







在上一篇文章中对流程的认识做了介绍,内容不多但也是自己对整个流程体系的认知进行了梳理和沉淀,如感兴趣的朋友可以先行阅览:B端产品经理的流程设计思维(上)
本篇文章主要针对流程设计的实操过程中,对流程文件的定义,输出标准进行介绍(仅为笔者个人经验非行业标准,可自行取其精华,去其糟粕)
一、详细流程设计方法
1. 流程分层与流程文件类型的对应关系(L5流程的定位)
一个企业或者一个商业主体,在生产销售进行市场运营行为的过程中,涉及的流程可能成百上千,甚至破万。有的流程可能涉及公司战略走向或者上百万的经费调用,有的又可能只是一颗螺丝钉的入库流程;有的流程需要走系统走OA,几十级审批;有的可能又只是一条微信,一封邮件几次转发抄送,一个口头传达,心领神会。
那面对如此繁琐杂多各有千秋且的流程,在实际入手解决之前,共通的做法是先分级分类去定义,然后再做具体梳理和设计。对不同层级、定义的流程要代入不同的视角,考虑不同的利益核心。
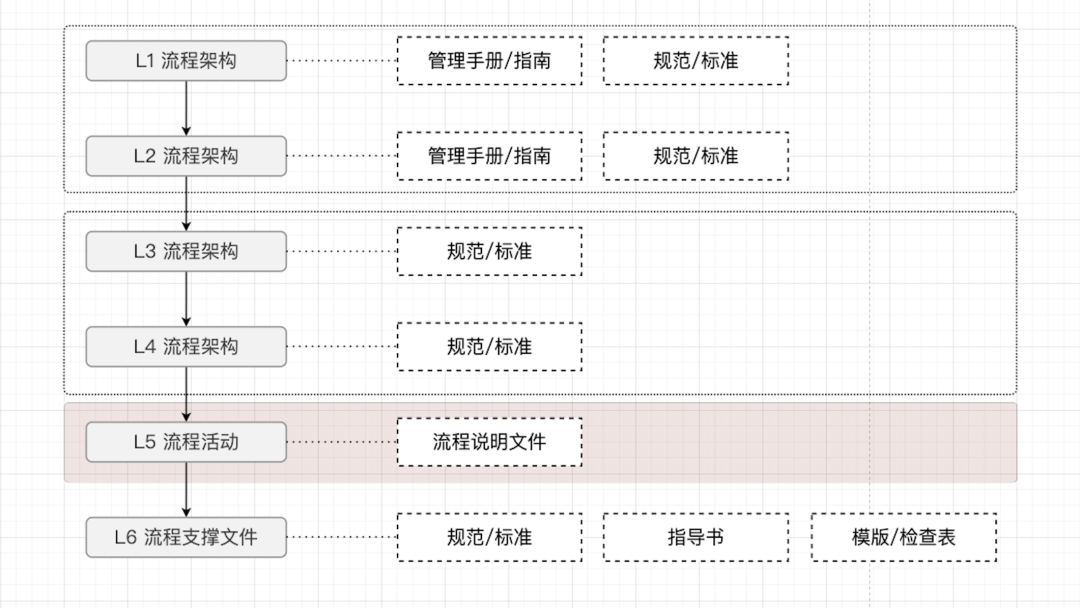
(年末事情比较多,抽空画的图,比较简陋)
上图做了一个简单划分,从L1到L6一共分为6级(如果企业规模较小,L1和L2可合并,L3和L4也可合并),由于笔者对L1到L4这个层级的流程架构设计参与较少,没有单独主导过,所以暂时没有沉淀出太多可靠的内容可分享,本篇文章就简单描述。核心内容会落在标注红色的L5级别的流程活动设计上:
L1、L2级别的流程架构,通常产出物为一些公司业务政策现状、管理手册、以及全公司适用和执行的规范和标准,主要目的为下:
体现公司的战略方向和业务模式
体现对业务整体性和系统性的思考
创造价值的主要业务流
L3、L4级别的流程架构,要注意的就是一些更细节的东西,因为你在给董事长股东汇报,或者攥写企业年报写L1、L2级别的内容的时候,肯定会选择性的跳过一些细节,例如集团本部的差旅费报销标准及流程或者订单履约规范及流程,就可以放到L3、L4中体现,主要目的为下:
体现各项业务具体做事方法和逻辑
对成功实践的系统性归纳和总结
指导执行层面的流程建设
L5级别的流程活动,这个级别的流程颗粒度需要非常细,在L3、L4的框架下,再要讲清楚什么角色要按照什么规范执行什么动作,输出什么结果给流程的下一位角色。以此明确及固化公司末级组织和一线人员的工作内容:
固化具体的流程活动内容、步骤、角色、规则、输入输出等;
L6 流程支撑文件,对L5流程活动形成支撑力的文件:
指导书/表单/模板等:沉淀打法、形成标准,指导IT开发。
2. L5流程的核心要素:一张图、一张表
2.1 一张图:流程图
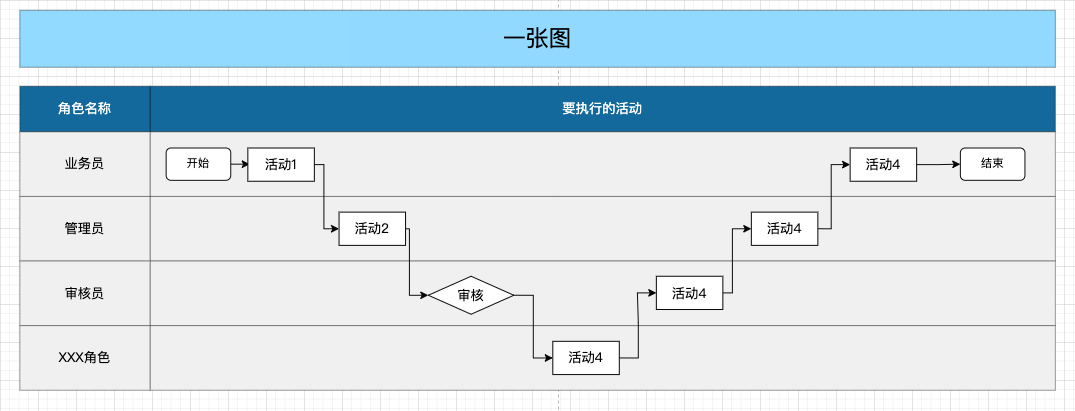
能看出来流程图的整体结构是列式分布,左侧一列为业务场景发生的过程中会卷入哪些角色(角色不一定等同于某一个人),右侧一列则是这些角色在整个业务场景中需要做什么活动,也许是审批,也许是知会。
在绘制右侧一列时,要想清楚每一个活动节点的前后关系,流转逻辑,再去布置节点进行连线,不要无限制的拆角色,拆活动,最终一个流程图又臭又长,事无巨细全铺出来,阅读理解成本极高。另外在流程图的绘制会有一些比较通用的规则,如下:
按照阅读理解习惯,流程的开始和结束,在流程图中如无特殊需求,尽量是按照从左上到右下的结构呈现;
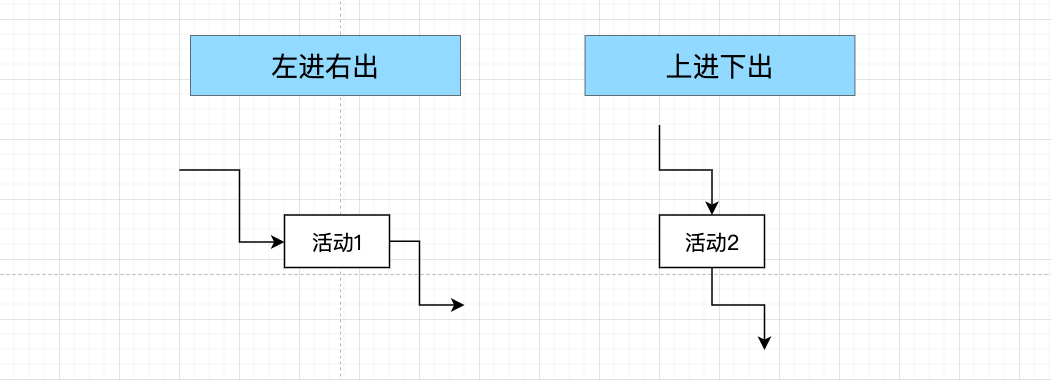
节点和节点之间连线时,标记箭头方向,明确节点完成后流转到哪里,一般按照左进右出,或者上进下出的原则进行绘制。整张流程图,尽量按照一个规则,不要一会儿左进下出,一会儿上进右出,在业务对接过程中可能造成歧义:
流程图里只能有一个开始,但是可以因为判断条件或其他活动产生多个结束;
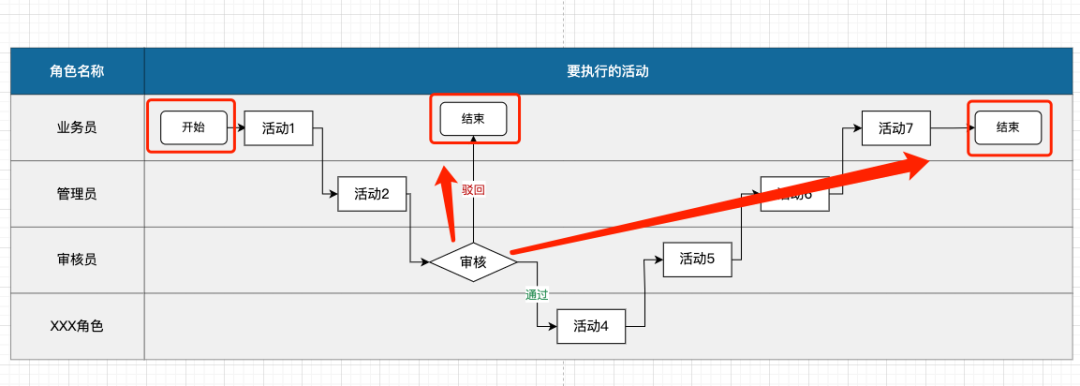
如果连续3个相邻的活动节点,刚好都是审核或者判断,为降低理解成本,可以拆开在中间插入一个无关紧要的动作打断一下,如果团队配合默契高能够快速达成共识,则可以不用;
一个流程,多个场景拆开做,不要做成结构图,如订单履约的场景,一个履约的场景可以拆出正反主流程去阐述,不要在一个图里无限衍生;
2.2 一张表:流程图的说明表
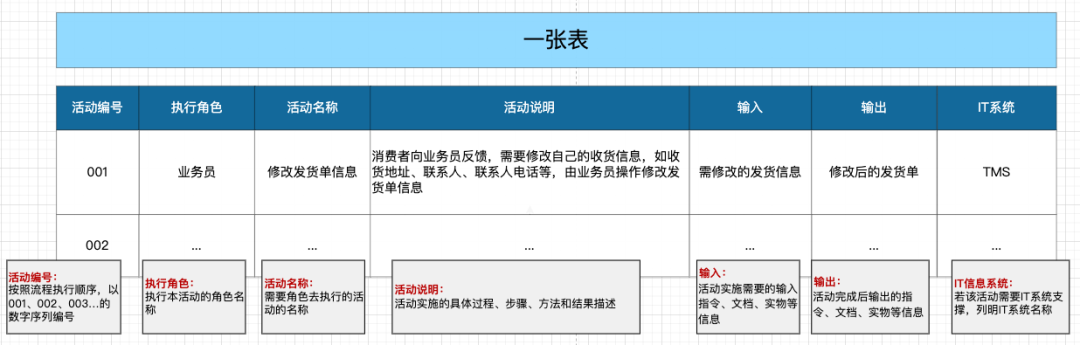
与流程图配套的说明文件,一张流程图对应至少一张说明表,说明表里对每一个活动节点都至少需要说明以下内容:
活动编号:按照流程执行顺序,以001、002、003…的数字序列编号
执行角色:执行本活动的角色名称
活动名称:需要角色去执行的活动的名称
活动说明:活动实施的具体过程、步骤、方法和结果描述
输入:活动实施需要的输入指令、文档、实物等信息
输出:活动完成后输出的指令、文档、实物等信息
it系统:若该活动需要IT系统支撑,列明IT系统名称
在流程图及文字说明表输出以后,需要跟业务反复磋商,每一个活动对应的说明都要讨论到,并且要明确告知流程文档是要签字画押的。大多数业务同学很少参与到类似的数字化过程中,产品经理作为IT侧代表在进行研讨会或者业务摸底时,实际上业务都会以一种发散性的思维来回答你的问题,在他与产品经理进行业务描述的过程中,一定会出现信息失真的情况,会有偏差、歧义,东一榔头西一棒槌,这很正常,所以才会有产品经理或者流程师、架构师之类的岗位,不要因为过程中这种阻力对业务产生情绪,我们要做的是,认认真真的听业务说话,仔细思考辨别,哪些他是说的线下动作,哪些是系统流转,哪些是上传下达,哪些是心领神会。
比如业务描述他的动作为:他在业务走到某某节点需要提个单给领导,那我们需要引导提问:你在提单之前的前置动作是什么,你是接到了什么信息或指令;或者咨询业务领导,这一环节为什么要提单给你确认,是业务政策规范性的规定吗?为什么会有这样的规定。他在提这张单的时候,承载形式是什么,oa或者其他系统,或者邮件,或者其实就是口头知会。单据内容有哪些信息?里面的每个信息对应的作用是什么你都逐一确认吗?提完单同意了后续动作要做什么?业务的前置动作加当前活动加后续动作,之间的必然联系与可能流转到大后方的联动规则是什么等等……
这种属于纸上谈兵了,每个公司内部自带的文化性格不同,沟通频率节奏不同,到什么山头就唱什么山歌,各位看官自行辨别,接着说回文件输出
3. L5流程绘制指引 6步法
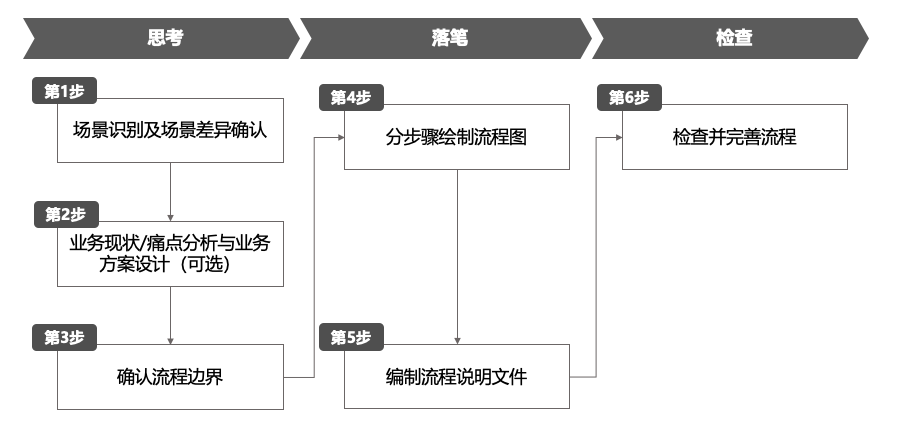
在我们去梳理绘制产出L5流程文件的过程中,大致可以按照思考、落笔、检查这3个阶段和6个步骤来完成,当然根据企业内部的管理情况,也是自行优化减少或增加步骤的;
3.1 第1步:场景识别及场景差异确认
场景识别:业务场景是什么?业务场景描绘的是为了完成业务目标相关的交互过程,包括:时间、地点、人物、在什么情况下、要做什么、怎么解决等要素。
场景差异确认:什么情况下流程图需要区分场景差异?
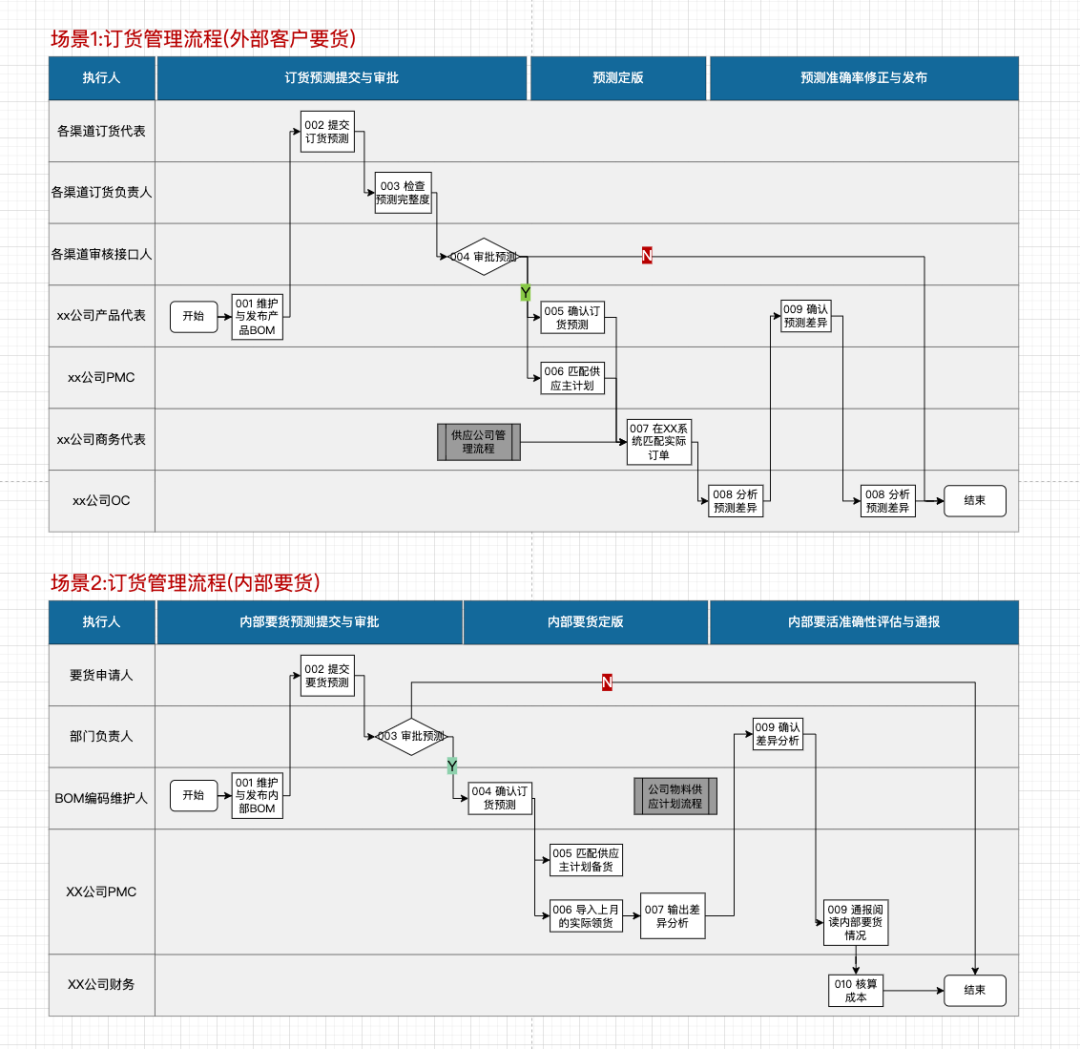
当业务流程在不同场景下存在显著差异时,需要区分不同的场景编写流程图;
“流程名称”后以括号说明场景,如订货管理流程(外部客户要货)/订货管理流程(内部要货);
场景差异示例:
下图中的两个场景都为某一集团公司的订货管理流程,不过因为外部客户向集团公司要货,和集团下属子公司或其他BU向集团公司要货,所要走的业务流程存在显著差异,无法通过简单的说明进行区分,故而拆分为两份流程图说明。
3.2 第2步:痛点分析和业务解决方案设计
梳理团队及内容:由业务专家+流程专家(多数企业没有流程师岗位,由产品岗代替)构成梳理团队:梳理需确保流程的目标明确、流程颗粒度一致、接口流程清晰,流程操作相关人员达成共识。
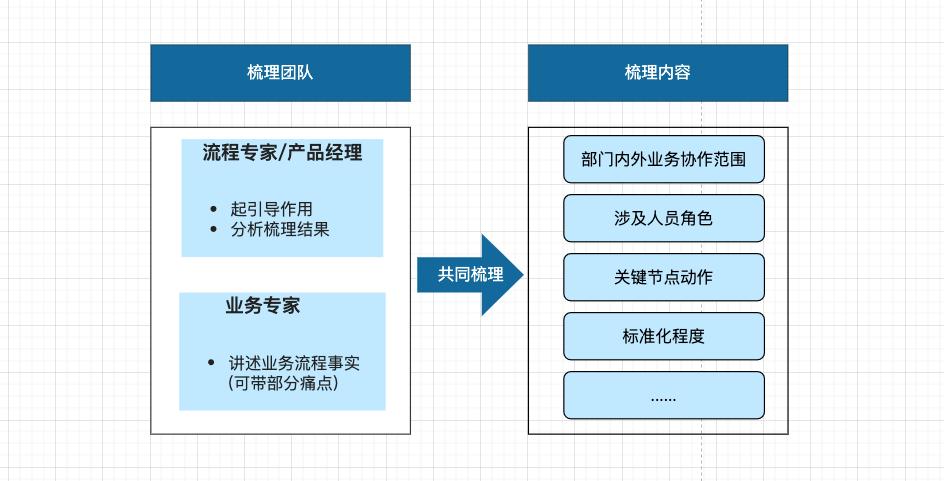
梳理方法:可通过研讨会,或白板法(准备一块白板,若干便利贴,在讨论过程中将讨论到的点快速记录后贴在白板上)
流程梳理表:对会议讨论的结果进行盖棺定论
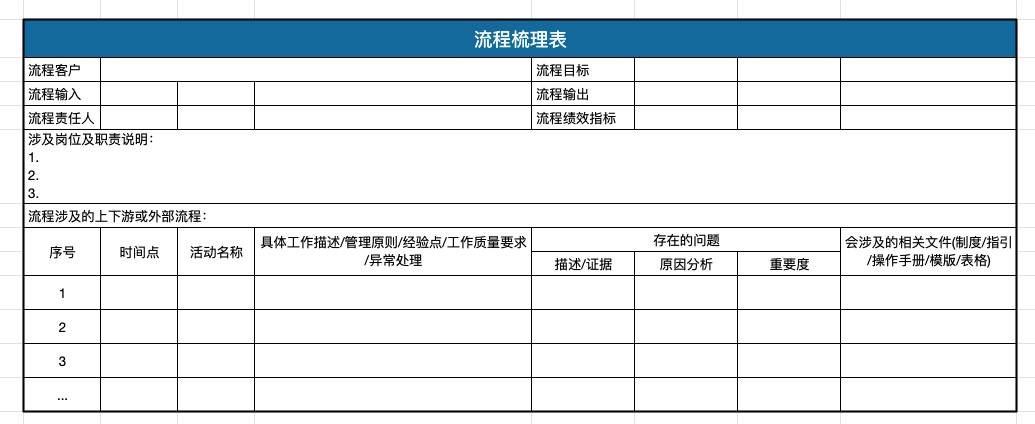
确定流程优化目标,利用工具及业内成熟或公司内部总结的方法论,制定相应措施及改进方案(以下为部分方法,不一定具有普适性,当是笔者个人沉淀)。
流程优化方法:
清除:寻找可清除的等待时间、加工存储、重复、多方协调…等场景,与业务owner、开发leader、项目干系人之间达成共识后清除掉
简化:列出流程中会涉及的表格、程序、沟通、技术、子流程…等因子,研讨后进行简化
整合:整合影响小价值低的流程、组织、团队、顾客等
自动化:对高度重复无特殊场景的乏味工作、无效职责、数据采集、数据传递、数据分析…等从产品角度考虑自动化方案。
流程改进方案示例:
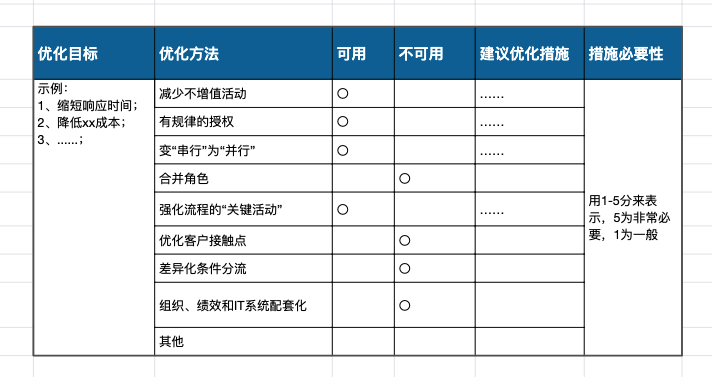
以上方法方案,根据各企业内部存在的具体问题,仅可作为参考之一。
3.3 第3步:确定流程的起点和终点
实际上在产品设计过程中,调研盘点业务流程时,我也经常感到棘手的是找到流程最源头的起点,这是一个很模糊很容走偏的过程,例如说我们讲报销流程,报销流程的起点是什么?有的朋友可能认为是提交报销申请,流程则开始。也有人可能认为起点是我为公司付了钱,所以要申请报销。
而笔者认为,报销流程的起点在于企业颁布了某些应该由企业进行支付的但为了灵活性让员工暂时代付的费用类型之后,想对这个应付兑现的过程进行规范管理。这个规范管理的共识形成落地之后,就称之为报销流程,而这个流程的源头,也可以被称之为流程背景或者项目背景。
当然从产品角度来定义,我们肯定以填写报销单提交报销申请这个动作为起点的。
定义流程起点
《费用报销流程》流程起点是“填写报销单”;
《端到端合同交付流程》流程起点是 “接收客户合同”。
定义流程终点
《费用报销流程》流程终点是“报销凭证生成存档”;
《端到端合同交付流程》流程终点是 “客户验收确认”。
3.4 第4步:分步骤绘制流程图——通过5个维度准确描述具体流程
纬度:
活动:流程中的行为列表和行为的结果
时间:活动发生的时间/顺序
角色:组织/团队/个人按角色进行活动
数据/文档:流程步骤中涉及的输入、数据、输出文档
工具:每个活动的工具载体,如某个IT系统,某个程序或者某个人纯手动进行
流程图示例:
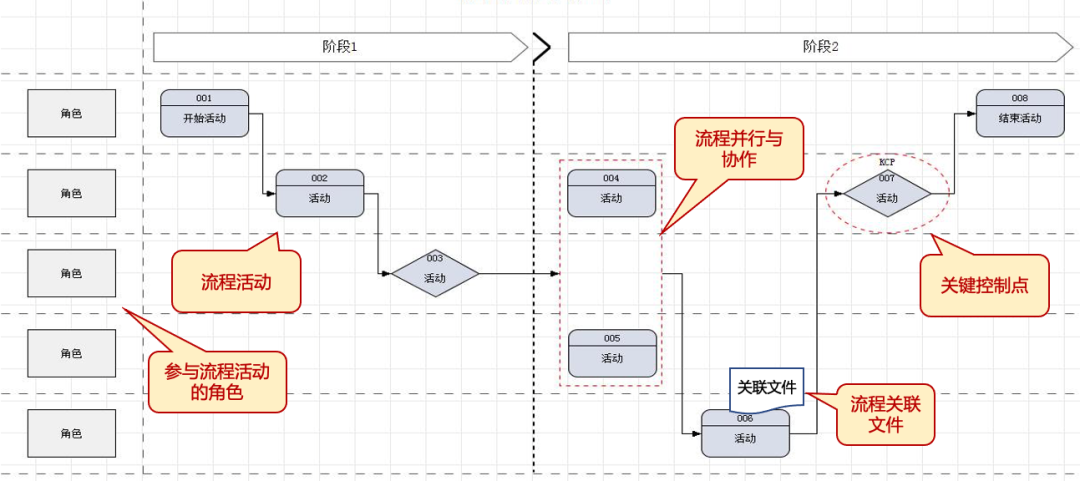
采用横向泳道图的方式绘制;
若存在多个细分场景,且管理流程有较大差异,建议拆分为不同的L5,“流程名称”后以括号说明场景,如供应商认证流程(原材料供应商认证);
不应出现跨多个泳道的活动,若涉及多方参与时,可考虑在泳道上标注出各自的活动,并用联合办公框来说明。
3.5 第5步:编制流程说明——流程说明写作要点
在2.1和2.2大概介绍了一下流程图的核心要素是一张图和一张表,画图大家肯定不陌生,但是编写流程说明表想必就不太清楚了。
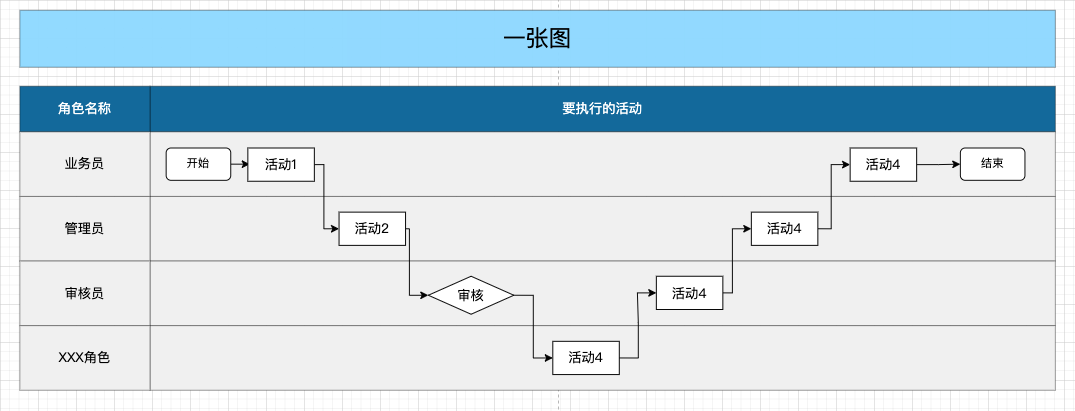
每张流程图我们都可以输出一张下面这样说明表帮助阅读者或团队成员理解,达成共识。
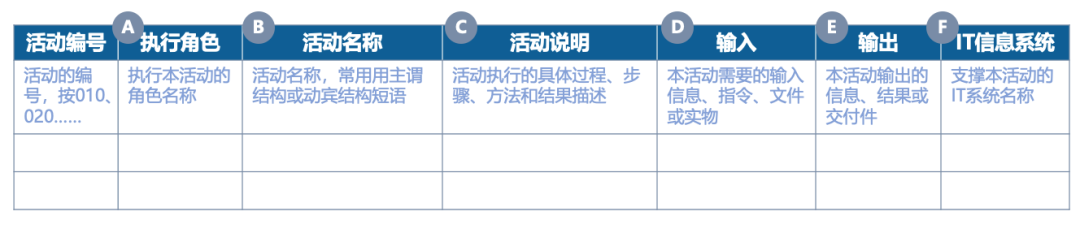
A执行角色:执行该活动的角色,可以是个人/团体/组织,不随业务组织结构变化而变化。
B活动名称:编写时尽量采用动词在前,宾语在后结构,如:“编制XX报告”、“创建XX表单”。
C活动说明:
按照该活动的步骤展开,可以分1. 2. 3. 小节点区分,活动说明的颗粒度以支撑业务运作为原则,澄清关键业务逻辑规则,如:颗粒度要求、特定的模板要求、周期性要求等;
如果一个或多个流程活动有较强的专业作业工序,可以制定该活动的指导书/模板/表单,作为支撑文件
D输入/E输出:
输入、输出物指流程涉及到的信息传递,包括但不限于:工作文档、数据、其他交付件等。
每个活动都需要有输入、输出物,可能是:
实体文档/模板,需要在流程图中标注,并在流程文档中填写;
非实体交付物(如:意见/建议/决策结果等),需要在流程文档中填写
F IT信息系统:指明承载该活动的IT系统名称。
3.6 第6步:检查并完善流程——按需输出支撑表单/模板、指导书
这一步是整个L5流程绘制输出的最后一步,需要对之前已经产出的流程方案、文档进行review。效果最好的方式是产品经理、流程师、业务owner一起评审进行查漏补缺,当然,也要对过程中产生的需要额外的指导文件、政策说明进行支撑的地方进行补充,如果这些支撑性的文件较多,可以列出相应的表单,落实责任人及交付日期。
流程表单:
流程表单是流程过程中产生或者使用到的文件、表单等。流程表单在业务流程图中需要明确标识,并作为流程文件的支撑性L6补充文件,按需对填写要求及规则进行说明。例如:
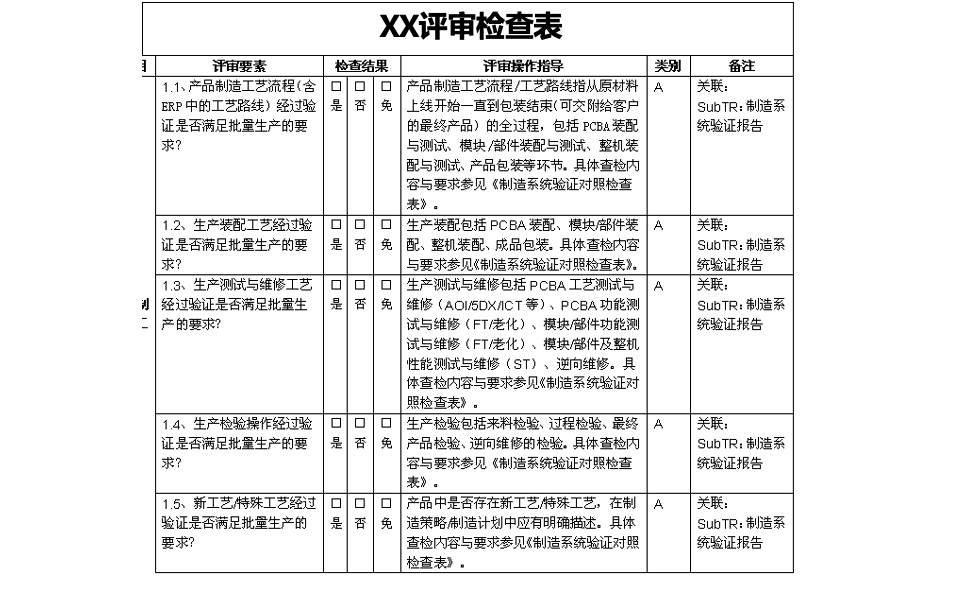

检查流程逻辑、完整性、书写规范等:
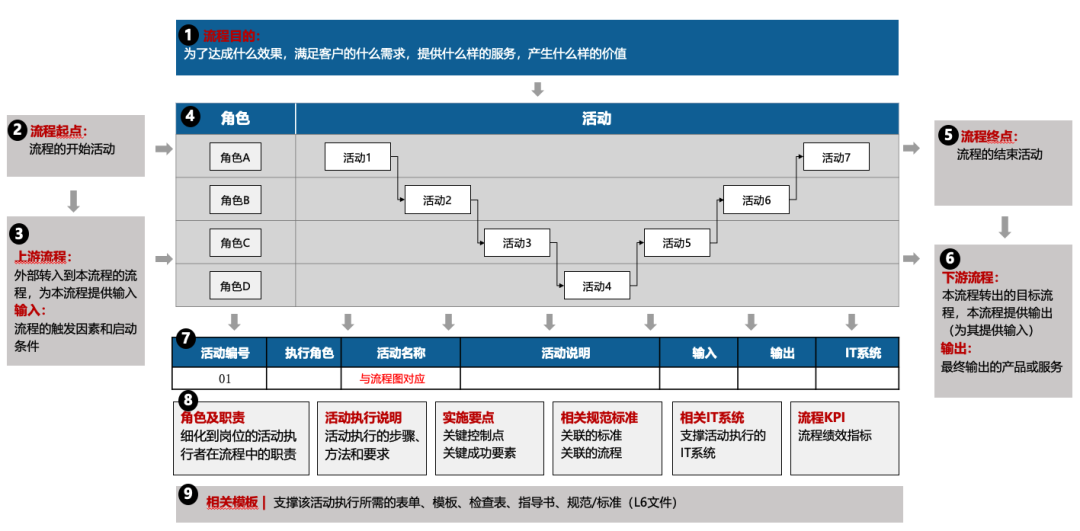
在最终的检查中,可以着重按照图中标注的9个点来进行复盘:
流程目的:为了达成什么效果(降低退货率、提高客服咨询满意度等),满足客户的什么需求(电子合同签单、减少残次率等),提供什么样的服务,产生什么样的价值;
流程的起点:从哪个节点开始,这个流程启动,由x部门x人员负责;
上游流程/输入:外部转入到本流程的流程,为本流程提供输入。例如,库存上架流程的上游流程/输入为采购入库(或者退货入库流程,转移入库流程),员工人事变动流程的上游流程/输入为绩效评估或综合素质评估流程;
流程图:说明整个流程中的参与角色、涉及阶段、活动节点、串联关系的可视化设计;
流程终点:从哪个节点开始,这个流程结束,不再由x部门x人员负责;
下游流程:本流程转出的目标流程,本流程提供输出(为其提供输入),例如订单处理流程的下游流程为发运流程,员工晋升流程的下游流程为薪酬变动流程;
流程图说明文档:对流程图进行文字说明,需讲明在流程图中的每个因子的底层逻辑;
相关要求:整体流程方案的相关要求是否达标
相关模版:支撑该活动执行所需的表单、模板、检查表、指导书、规范/标准(L6文件)
以上就是笔者个人梳理的整个L5流程输出过程,仅代表个人观点,供参考。
4、L5梳理项目管理:明确优先级、责任人,制定L5输出WBS计划
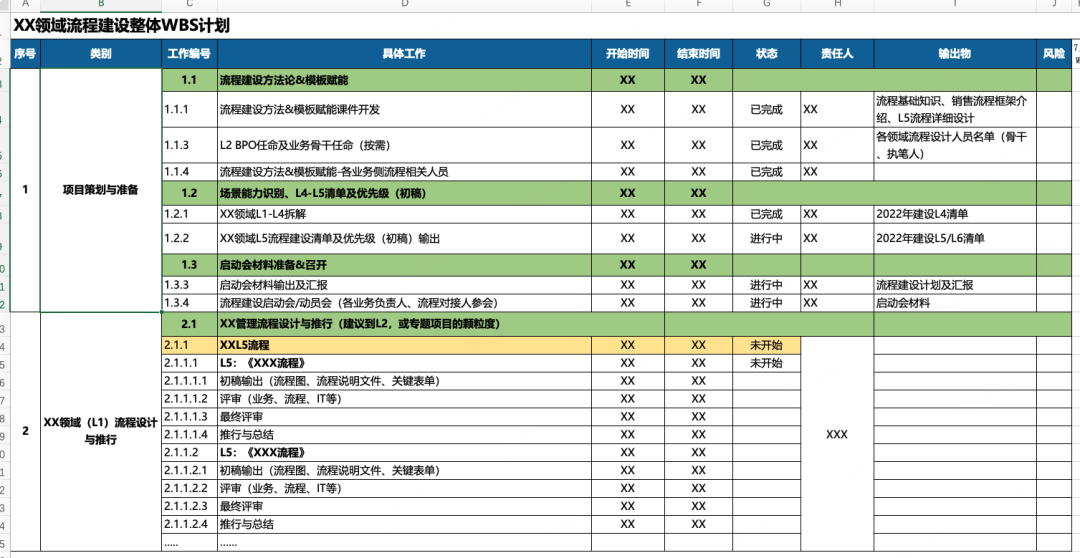
根据以往做L5流程的经验来看,有明确WBS计划,和没有明确WBS计划的工作效率,大概相差在3-4倍,所以在业务活动启动之前,先制作计划,再按图索骥的找到对应责任人进行分发,是非常关键的开门锤之一。当然,这个世界上不会有做的完美的项目,再充足的准备,再谨慎的计划都会面临各种各样的问题,以下是在流程梳理中,笔者总结的还算是比较常见的问题,仅供各位参考:
5、总结
以上所有内容相对来说比较严格,因为笔者杂糅了华为内部的标准,ibm流传出来的标准,以及一些质量管理范围内的标准,这些东西分开来看都具有相当高的价值,但是笔者很难验证杂糅在一起后其价值是否起到了正向增长,至少确实在工作实践中,在梳理业务流程时,这样的标准和方法给我带来了很大的助力,并且为企业也留下了非常宝贵的经验和相关标准文档。
此外,我建立了各大城市的产品交流群,想进群小伙伴加微信:chanpin626 我拉你进群。(加过微信:chanpin628或yw5201a1的别加,分享内容一样,有一个号就行)

视频号推荐
关注微信公众号:产品刘 可领取大礼包一份。

··················END··················

今日报告:奇安信 发布《2024中国软件供应链安全分析报告》,下载报告去公众号:硬核刘大 后台回复“软件供应链安全”,即可下载完整PDF文件。
申明:报告版权归 奇安信 独家所有,此处仅限分享学习使用,如有侵权,请联系小编做删除处理。
RECOMMEND
推荐阅读

点击“阅读原文”
查看更多干货


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









