









引言
何为大矩阵?Excel、SPSS,甚至SAS处理不了或者处理起来非常困难,需要设计巧妙的分布式方法才能高效解决基本运算(如转置、加法、乘法、求逆)的矩阵,我们认为其可被称为大矩阵。这意味着此种矩阵的维度至少是百万级的、经常是千万级的、有时是亿万级的。举个形象的栗子。至2012年12月底,新浪微博注册用户数超5亿,日活跃用户4629万[1],如果我们要探索这4000多万用户可以分成哪些类别,以便深入了解用户共同特征,制定精准营销策略,势必要用到聚类相关的算法(比如新浪大牛张俊林就利用聚类算法来挖掘新浪微博中的兴趣圈子[2]),而聚类算法都需要构造用户两两之间的关系,形成n*n的矩阵,称为相似度矩阵。新浪微博这个例子中,这个矩阵的维度是4000万*4000万。
大矩阵乘法为何重要?这个时代(我就不说那个被媒体用烂了的恶心词汇了),在海量数据中淘金,已是各大互联网公司的既定目标,亚马逊是数据化运营的成功典范,Google、百度投巨资用于对海量数据进行深度学习(Deep Learning)研究,阿里把数据与平台、金融并列成为未来三大战略。话扯得有点大而远,但任何伟大的战略,最终都要落地到非常细粒度的具体操作上。我们想在海量数据中淘到金子,强大的挖掘工具是必不可少的,而诸如回归、聚类、主成分分析、决策树等数据挖掘算法常常涉及大规模矩阵运算。这其中,大矩阵乘法具有较大的时间消耗,是算法的瓶颈。张俊林的文章[2]用到了谱聚类算法,其中有个重要步骤是将相似度矩阵转换为拉普拉斯矩阵,这就需要用到大矩阵乘法。很酷有没有!大矩阵乘法运算可以从根基上影响数据战略的实施,它比那些大而空的废话重要千百万倍。
我们将使用MapReduce来分布式计算大矩阵乘法。伟大导师黑格尔告诉我们,量变导致质变。当所操作的矩阵维度达到百万、千万级时,会产生亟待攻克的新问题:
- 大矩阵如何存储?
- 计算模型如何设计?
- 矩阵维度如何传递给乘法运算?
第3个问题看似与矩阵的“大”无关,但实际上,当矩阵规模巨大时,我们就不太可能像对待小规模矩阵一样将整个矩阵读入内存、从而在一个job中就判断出其维度,而是需要分开成为两个job,第一个job专注于计算矩阵维度并存入全局变量,传递给第二个job做乘法运算。MapReduce中全局变量的传递,可以专门写一篇长文来讨论,本文中我们假定矩阵维度已知,并在代码中写死,从而先着眼于解决前两个问题。
数据准备
为了方便说明,举两个矩阵作为示例:
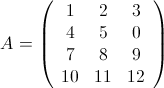 ,
,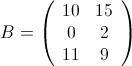
容易看出,
![]() 是一个
是一个 矩阵,
矩阵,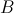 是一个
是一个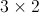 矩阵,我们能够算出:
矩阵,我们能够算出:
矩阵,是一个矩阵,我们能够算出:
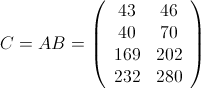
这三个矩阵当然不大,但作为示例,它们将暂时享受大矩阵的待遇。
存储方式
理论上,在一个文件中存储4000万*4000万的矩阵当然是可以的,但非常失之优雅,因为这意味着在一条记录中挤下4000万个变量的值。
我们注意到,根据海量数据构造的矩阵,往往是极其稀疏的。比如4000万*4000万的相似度矩阵,一般来说,如果平均每个用户和1万个用户具有大于零的相似度,常识告诉我们,这样的关系网络已经非常密集了(实际网络不会这样密集,看看自己的微博,被你关注的、评论过的、转发过的对象,会达到1万个吗?);但对于4000万维度的矩阵,它却依然是极度稀疏的。
因此,我们可以采用稀疏矩阵的存储方式,只存储那些非零的数值。具体而言,存储矩阵的文件每一条记录的结构如下:
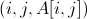
其中,第一个字段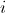 为行标签,第二个字段
为行标签,第二个字段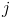 为列标签,第三个字段值为
为列标签,第三个字段值为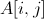 。
。
为行标签,第二个字段为列标签,第三个字段值为。
比如矩阵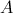 在HDFS中存储为
在HDFS中存储为
在HDFS中存储为
1 1 1
1 2 2
1 3 3
2 1 4
2 2 5
3 1 7
3 2 8
3 3 9
4 1 10
4 2 11
4 3 12
1 2 2
1 3 3
2 1 4
2 2 5
3 1 7
3 2 8
3 3 9
4 1 10
4 2 11
4 3 12
矩阵 存储为
存储为
存储为
1 1 10
1 2 15
2 2 2
3 1 11
3 2 9
1 2 15
2 2 2
3 1 11
3 2 9
注意到![]()
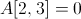 ,
,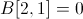 ,这样的值不会在文件中存储。
,这样的值不会在文件中存储。
,,这样的值不会在文件中存储。
计算模型
回顾一下矩阵乘法。
设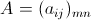 ,
,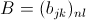 ,那么
,那么
,,那么
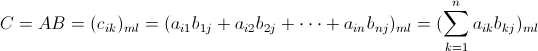
矩阵乘法要求左矩阵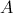 的列数与右矩阵
的列数与右矩阵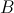 的行数相等,
的行数相等,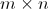 的矩阵
的矩阵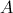 ,与
,与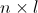 的矩阵
的矩阵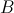 相乘,结果为
相乘,结果为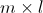 的矩阵
的矩阵 。
。
的列数与右矩阵的行数相等,的矩阵,与的矩阵相乘,结果为的矩阵。
现在我们来分析一下,哪些操作是相互独立的(从而可以进行分布式计算)。很显然,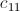 的计算和
的计算和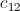 的计算是互不干扰的;事实上,
的计算是互不干扰的;事实上,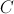 中各个元素的计算都是相互独立的。这样,我们在Map阶段,可以把计算
中各个元素的计算都是相互独立的。这样,我们在Map阶段,可以把计算 所需要的元素都集中到同一个key中,然后,在Reduce阶段就可以从中解析出各个元素来计算
所需要的元素都集中到同一个key中,然后,在Reduce阶段就可以从中解析出各个元素来计算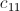 ;
;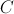 的其他元素的计算同理。
的其他元素的计算同理。
的计算和的计算是互不干扰的;事实上,中各个元素的计算都是相互独立的。这样,我们在Map阶段,可以把计算所需要的元素都集中到同一个key中,然后,在Reduce阶段就可以从中解析出各个元素来计算;的其他元素的计算同理。
我们还需要注意,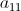 会被
会被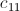 、
、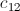 ……
……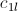 的计算所使用,
的计算所使用,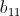 会被
会被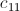 、
、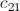 ……
……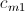 的计算所使用。也就是说,在Map阶段,当我们从HDFS取出一行记录时,如果该记录是
的计算所使用。也就是说,在Map阶段,当我们从HDFS取出一行记录时,如果该记录是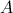 的元素,则需要存储成
的元素,则需要存储成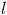 个<key, value>对,并且这
个<key, value>对,并且这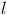 个key互不相同;如果该记录是
个key互不相同;如果该记录是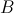 的元素,则需要存储成
的元素,则需要存储成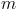 个<key, value>对,同样的,
个<key, value>对,同样的,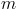 个key也应互不相同;但同时,用于计算
个key也应互不相同;但同时,用于计算 的、存放
的、存放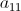 、
、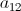 ……
……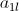 和
和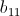 、
、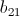 ……
……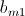 的<key, value>对的key应该都是相同的,这样才能被传递到同一个Reduce中。
的<key, value>对的key应该都是相同的,这样才能被传递到同一个Reduce中。
会被、……的计算所使用,会被、……的计算所使用。也就是说,在Map阶段,当我们从HDFS取出一行记录时,如果该记录是的元素,则需要存储成个<key, value>对,并且这个key互不相同;如果该记录是的元素,则需要存储成个<key, value>对,同样的,个key也应互不相同;但同时,用于计算的、存放、……和、……的<key, value>对的key应该都是相同的,这样才能被传递到同一个Reduce中。
经过以上分析,整个计算过程设计为:
(1)在Map阶段,把来自表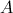 的元素
的元素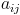 ,标识成
,标识成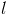 条<key, value>的形式。其中
条<key, value>的形式。其中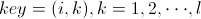 ,
,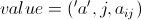 ;把来自表
;把来自表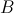 的元素
的元素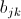 ,标识成
,标识成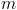 条<key, value>形式,其中
条<key, value>形式,其中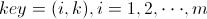 ,
,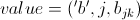 。
。
的元素,标识成条<key, value>的形式。其中,;把来自表的元素,标识成条<key, value>形式,其中,。
于是乎,在Map阶段,我们实现了这样的战术目的:通过key,我们把参与计算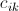 的数据归为一类。通过value,我们能区分元素是来自
的数据归为一类。通过value,我们能区分元素是来自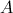 还是
还是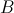 ,以及具体的位置。
,以及具体的位置。
的数据归为一类。通过value,我们能区分元素是来自还是,以及具体的位置。
(2)在Shuffle阶段,相同key的value会被加入到同一个列表中,形成<key, list(value)>对,传递给Reduce,这个由Hadoop自动完成。
(3)在Reduce阶段,有两个问题需要自己问问:
- 当前的<key, list(value)>对是为了计算
的哪个元素?
- list中的每个value是来自表
或表
的哪个位置?
第一个问题可以从key中获知,因为我们在Map阶段已经将key构造为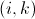 形式。第二个问题,也可以在value中直接读出,因为我们也在Map阶段做了标志。
形式。第二个问题,也可以在value中直接读出,因为我们也在Map阶段做了标志。
形式。第二个问题,也可以在value中直接读出,因为我们也在Map阶段做了标志。
接下来我们所要做的,就是把list(value)解析出来,来自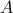 的元素,单独放在一个数组中,来自
的元素,单独放在一个数组中,来自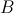 的元素,放在另一个数组中,然后,我们计算两个数组(各自看成一个向量)的点积,即可算出
的元素,放在另一个数组中,然后,我们计算两个数组(各自看成一个向量)的点积,即可算出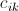 的值。
的值。
的元素,单独放在一个数组中,来自的元素,放在另一个数组中,然后,我们计算两个数组(各自看成一个向量)的点积,即可算出的值。
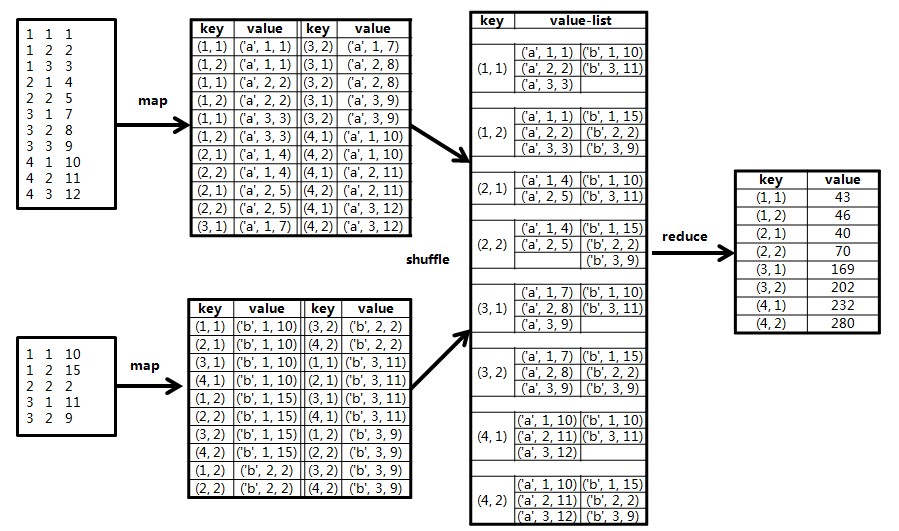
示例矩阵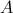 和
和 相乘的计算过程如下图所示:
相乘的计算过程如下图所示:
和相乘的计算过程如下图所示:
代码
主要代码如下:

上帝惊叹细节。















 1110
1110

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









