修改,非写分配 不加载数据而是不断尝试更改下级缓存中的数据。修改缓存数据后对内存数据的更新又分为写回与直写两种,写回的话每行要维护一个修改位,当该行被替换时如果发现有被修改过会对下一级缓存进行更改。直写是修改数据后立刻更新下一级缓存。这些策略是由硬件决定的。大量连续的直写对总线流量(SRAM<—>DRAM)有影响。写分配比较符合局部性的思想,例如对于小步长的循环,一次写不命中后加载数据到L1会避免之后再次的写不命中。
总之,在应用层面来讲,在循环中以步长为1来对数组进行遍历是最快的,而且最新的CPU还有一个prfetching预取机制(以上测试中的CPU没有),既是在循环前尽量提前将内存中的数组数据向上级缓存传输,在循环过程中提前对缓存中的数据进行更新,这是一个针对步长为1的循环的特殊硬件优化,可以规避容量不命中以及其他一些case。另外根据不同CPU对某个 2 n 2^n 2n为步长对一个超大的数组进行大量的循环是危险的,有可能会造成大量冲突不命中。
————————————————————————————————————
参考:
深入理解计算机系统—Randal E.Bryant, David R.O’Hallaron
维护日志:
2020-2-2:精简,重构














 3294
3294











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









